一眼看懂
封面预览
提出 Action Chain-of-Thought (ACoT) 范式,将推理过程建模为动作空间中的结构化序列,而非语言或视觉中介目标
- 提出 Action Chain-of-Thought (ACoT) 范式,将推理过程建模为动作空间中的结构化序列,而非语言或视觉中介目标
- 解决现有 VLA 模型中语义-运动控制之间的差距(semantic-kinematic gap),即高级抽象输入与低级可执行动作指令之间的根本…
- 构建 ACoT-VLA 架构,通过显式和隐式两种动作推理器生成动作空间引导,实现更精准、更稳健的机器人策略学习
Card 01
研究单位
研究单位
- Beihang University (北京航空航天大学)
- AgiBot (阿基机器人)
Card 02
论文概述
论文概述
- 提出 Action Chain-of-Thought (ACoT) 范式,将推理过程建模为动作空间中的结构化序列,而非语言或视觉中介目标
- 解决现有 VLA 模型中语义-运动控制之间的差距(semantic-kinematic gap),即高级抽象输入与低级可执行动作指令之间的根本脱节
- 构建 ACoT-VLA 架构,通过显式和隐式两种动作推理器生成动作空间引导,实现更精准、更稳健的机器人策略学习
Card 03
核心贡献
核心贡献
- 首次提出 Action Chain-of-Thought (ACoT) 范式,将 "思考 "过程重新定义为动作空间中有明确运动学依据的意图链
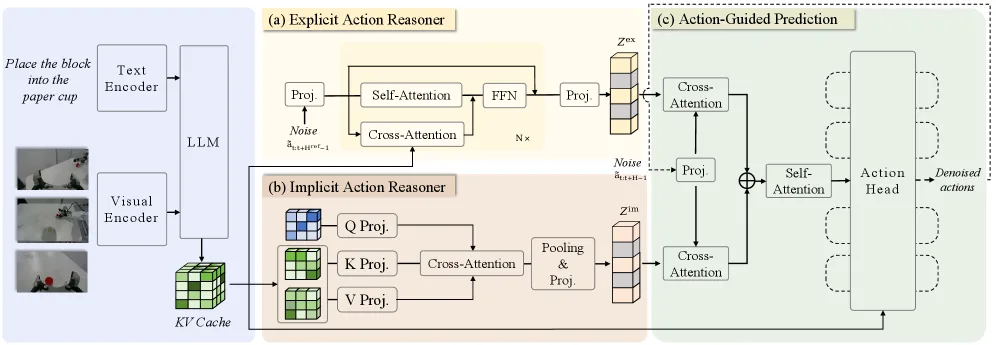
- 设计 显式动作推理器 (Explicit Action Reasoner, EAR):基于轻量级 Transformer,根据多模态观测生成粗粒度参考动作轨迹,提供直接的、可执行的动作空间引导
- 设计 隐式动作推理器 (Implicit Action Reasoner, IAR):通过跨注意力机制从 VLM 内部表示中提取潜在动作先验,提供隐式的行为先验引导
- 提出 动作引导预测 (Action-Guided Prediction, AGP) 策略:通过双重交叉注意力将显式和隐式动作引导有效融合到策略学习中
- 在 LIBERO (98.5%)、LIBERO-Plus (84.1%) 和 VLABench (47.4%) 三个基准数据集上取得领先成果
Card 04
方法描述
方法描述
- 基于 π₀.₅ 架构构建,使用 SigLIP 作为视觉编码器,Gemma 2B 作为 LLM 主干
- 显式动作推理器 (EAR):轻量级 Transformer,输入带噪声的动作序列,通过自注意力和交叉注意力(与 VLM 的 key-value cache 交互)生成去噪的参考动作轨迹
- 隐式动作推理器 (IAR):对 VLM 每层的 key-value 进行下采样,然后使用可学习的 query 通过跨注意力提取隐式动作相关特征,最后聚合多层特征得到隐式动作引导
- 动作引导预测 (AGP):将噪声动作编码为 query,与显式/隐式动作嵌入进行双重交叉注意力,然后通过自注意力融合模块合并两种引导,最终输入动作头预测最终动作序列
- 采用 flow matching 训练目标,使用 Teacher Forcing 策略稳定训练(训练时使用真实参考轨迹,推理时完全自回归)
Card 05
数据集与资源
数据集与资源
- 数据集:LIBERO、LIBERO-Plus、VLABench 官方训练集,以及自采的真实机器人演示数据
- 模型规模:Gemma 2B 主干 (18 层,hidden size 2048),输入图像 resize 到 224×224
- 训练资源:8 张 NVIDIA H100 GPU,bfloat16 精度;推理使用单张 RTX 4090
- 参考动作 horizon:15 步;动作预测 horizon:10 步
- 学习率:余弦退火,峰值 5e-5,10K warmup 步,10K 衰减步
Card 06
评估与结果
评估与结果
- 评估环境:MuJoCo 模拟环境(LIBERO/LIBERO-Plus)和 SAPIEN 模拟环境(VLABench)
- 主要指标:Success Rate (SR),每任务 50 次 rollout 取平均
- LIBERO 基准:Spatial、Object、Goal、Long 四个子集,平均成功率达 98.5%,Rank 1,超越 π₀.₅ (96.9%)
- LIBERO-Plus 基准:7 种分布偏移设置(Camera、Robot、Language、Light、Background、Noise、Layout),平均成功率达 84.1%,Rank 1
- VLABench 基准:5 类分布偏移(In-distribution、Category、Commonsense、Instruction、Texture),IS 和 PS 指标领先
- 消融实验:验证 EAR 和 IAR 各模块的贡献,以及动作空间引导相比语言/视觉引导的优势