论文提出 GeRo (Generative Scenario Rollouts),一个用于视觉-语言-动作 (VLA) 模型的即插即用框架,将…
- 论文提出 GeRo (Generative Scenario Rollouts),一个用于视觉-语言-动作 (VLA) 模型的即插即用框架,将…
- 通过自回归场景展开策略,联合执行规划与语言引导的未来交通场景生成,解决当前 VLA 模型依赖稀疏轨迹标注、未充分利用生成能力的问题
- 旨在提升自动驾驶系统在复杂动态环境中的长时程推理、多智能体规划和语言-动作对齐能力
研究单位
- Qualcomm AI Research (高通人工智能研究)
- Qualcomm Technologies, Inc. (高通技术公司)
论文概述
- 论文提出 GeRo (Generative Scenario Rollouts),一个用于视觉-语言-动作 (VLA) 模型的即插即用框架,将场景生成与端到端自动驾驶的运动规划统一起来
- 通过自回归场景展开策略,联合执行规划与语言引导的未来交通场景生成,解决当前 VLA 模型依赖稀疏轨迹标注、未充分利用生成能力的问题
- 旨在提升自动驾驶系统在复杂动态环境中的长时程推理、多智能体规划和语言-动作对齐能力
核心贡献
- 首次将场景生成与运动预测、规划、视觉问答联合进行,提出 GeRo 生成式场景展开框架
- 设计基于 GRPO (Generalized Rollout Policy Optimization) 的新型奖励函数,联合优化轨迹精度与语言描述的语义对齐,包含碰撞避免、时间到碰撞 (TTC) 等安全关键指标
- 引入交互式视觉问答 (VQA) 组件,将自车意图用自然语言进行 grounding,支持复杂驾驶环境中的语言引导推理
- 提出 rollout 一致性损失,通过 KL 散度对齐预测分布与预训练潜在分布,缓解自回归生成的漂移问题
方法描述
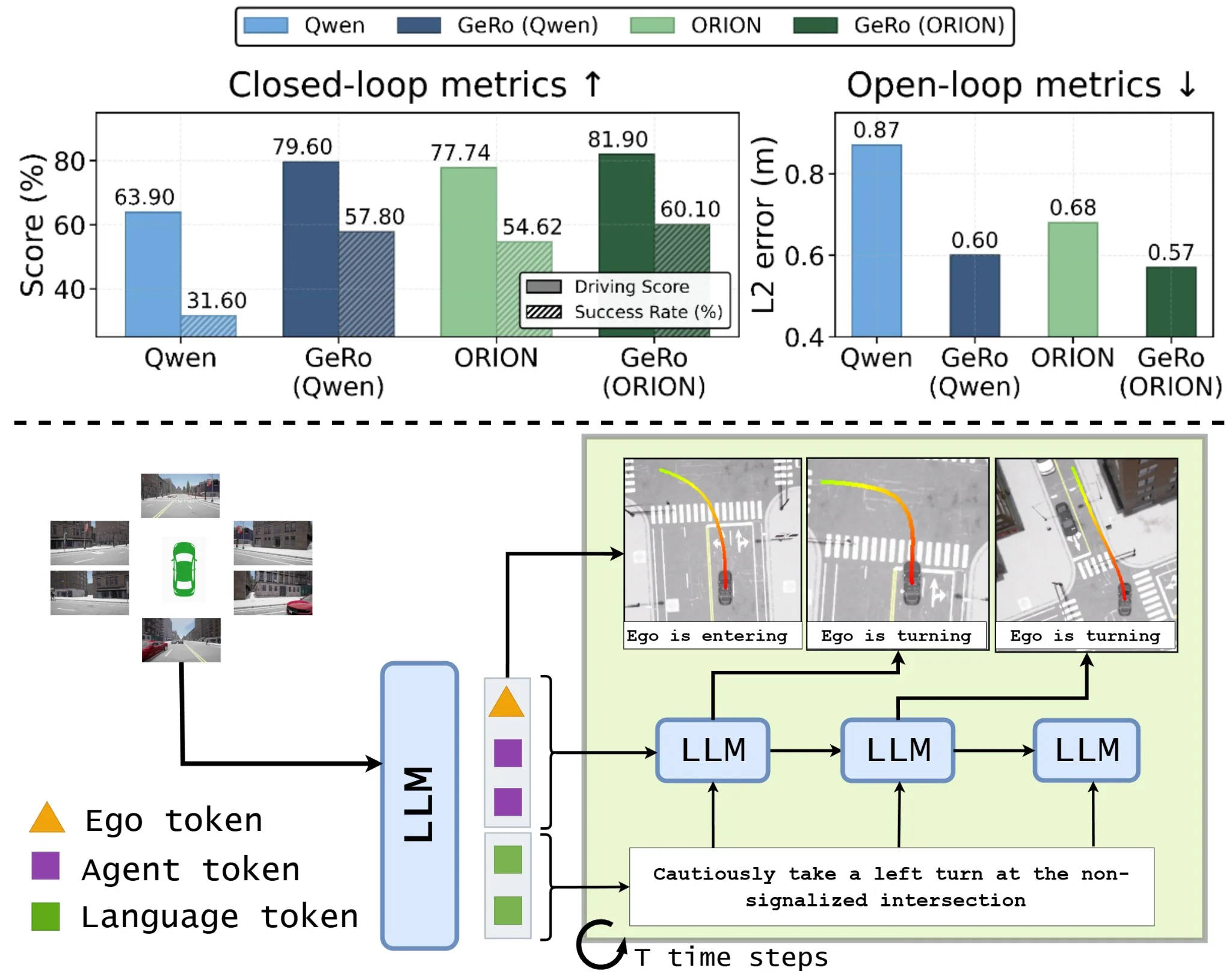
- 两阶段训练框架:
- 预训练阶段:VLA 模型学习将自车和智能体动态编码为紧凑的共享 token 空间,联合监督规划、多智能体运动预测和视觉问答任务
- 场景展开阶段:基于语言条件的自回归生成,预测未来潜在 token 和自车动作描述,通过反馈循环指导长时程推理
- 关键技术:
