一眼看懂
封面预览
提出 Fast-ThinkAct,一种高效的视觉-语言-动作 (VLA) 推理框架,通过可表达潜在规划实现紧凑且高性能的规划能力
- 提出 Fast-ThinkAct,一种高效的视觉-语言-动作 (VLA) 推理框架,通过可表达潜在规划实现紧凑且高性能的规划能力
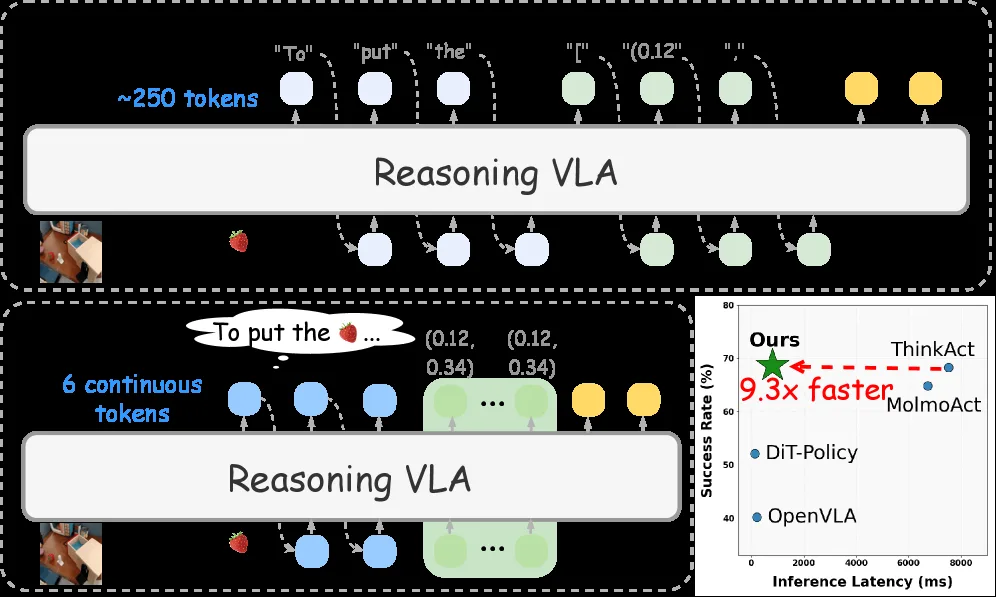
- 解决现有推理 VLA 模型面临的高推理延迟问题——传统方法需要生成冗长的链式思考 (CoT) 文本(约 250 tokens),导致推理速度仅…
- 核心创新:将语言和视觉规划能力压缩到紧凑的连续潜在表示中,同时保持强大的长程规划、少样本适应和失败恢复能力
Card 01
研究单位
研究单位
- NVIDIA
- 卡内基梅隆大学 (Carnegie Mellon University)
- 其他 affiliations 已在论文中标注(具体机构信息需查看原始论文)
Card 02
论文概述
论文概述
- 提出 Fast-ThinkAct,一种高效的视觉-语言-动作 (VLA) 推理框架,通过可表达潜在规划实现紧凑且高性能的规划能力
- 解决现有推理 VLA 模型面临的高推理延迟问题——传统方法需要生成冗长的链式思考 (CoT) 文本(约 250 tokens),导致推理速度仅约 0.1 Hz,无法满足实时机器人操作需求(1-15 Hz)
- 核心创新:将语言和视觉规划能力压缩到紧凑的连续潜在表示中,同时保持强大的长程规划、少样本适应和失败恢复能力
Card 03
核心贡献
核心贡献
- 提出 Fast-ThinkAct 高效推理框架,将推理压缩到可表达的潜在思考中,同时保持表达能力
- 引入基于奖励偏好的偏好蒸馏方法,结合操作轨迹对齐,将语言和视觉规划压缩到紧凑的连续潜在向量
- 通过推理增强策略学习,将高层视觉规划与低层动作执行连接
- 在各类具体化基准测试中实现高达 89.3% 的推理延迟降低,同时保持强大性能
Card 04
方法描述
方法描述
- 师生框架:文本教师模型 $\mathcal{F}_{\theta}^{T}$ 通过 GRPO 训练生成显式推理链,学生模型 $\mathcal{F}_{\theta}$ 将推理蒸馏到紧凑潜在表示
- 可表达潜在 CoT:引入 Verbalizer LLM 将潜在向量解码为文本,基于 DPO 风格的偏好损失 $\mathcal{L}_{verb}$ 引导学生编码高质量推理模式
- 动作对齐视觉规划蒸馏:通过 L2 距离对齐教师和学生 hidden states,传递视觉规划能力;使用空间 tokens 并行预测轨迹路点
- 推理增强策略学习:将学生 VLM 的视觉潜在规划(从空间 tokens 的 KV cache 提取)连接到扩散 Transformer 动作模型(如 RDT、DiT-Policy),通过模仿学习目标训练动作预测
Card 05
数据集与资源
数据集与资源
- VLM backbone: Qwen2.5-VL 3B
- 训练数据: RoboFAC、RoboVQA、ShareRobot、EgoPlan-Bench、Video-R1-CoT、PixMo、OXE(动作数据)、Aloha(双机械臂数据)
- 评估基准:
- 机器人操作: SimplerEnv、LIBERO(包含 Spatial/Object/Goal/Long 子任务)、RoboTwin2.0
- 具体化推理: EgoPlan-Bench2、RoboVQA、OpenEQA、RoboFAC
- 硬件: 16 张 NVIDIA A100 GPU(每张 80GB 内存)
Card 06
评估与结果
评估与结果
- 推理延迟: 相比 ThinkAct-7B 降低 89.3%,相比 MolmoAct-7B 降低 88.0%,比 ThinkAct-3B 快 7 倍
- 机器人操作: 在 LIBERO 和 SimplerEnv 所有子任务中达到最高成功率,优于 OpenVLA、CoT-VLA、ThinkAct、MolmoAct 等基线;在 RoboTwin2.0 双机械臂任务中,Easy 模式下比 RDT 提升 9.3%,Hard 模式下提升 3.6%
- 具体化推理: 在 EgoPlan-Bench2、RoboVQA、OpenEQA 上超越所有对比方法,包括 GPT-4V 和 Gemini-2.5-Flash 等专有模型
- 长程规划: RoboTwin2.0 长程任务(>270 步)中,Easy/Hard 模式分别达到 48.8/16.8,显著超越 RDT 和 ThinkAct
- 失败恢复: RoboFAC 基准上比 RoboFAC-3B 在模拟环境提升 10.9 分,在真实机器人环境提升 16.4 分