一眼看懂
封面预览
提出 SigEnt-SAC,一种从零开始学习的离策略 Actor-Critic 方法,仅需一条专家轨迹即可实现高效学习
- 提出 SigEnt-SAC,一种从零开始学习的离策略 Actor-Critic 方法,仅需一条专家轨迹即可实现高效学习
- 解决真实世界机器人强化学习的三大核心挑战:样本效率低、稀疏奖励和视觉观测噪声
- 核心设计:使用 Sigmoid 有界熵机制防止负熵驱动的优化走向分布外(OOD)动作,并减少 Q 函数振荡
Card 01
研究单位
研究单位
- 武汉大学 (Wuhan University)
- Xiefeng Wu, Mingyu Hu, Shu Zhang
Card 02
论文概述
论文概述
- 提出 SigEnt-SAC,一种从零开始学习的离策略 Actor-Critic 方法,仅需一条专家轨迹即可实现高效学习
- 解决真实世界机器人强化学习的三大核心挑战:样本效率低、稀疏奖励和视觉观测噪声
- 核心设计:使用 Sigmoid 有界熵机制防止负熵驱动的优化走向分布外(OOD)动作,并减少 Q 函数振荡
Card 03
核心贡献
核心贡献
- 单次演示高效性:在 one-shot 设置下,比现有离线到在线基线方法更快达到 100% 任务成功率
- 单目视觉控制:支持仅从单目 egocentric 相机流进行控制,在动态环境中仍能稳定收敛
- 跨构型泛化能力:在不同物理构型的机器人上验证成功,包括人形机器人、四足机器人和自主移动机器人
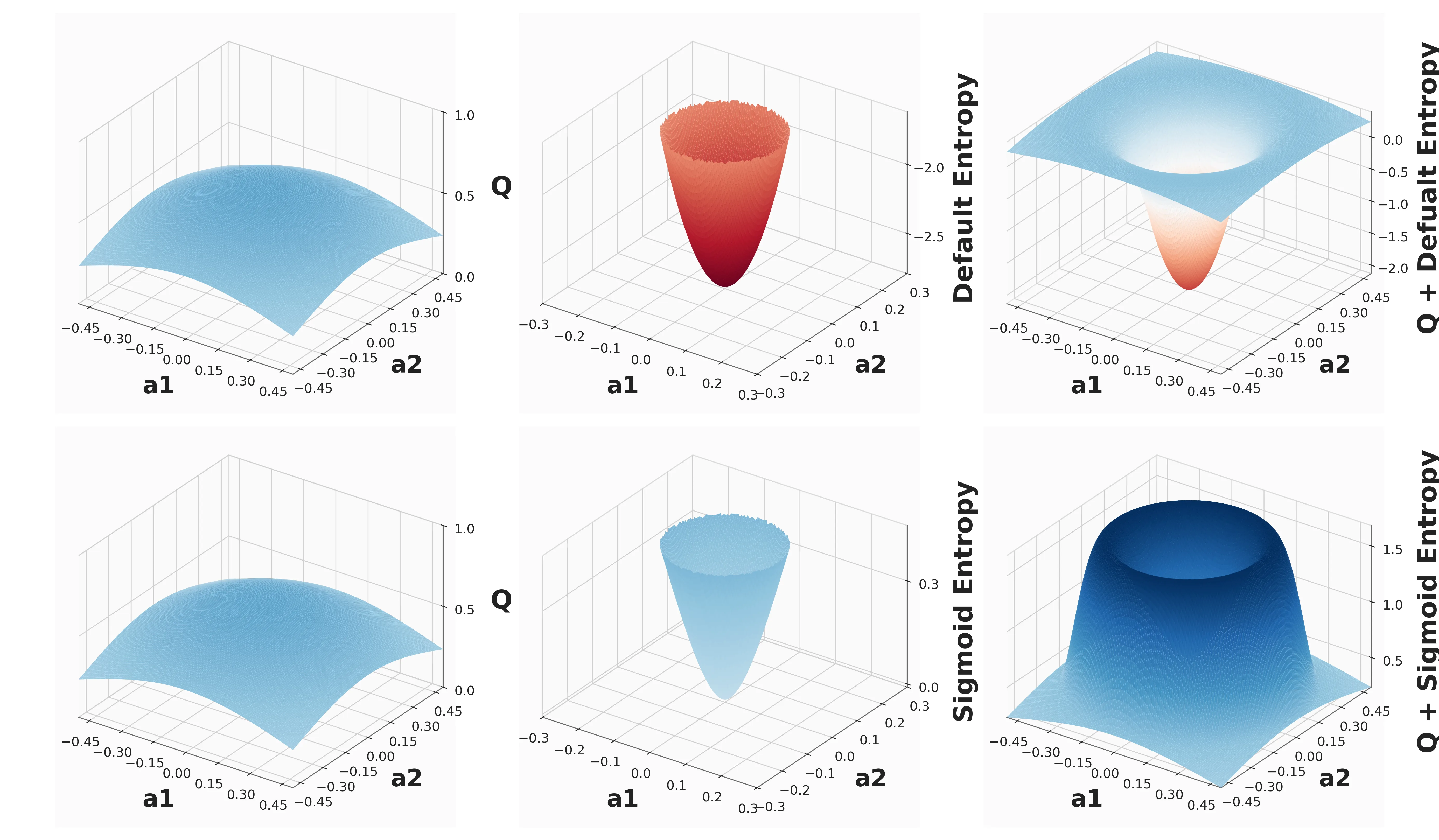
- 创新性 Sigmoid 有界熵:通过 sigmoid 函数将每维惊异度映射为有界、正范围的熵信号,消除策略过度优化
- 门控行为克隆(GBC):仅对偏离专家样本显著的动作进行惩罚,稳定策略优化并减少无效探索
Card 04
方法描述
方法描述