- 使用 VAE (变分自编码器) 作为生成式规划头,将 LLM 输出转换为轨迹分布
- Rollout 一致性损失:结合真实标签监督与基于预训练模型的伪标签监督,通过 KL 散度强制时序一致性
- GRPO 强化学习:在场景展开中引入可微替代奖励,包括碰撞损失、TTC 惩罚和语言预测准确率
数据集与资源
- 数据集:
- Bench2Drive:基于 CARLA 的闭环端到端自动驾驶基准,1000 个片段(950 训练/50 验证),220 条测试路线覆盖 44 种交互场景
- nuScenes:开环规划基准,28,000 个样本(22k/6k 训练/验证划分)
- ChatB2D / DriveLM-nuScenes:用于场景描述和视觉问答的语言标注
- 模型架构:
- GeRo (Qwen):基于 Qwen2.5VL-3B 多模态大语言模型
- GeRo (ORION):基于 ORION VLA 模型
- 视觉编码器:EVA 预训练 ViT
- 训练资源:8 张 NVIDIA H100 GPU
- 训练设置:预训练 24 epoch,场景展开训练 24 epoch,学习率 2×10⁻⁴,使用 AdamW 优化器和余弦退火调度
评估与结果
- 评估基准:Bench2Drive(闭环)、nuScenes(开环)
- 主要评估指标:
- 闭环:Driving Score (DS)、Success Rate (SR)、效率、舒适度、多能力指标(并道、超车、紧急制动、让行、交通标志)
- 开环:L2 轨迹误差、碰撞率
- 关键实验结果:
- Bench2Drive 闭环:GeRo (Qwen) 相比基线 Qwen2.5VL,DS 提升 +15.7(63.9→79.6),SR 提升 +26.2%(31.6%→57.8%);GeRo (ORION) 相比 ORION 基线,DS 提升 +4.16(77.74→81.90),SR 提升 +5.5%(54.62%→60.10%)
- 多能力指标:GeRo (Qwen) 平均能力提升 140%(25.6→61.98),GeRo (ORION) 提升 26.7%(54.72→66.49),在并道、超车、紧急制动等关键技能上均有显著改进
- nuScenes 开环:GeRo (Qwen) L2 误差降低 67.7%(0.96→0.31),碰撞率降低 76.7%(0.60→0.14);零样本测试显示强泛化能力