一眼看懂
封面预览
提出 VLingNav,一个基于语言驱动的 VLA(视觉-语言-动作)模型,用于具身导航任务,旨在赋予智能机器人认知能力
- 提出 VLingNav,一个基于语言驱动的 VLA(视觉-语言-动作)模型,用于具身导航任务,旨在赋予智能机器人认知能力
- 解决了现有 VLA 模型的局限性:缺乏显式推理机制、持久记忆和可解释性,无法处理复杂的长程导航任务
- 引入自适应思维链机制(AdaCoT)和视觉辅助语言记忆模块(VLingMem),使智能体能够在快速直觉执行和慢速深思熟虑之间灵活切换
Card 01
研究单位
研究单位
- ByteDance Seed(字节跳动 Seed 团队)
- Peking University(北京大学)
- Zhongguancun Academy(中关村 Academy)
Card 02
论文概述
论文概述
- 提出 VLingNav,一个基于语言驱动的 VLA(视觉-语言-动作)模型,用于具身导航任务,旨在赋予智能机器人认知能力
- 解决了现有 VLA 模型的局限性:缺乏显式推理机制、持久记忆和可解释性,无法处理复杂的长程导航任务
- 引入自适应思维链机制(AdaCoT)和视觉辅助语言记忆模块(VLingMem),使智能体能够在快速直觉执行和慢速深思熟虑之间灵活切换
- 构建了 Nav-AdaCoT-2.9M 数据集,这是目前最大的具有推理注释的具身导航数据集,并引入了在线专家引导的强化学习后训练阶段
Card 03
核心贡献
核心贡献
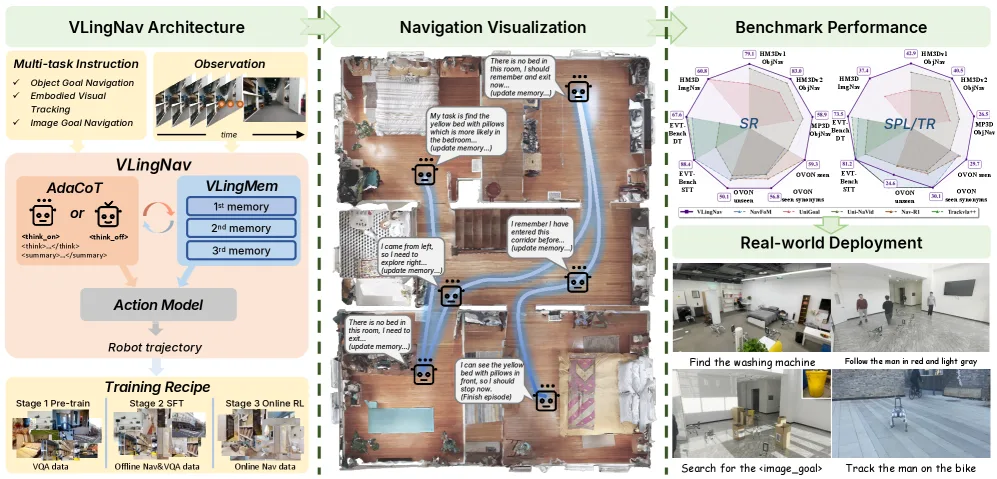
- 提出 VLingNav 框架,集成自适应思维链(AdaCoT)和视觉辅助语言记忆(VLingMem),使智能体能够根据任务复杂性动态切换推理模式,并通过跨模态持久存储消除冗余探索
- 构建 Nav-AdaCoT-2.9M,这是最大的具身导航推理注释数据集,包含 472K 个 CoT 注释样本,涵盖三种导航任务(ObjNav、Track、ImageNav)
- 引入在线专家引导的强化学习后训练阶段,使模型能够超越纯模仿学习的局限性,获得更稳健的自我优化导航行为
- 在多种具身导航基准测试中取得 SOTA 性能,显著提升长程推理和成功率
- 展示了对真实世界机器人平台的 零样本迁移 能力,成功执行未见过的任务,展现出强大的跨域和跨任务泛化能力
Card 04
方法描述
方法描述
- 自适应思维链(AdaCoT):受人类认知双过程理论启发,动态触发显式推理(
或 ),包含推理内容()和环境总结() - 视觉辅助语言记忆(VLingMem):构建持久跨模态语义记忆,使智能体能够回忆过去观察以防止重复探索,并推断动态环境中的运动趋势
- 动态 FPS 采样策略:基于艾宾浩斯遗忘曲线,历史帧根据与当前帧的时间间隔进行采样采样率控制
- 网格池化:对历史观察的特征图进行下采样,根据时间间隔确定下采样比例以控制计算成本
- 时间感知指示符令牌:使用 RoPE 编码时间戳信息,使模型能够感知不同历史帧与当前帧之间的绝对时间间隔
- 动作模型:MLP-based 动作模型基于 VLM 主干的最终令牌预测的隐藏状态来预测运动轨迹
Card 05
数据集与资源
数据集与资源
- Nav-AdaCoT-2.9M:2.9M 步骤级自适应思维链轨迹,包含 718 个场景
- CoT 注释数量:472K 个
- 训练数据组成:2.9M 具身导航数据 + 1.6M 开放世界视频数据(LLaVA-Video-178K、Video-R1、ScanQA)
- 基础模型:LLaVA-Video-7B
- 视觉编码器:SigLIP-400M
- 场景覆盖:HM3D、MP3D
- 任务类型:ObjectNav、EVT(视觉跟踪)、ImageNav
Card 06
评估与结果
评估与结果
- 基准测试:Object Goal Navigation(HM3D、MP3D)、Embodied Visual Tracking(EVT-Bench)、Image Goal Navigation(HM3D)
- 评估指标:成功率(Success Rate)、效率指标
- 主要结果:在多种具身导航基准测试中取得 SOTA 性能,优于现有 VLA 智能体
- 真实世界实验:零样本迁移到真实机器人平台,成功执行未见过的导航任务
- 泛化能力:展示强大的跨域和跨任务泛化能力