一眼看懂
封面预览
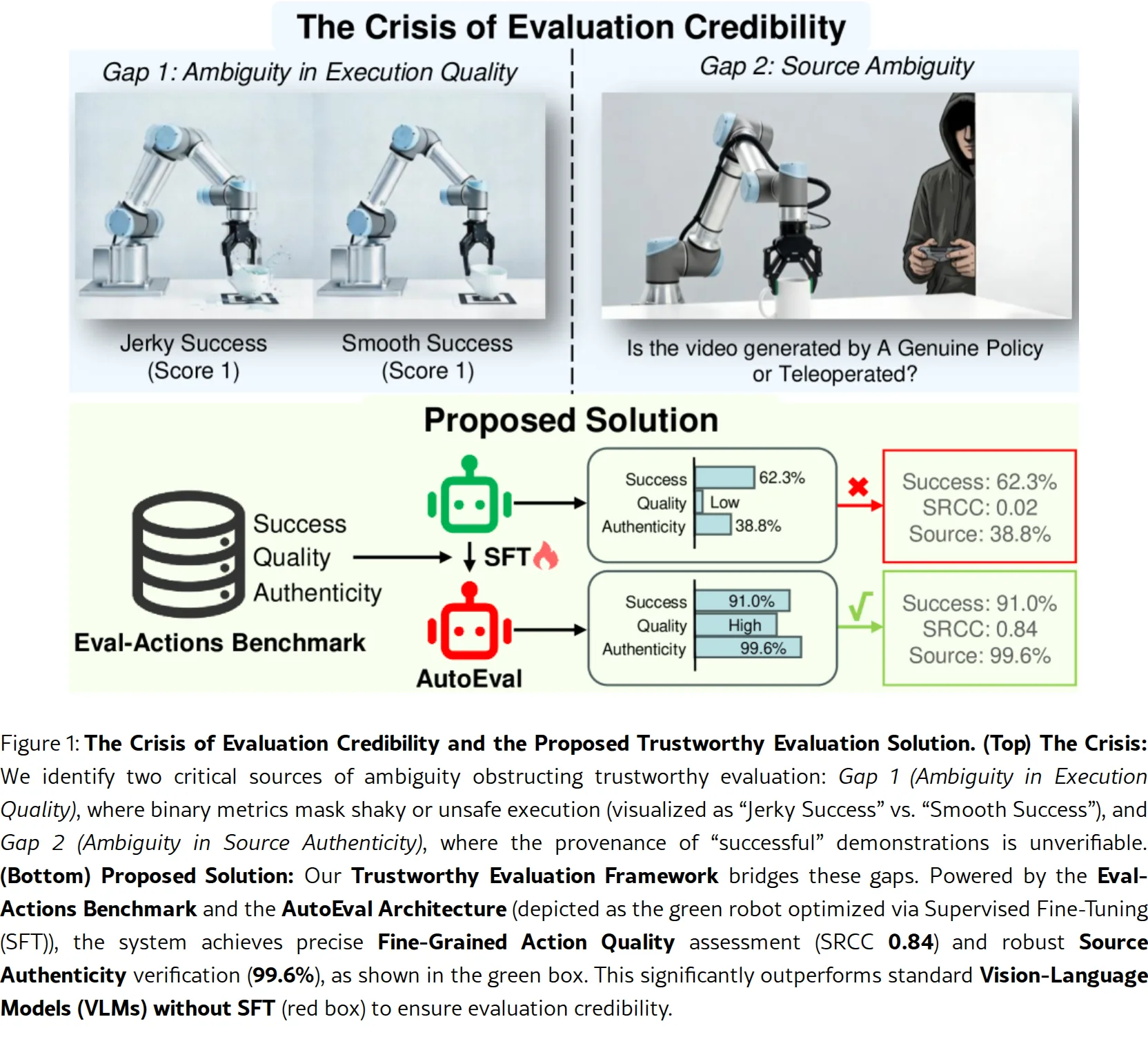
论文针对机器人操作领域评估方法滞后的问题,提出可信评估框架,旨在同时验证执行质量(如平滑性、安全性、效率)和来源真实性(区分策略生成轨迹与人类…
- 论文针对机器人操作领域评估方法滞后的问题,提出可信评估框架,旨在同时验证执行质量(如平滑性、安全性、效率)和来源真实性(区分策略生成轨迹与人类…
- 当前评估主要依赖二元成功率(成功/失败),无法区分"抖动成功"与"平滑成功",也无法验证"成功演示"是来自真正的自主策略还是隐藏的人类远程操作
- 解决方案包括:Eval-Actions 基准数据集(首个为评估完整性设计的数据集)和 AutoEval 评估架构(基于 VLM 的自动化评估框…
Card 01
研究单位
研究单位
- 论文作者信息显示来自中国,作者包括 Mengyuan Liu、Juyi Sheng(通讯作者)、Peiming Li、Ziyi Wang、Tianming Xu、Tiantian Xu、Hong Liu(通讯作者)
- 通讯邮箱显示为 tsinghua.edu.cn 域名,推测为清华大学
- 项目主页:https://term-bench.github.io/
Card 02
论文概述
论文概述
- 论文针对机器人操作领域评估方法滞后的问题,提出可信评估框架,旨在同时验证执行质量(如平滑性、安全性、效率)和来源真实性(区分策略生成轨迹与人类远程操作轨迹)
- 当前评估主要依赖二元成功率(成功/失败),无法区分"抖动成功"与"平滑成功",也无法验证"成功演示"是来自真正的自主策略还是隐藏的人类远程操作
- 解决方案包括:Eval-Actions 基准数据集(首个为评估完整性设计的数据集)和 AutoEval 评估架构(基于 VLM 的自动化评估框架)
Card 03
核心贡献
核心贡献
- 建立可信评估标准:将评估从二元结果转向细粒度行为诊断,量化平滑性、安全性和效率,解决低质量执行被误认为稳健成功的模糊性问题
- 引入 Eval-Actions 基准:首个评估导向数据集,集成失败场景(2.8k)和混合轨迹来源(策略 vs 人类),支持 Expert Grading (EG)、Rank-Guided (RG) 和 Chain-of-Thought (CoT) 三种监督信号
- 提出 AutoEval 框架:通过时空聚合策略实现 SOTA 评分(SRCC 0.84),利用 GRPO 范式增强物理推理能力,最关键的是实现了高达 99.6% 的来源真实性验证精度
Card 04
方法描述
方法描述
- Rank-Guided Weight Optimization:使用遗传算法(GA)优化运动学指标的权重,将自动评估与人类专家判断对齐,生成可靠的 GT 标注
