一眼看懂
封面预览
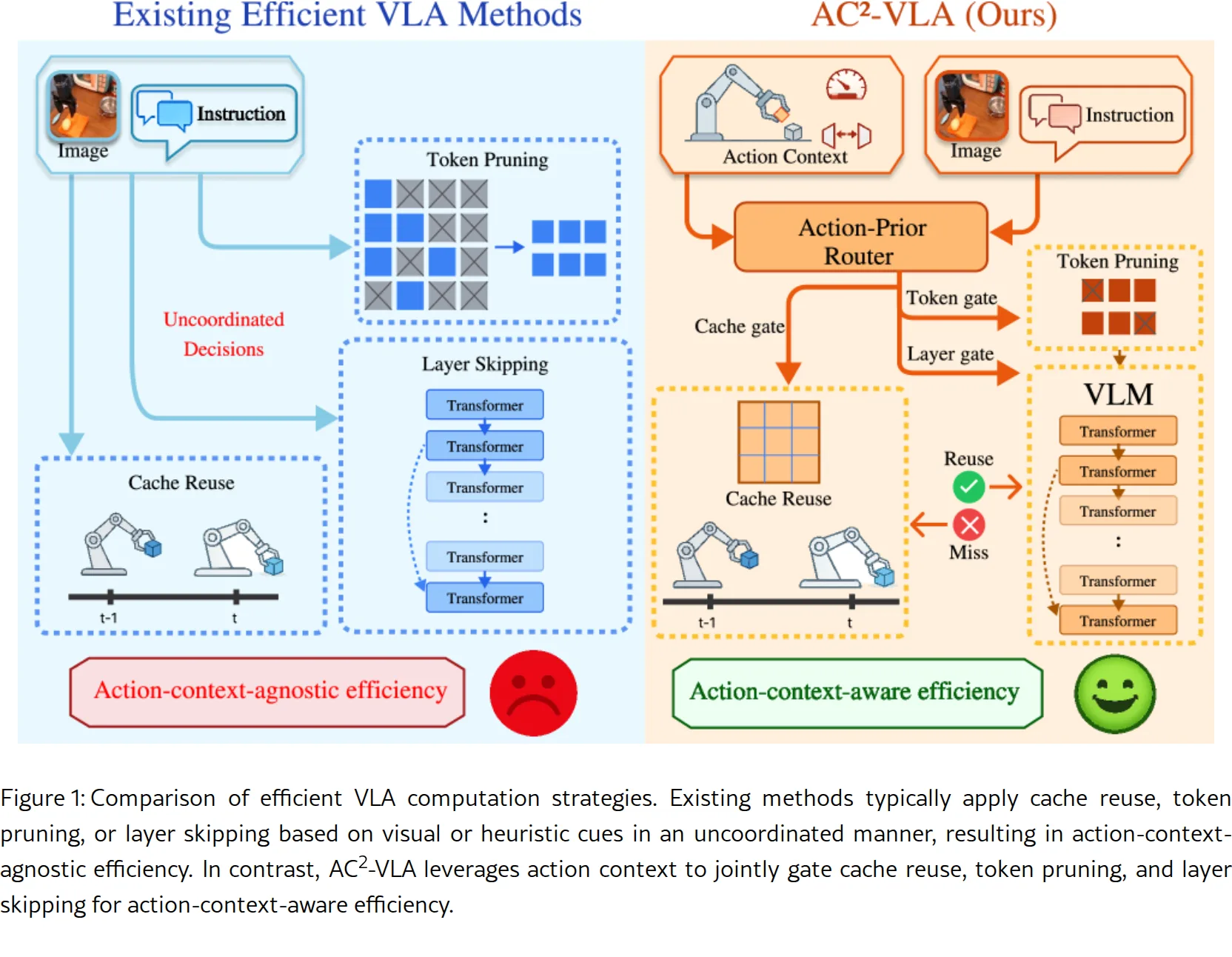
AC²-VLA 是一种面向视觉-语言-动作(VLA)模型的高效推理框架,旨在解决机器人操作任务中 VLA 模型因重复运行大型多模态骨干网络而产…
- AC²-VLA 是一种面向视觉-语言-动作(VLA)模型的高效推理框架,旨在解决机器人操作任务中 VLA 模型因重复运行大型多模态骨干网络而产…
- 论文核心洞察:VLA 推理在时间、空间和深度维度上存在结构化冗余,且现有方法忽略了动作上下文(action context)在计算分配中的关键…
- 研究目标:引入动作上下文感知的自适应计算机制,在保持任务成功率的同时显著降低推理延迟和 FLOPs
Card 01
研究单位
研究单位
- 同济大学(Tongji University)
- 悉尼科技大学(University of Technology Sydney)
- 电子科技大学(University of Electronic Science and Technology of China)
Card 02
论文概述
论文概述
- AC²-VLA 是一种面向视觉-语言-动作(VLA)模型的高效推理框架,旨在解决机器人操作任务中 VLA 模型因重复运行大型多模态骨干网络而产生的高延迟和高计算成本问题
- 论文核心洞察:VLA 推理在时间、空间和深度维度上存在结构化冗余,且现有方法忽略了动作上下文(action context)在计算分配中的关键作用
- 研究目标:引入动作上下文感知的自适应计算机制,在保持任务成功率的同时显著降低推理延迟和 FLOPs
Card 03
核心贡献
核心贡献
- 发现动作上下文与计算冗余的强相关性,提出基于动作上下文感知的 VLA 自适应计算方法
- 设计动作先验路由器(Action-Prior Router),统一协调认知缓存复用、Token 剪枝和条件层跳过三种机制
- 提出动作引导的自蒸馏训练方案,在保持原始密集策略行为的同时实现结构化稀疏化
- 在 SIMPLER 基准上实现 1.79 倍加速,FLOPs 降至 29.4%,成功率与密集基线相当
Card 04
方法描述
方法描述
- 动作先验路由器:以当前观察、语言指令和前一时刻动作状态为条件,生成统一的计算门控策略
- 三维度自适应计算:
- 时间维度(认知缓存复用):基于动作-状态匹配复用跨时间步的骨干特征
- 空间维度(Token 剪枝):动作条件匹配去除当前操作阶段无关的视觉 Token
- 深度维度(层跳过):根据动作上下文条件性执行 Transformer 层
- RoPE 对齐的 Token 压缩:保持位置编码一致性
- 动作引导自蒸馏:教师-学生架构,动作输出和认知特征双重蒸馏
Card 05
数据集与资源
数据集与资源
- 数据集:Open X-Embodiment(Bridge 子集)、SIMPLER 模拟基准
- 模型基座:CogACT(Prismatic-7B 视觉-语言骨干 + DiT-Base 动作头)
- 训练配置:3000 步、批量大小 48、学习率 1×10⁻⁶、8 步扩散推理
- 硬件:NVIDIA RTX 5090 GPU
Card 06
评估与结果
评估与结果
- 评估基准:SIMPLER(Google Robot 和 WidowX 机器人)
- 主要指标:任务成功率(↑)、加速比(↑)、FLOPs(↓)
- 关键结果:
- Google Robot Visual Matching:76.8% 平均成功率,1.79× 加速,FLOPs 降至 29.4%
- WidowX Visual Matching:54.5% 平均成功率
- Variant Aggregation:61.6% 平均成功率,1.67× 加速
- 消融实验:三个组件(缓存、Token 剪枝、层路由)均有互补收益,全模型达到最佳速度-精度权衡