- Sigmoid-Bounded Entropy:对 tanh 压缩的高斯策略,将每维负对数密度(惊异度)通过 sigmoid 函数变换为有界熵贡献:$h_i(s_i)=h_{max} \cdot \sigma(\frac{s_i - m}{t})$
- Gated Behavior Cloning:引入基于偏差的门控机制,仅当策略均值动作与专家动作偏差超过阈值 $\varepsilon$ 时激活行为克隆损失
- 保守 Q 学习正则化:添加 CQL 风格正则化项,抑制采样 OOD 动作上的虚假高 Q 值
- 算法框架:在标准 SAC 基础上整合有界熵和门控行为克隆,使用双 Q 网络和目标网络
Card 05
数据集与资源
数据集与资源
- 模拟数据集:D4RL Adroit 和 Kitchen 基准测试
- 真实机器人任务:
- Push-Cube(机械臂操作)
- Ball-to-goal(轮式机器人)
- Slalom(四足机器 Unitree Go2)
- Slalom(人形机器人 Unitree G1)
- 观测方式:单目灰度图像,纯视觉观测,无全局状态估计
- 演示数据:每任务仅需一条成功轨迹
- 模型参数量:约 0.091M 参数
- 训练开销:3.13 ms/update(与其他方法可比)
Card 06
评估与结果
评估与结果
- 模拟环境评估:
- 在 one-shot 设置下比其他基线更快达到 100% 成功率
- 对噪声演示(50%丢弃、动作噪声、状态噪声)具有更强的鲁棒性
- 真实世界评估(4 个任务,10 次评估):
- Push-Cube:100% 成功率
- Ball-Driving:100% 成功率
- Slalom (Go2):100% 成功率
- Slalom (G1):100% 成功率
- 相比基线 BC(30 次演示)和 VLM 零样本具有显著优势
- 性能提升:学到的策略比演示平均减少 40.9% 任务完成时间(Ball-to-goal 任务减少 88.46%)
- 超参数敏感性:GBC 权重 $\lambda$ 和门控阈值 $\varepsilon$ 存在较宽的稳定区间,易于调优