- AutoEval-S:针对 EG 和 RG 任务,采用时空聚合策略将高频运动细节压缩到固定 token 预算中,引入 Kinematic Calibration Signal(辅助运动学校准信号)补偿视频压缩伪影
- AutoEval-P:针对 CoT 推理,采用 Group Relative Policy Optimization (GRPO) 范式,结合混合奖励函数(内容准确性 + 格式约束)增强物理推理能力,减少语言幻觉
- 任务形式化:将动作质量评估、成功检测、来源分类统一为条件文本生成任务
Card 05
数据集与资源
数据集与资源
- Eval-Actions 数据集:约 52 小时操作视频,包含 13,000+ 演示 episode,覆盖 150+ 任务(包括单臂和双臂协作场景)
- 失败场景:2.8k 失败轨迹(约占 37.4%),与成功执行混合
- 数据来源:20 名人类操作员(工程师、学生、非专家)+ 多种 VA 和 VLA 策略生成轨迹
- 标注类型:Expert Grading (EG)、Rank-Guided preferences (RG)、Chain-of-Thought (CoT) 三种监督信号
- 实验子集 EAS:每个样本包含腕部视角、头部视角、第三人称视角同步录制,以及 7-DoF 关节角度和末端执行器状态
- 基础模型:使用 SmolVLM2-2.2B、QwenVL2.5-3B、QwenVL3-4B、InternVL3.5-4B 进行微调
Card 06
评估与结果
评估与结果
- 评估环境:在 Eval-Actions Small (EAS) 子集上进行实验,平衡数据分布
- 主要评估指标:SRCC(Spearman 等级相关系数)、Rₗ₂(相对 L2 误差)、Accuracy、F1-Score、AUC
- 关键实验结果:
- Expert Grading (EG):AutoEval-S 达到 SRCC 0.81,成功预测 Accuracy 90.6%,来源预测 Accuracy 99.1%
- Rank-Guided (RG):AutoEval-S 达到 SRCC 0.84(最优),来源预测 Accuracy 99.6%(最优)
- Chain-of-Thought (CoT):AutoEval-P 达到 SRCC 0.70
- 零样本基线对比:未微调的 VLM(如 InternVL3.5-4B)SRCC 接近 0,证明微调 pipeline 的必要性
- 结论:AutoEval 在细粒度动作质量评估和来源真实性验证方面均达到领先性能,为机器人评估建立了严格的透明标准