一眼看懂
封面预览
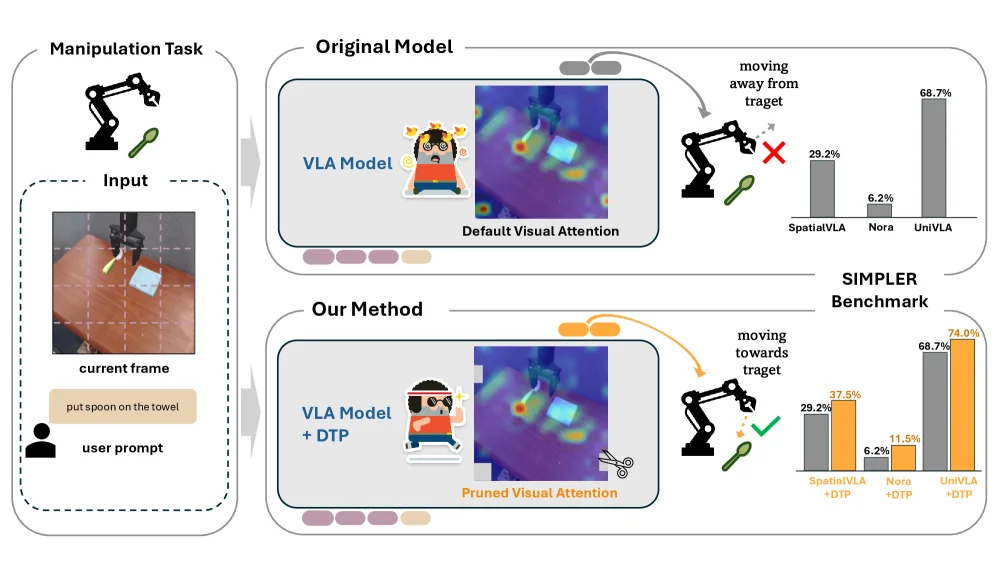
提出 Distracting Token Pruning (DTP) 框架,用于解决视觉-语言-动作(VLA)模型过度关注任务无关视觉标记("…
- 提出 Distracting Token Pruning (DTP) 框架,用于解决视觉-语言-动作(VLA)模型过度关注任务无关视觉标记("…
- 通过动态检测和剪枝干扰标记,纠正模型的视觉注意力模式,从而提高任务成功率
- 作为即插即用的推理时方法,无需修改模型架构或添加额外输入
Card 01
研究单位
研究单位
- Chenyang Li: Australian National University
- Jieyuan Liu: University of California, San Diego
- Bin Li: Chinese Academy of Sciences
- Bo Gao: Beijing Institute of Graphic Communication
- Yilin Yuan: Beijing Institute of Graphic Communication
- Yangfan He: University of North Carolina at Chapel Hill
- Yuchen Li: Baidu Search
- Jingqun Tang: Bytedance
Card 02
论文概述
论文概述
- 提出 Distracting Token Pruning (DTP) 框架,用于解决视觉-语言-动作(VLA)模型过度关注任务无关视觉标记("干扰标记")的问题
- 通过动态检测和剪枝干扰标记,纠正模型的视觉注意力模式,从而提高任务成功率
- 作为即插即用的推理时方法,无需修改模型架构或添加额外输入
Card 03
核心贡献
核心贡献
- 引入 DTP 框架:一种基于交集的方法,自动识别并剪枝干扰标记,通过解决 VLA 模型常见的注意力弱点来提高任务成功率
- 探索性能上界:通过调整容忍度参数 τ,探索 VLA 模型在其原有架构下可达到的性能上界,寻求与模型偏好对齐的理想视觉注意力模式
- 揭示负相关关系:分析不重要区域的注意力值,发现其与任务成功率呈负相关,为构建更稳健的 VLA 模型提供见解
- 跨模型泛化能力:在多种基于 Transformer 的 VLA 模型(SpatialVLA、Nora、UniVLA)上验证了方法的有效性
Card 04
方法描述
方法描述
- 重要区域构建:利用选定层的注意力矩阵计算提示标记与图像标记之间的相关性得分,通过余弦相似度或注意力权重聚合形成相关性热图,选取 top-k 最高相关性的视觉标记构成重要区域
- 视觉注意力模式构建:为每个生成的动作标记提取对所有视觉标记的注意力权重,按各层视觉注意力的比例加权,聚合得到最终的视觉注意力模式
- 干扰标记剪枝:对于不重要区域中的视觉标记,若其注意力值超过重要区域最大注意力值与容忍度 τ 的乘积,则判定为干扰标记并将其剪枝
Card 05
数据集与资源
数据集与资源
- 评估基准:SIMPLER Benchmark( WidowX 机器人任务、Google 机器人任务)、LIBERO Benchmark
- 测试模型:SpatialVLA(3B,基于 PaliGemma 2)、Nora(基于 Qwen2.5-VL-3B)、UniVLA(9B 世界模型)
- 训练资源:推理时方法,无需额外训练资源
Card 06
评估与结果
评估与结果
- WidowX 任务:SpatialVLA 从 29.2% 提升至 37.5%(相对提升 128.4%),Nora 从 6.2% 提升至 11.5%(约 2 倍),UniVLA 从 68.7% 提升至 74.0%(相对提升 107.7%)
- Google 机器人任务:SpatialVLA 相对提升 1-3%,Nora 相对提升 2-3%
- LIBERO 基准:Nora 在所有套件上均获提升,LIBERO-10 绝对提升 +6.6%
- 关键发现:任务失败 episodes 在不重要区域的注意力始终高于成功 episodes(p<0.001),且差异在动作执行中期最为显著