论文针对视觉-语言-动作(VLA)模型在语言扰动下的脆弱性问题,提出了一种名为残差语义引导(Residual Semantic Steerin…
- 论文针对视觉-语言-动作(VLA)模型在语言扰动下的脆弱性问题,提出了一种名为残差语义引导(Residual Semantic Steerin…
- 研究的核心问题是"模态崩溃"(modality collapse)现象:即VLA模型中强视觉先验压倒稀疏的语言信号,导致智能体过度依赖特定的指…
- 研究目标是通过解耦物理 affordance 与语义执行,使模型在各种语言扰动下保持鲁棒性
研究单位
- 中山大学(Sun Yat-sen University)
- 广东省大数据分析与处理重点实验室(Guangdong Key Lab of Big Data Analysis & Processing)
- X-Era AI Lab
论文概述
- 论文针对视觉-语言-动作(VLA)模型在语言扰动下的脆弱性问题,提出了一种名为残差语义引导(Residual Semantic Steering, RSS)的probabilistic框架
- 研究的核心问题是"模态崩溃"(modality collapse)现象:即VLA模型中强视觉先验压倒稀疏的语言信号,导致智能体过度依赖特定的指令措辞而忽略底层语义意图
- 研究目标是通过解耦物理 affordance 与语义执行,使模型在各种语言扰动下保持鲁棒性
核心贡献
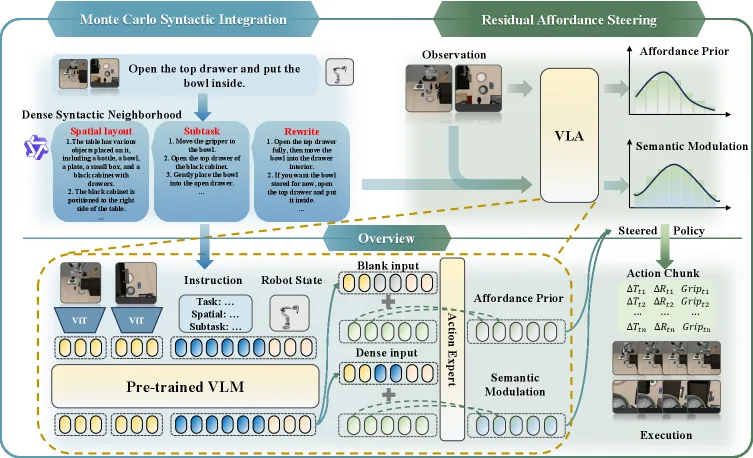
- 残差 Affordance 引导(Residual Affordance Steering, RAS):作为"偏差抑制器",通过从条件logits中减去基础affordance分布(视觉先验),隔离出纯净语义信号,有效恢复语言特征的排名
- 蒙特卡洛句法集成(Monte Carlo Syntactic Integration, MCSI):利用Oracle Teacher(LLM)生成密集的语言邻域,通过优化期望语义损失(Expected Semantic Loss)近似真实语义后验,确保策略对表层句法变化不变
- 理论分析:证明了RSS能有效最大化动作与意图之间的互信息,同时抑制视觉干扰
- State-of-the-art鲁棒性:在多种语言扰动下(包括破坏性指令覆盖、混淆指令重释、分布外语义迁移)取得显著性能提升
方法描述
- RSS框架:包含两个阶段的dual-stage机制
- Monte Carlo Syntactic Integration:使用Qwen2.5-VL作为Oracle Teacher,从原始指令l_orig生成密集邻域N(l_orig)={l₁,...,l_K},优化期望语义损失
- Residual Affordance Steering:计算残差向量Δ_sem = s(a\|o,l) - s(a\|o,∅),其中s(a\|o,∅)是"基础affordance分布",代表仅基于视觉几何的动作概率,最终 steered policy 为:π̃(a\|o,l) ∝ exp(s(a\|o,∅) + γ·Δ_sem)
- 创新点:与标准Classifier-Free Guidance(CFG)不同,RSS作为"偏差抑制器"而非"质量提升器",明确建模并惩罚仅由视觉本能驱动的动作
数据集与资源
- 基准数据集:LIBERO benchmark(包括LIBERO-Spatial、LIBERO-Object、LIBERO-Goal、LIBERO-10四个任务类别)
- 基线模型:π₀ 和 π₀.5(Vision-Language-Action Flow Model)
- 骨干网络:基于Gemma的预训练视觉语言模型
- Oracle Teacher:Qwen2.5-VL用于训练时生成语言邻域;ChatGPT-5.2用于评估时重写指令
- 训练配置:30,000步,batch size 32,余弦学习率衰减(峰值5×10⁻⁵),10,000步warm-up,EMA decay 0.999
- 评估硬件:单张NVIDIA RTX 3090 GPU
评估与结果
- 评估场景:
- 破坏性指令覆盖(Destructive Instruction Overwriting):Blank、Simple、Multi、Rand、Mask等扰动
- 混淆指令重释(Obfuscated Instruction Reinterpretation):R0-R4五种变体(Multiword Substitution、Distraction、Common Sense、Reasoning Chain、Confusion)
- 分布外语义迁移(Out-of-distribution Semantic Transfer):10/100/1000-shot adaptation
- 主要结果:
- 在π₀上:RSS组合将平均成功率从52.37%提升至82.22%(+29.85%)
- 在π₀.5上:RSS组合将平均成功率从75.90%提升至86.98%(+11.08%)
- 在混淆指令重释任务中,RSS显著提升了模型对复杂语义变化的鲁棒性
- 消融实验表明适度 steering coefficient(γ>1)可提升鲁棒性,但过大则导致性能下降