一眼看懂
封面预览
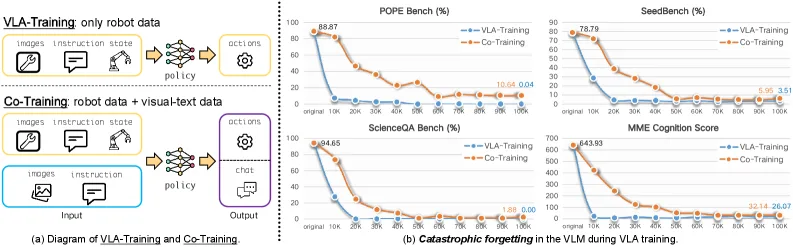
研究目标:解决 VLA(视觉-语言-动作)模型在机器人微调过程中出现的灾难性遗忘问题,期望利用预训练 VLM 的通用语义能力来增强具身智能的性…
- 研究目标:解决 VLA(视觉-语言-动作)模型在机器人微调过程中出现的灾难性遗忘问题,期望利用预训练 VLM 的通用语义能力来增强具身智能的性…
- 核心问题:标准 VLA 训练会破坏 VLM 预训练的特征空间,导致模型丧失通用的视觉理解能力,这与 VLA 范式的初衷相悖。
- 提出方法:TwinBrainVLA,一种非对称双流架构,通过冻结的"左脑"(通用模型)和可训练的"右脑"(专用模型)协同工作,结合非对称混合…
Card 01
研究单位
研究单位
- HIT (哈尔滨工业大学)
- ZGCA (中关村 Academy)
- ZGCI
- HUST (华中科技大学)
- HKUST(GZ) (香港科技大学(广州))
- BUAA (北京航空航天大学)
- ECNU (华东师范大学)
- CASIA (中国科学院自动化研究所)
- DeepCybo
Card 02
论文概述
论文概述
- 研究目标:解决 VLA(视觉-语言-动作)模型在机器人微调过程中出现的灾难性遗忘问题,期望利用预训练 VLM 的通用语义能力来增强具身智能的性能。
- 核心问题:标准 VLA 训练会破坏 VLM 预训练的特征空间,导致模型丧失通用的视觉理解能力,这与 VLA 范式的初衷相悖。
- 提出方法:TwinBrainVLA,一种非对称双流架构,通过冻结的"左脑"(通用模型)和可训练的"右脑"(专用模型)协同工作,结合非对称混合 Transformer(AsyMoT)机制,使右脑能够动态查询左脑的语义知识。
Card 03
核心贡献
核心贡献
- 定量分析了 VLA 训练对 VLM 通用能力造成的灾难性遗忘现象
- 提出 TwinBrainVLA 架构,从结构上解耦语义理解与具身控制
- 引入 AsyMoT(非对称混合 Transformer)机制,实现左右脑之间的高效信息交互
- 在 SimplerEnv、RoboCasa、LIBERO 基准及真实机器人实验中验证了方法的有效性
Card 04
方法描述
方法描述
- 非对称双 VLM 主干:左脑(冻结)保留预训练的通用视觉语言能力;右脑(可训练)专注于处理本体感觉状态和生成动作
- AsyMoT 机制:右脑通过因果自注意力动态查询左脑的 Key-Value 对,实现语义知识的迁移而不发生遗忘
- 动作专家:使用 Flow-Matching 扩散模型(DiT)基于右脑的表示生成连续动作轨迹
- 训练策略:仅使用机器人动作损失进行训练,左脑参数完全冻结
Card 05
数据集与资源
数据集与资源
- 训练数据:Open X-Embodiment (OXE) 数据集的子集,包括 Bridge-V2、Fractal 等
- 评估基准:SimplerEnv、RoboCasa (GR1 Tabletop)、LIBERO
- 模型规模:基于 Qwen2.5-VL-3B-Instruct 和 Qwen3-VL-4B-Instruct 构建
- 训练资源:16 × NVIDIA H100 GPUs
Card 06
评估与结果
评估与结果
- SimplerEnv (OOD):TwinBrainVLA + Qwen3-VL-4B 达到 64.5% 平均成功率,超越最强基线 Isaac-GR00T-N1.6 (57.1%) +7.4%
- RoboCasa:达到 54.6% 平均成功率,超越 Isaac-GR00T-N1.6 (47.6%) +7.0%
- LIBERO:达到 97.6% 平均成功率
- 真实机器人实验:在域内、域外和长程任务中均表现优异,域外泛化达到 15/30 成功率
- 消融实验:验证了冻结策略和 AsyMoT 交互频率的重要性