一眼看懂
封面预览
论文系统地审计了多个广泛使用的 Vision-Language-Action(VLA)数据集,旨在表征这些数据集包含的指令类型及其语言多样性程度
- 论文系统地审计了多个广泛使用的 Vision-Language-Action(VLA)数据集,旨在表征这些数据集包含的指令类型及其语言多样性程度
- 研究发现当前 VLA 数据集依赖高度重复的模板化命令,结构变化有限,导致指令形式分布狭窄——不到 2% 的指令是独特的
- 论文将发现定位为对当前 VLA 训练和评估数据中语言信号的描述性文档,旨在支持更详细的数据集报告、更原则性的数据集选择,以及扩大语言覆盖的针对…
Card 01
研究单位
研究单位
- Los Alamos National Laboratory(美国洛杉矶阿拉莫斯国家实验室)- Selma Wanna、Ryan Barron、Juston Moore
- University of Tartu(爱沙尼亚塔尔图大学计算机科学研究所)- Agnes Luhtaru
- The University of Texas at Austin(德克萨斯大学奥斯汀分校机械工程系)- Jonathan Salfity、Mitch Pryor
- University of Maryland, Baltimore County(马里兰大学巴尔的摩县分校)- Cynthia Matuszek
Card 02
论文概述
论文概述
- 论文系统地审计了多个广泛使用的 Vision-Language-Action(VLA)数据集,旨在表征这些数据集包含的指令类型及其语言多样性程度
- 研究发现当前 VLA 数据集依赖高度重复的模板化命令,结构变化有限,导致指令形式分布狭窄——不到 2% 的指令是独特的
- 论文将发现定位为对当前 VLA 训练和评估数据中语言信号的描述性文档,旨在支持更详细的数据集报告、更原则性的数据集选择,以及扩大语言覆盖的针对性策划或增强策略
Card 03
核心贡献
核心贡献
- 首次对 VLA 数据集的语言多样性进行系统性分析
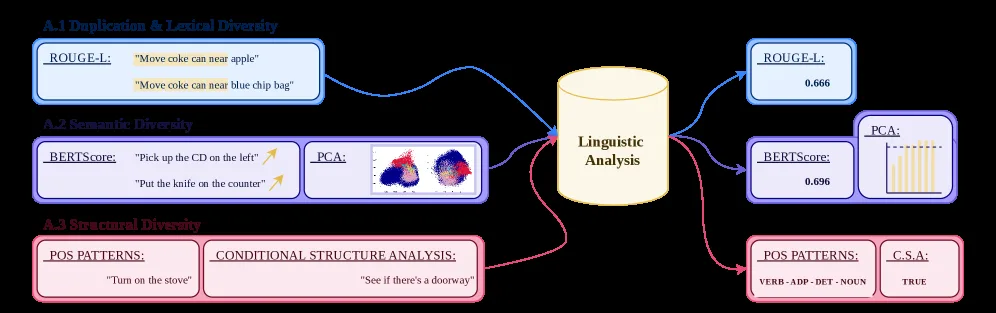
- 从三个维度量化指令语言:词汇冗余与多样性、语义多样性和结构多样性
- 发现 VLA 数据集词汇多样性极低(如 RT-1 仅包含 49 个独特词汇)
- 发现缺乏复杂的语言结构——否定语和条件句均不到 1%,多步指令占主导但句法模式高度重复
- 提供全面的多维度评估指标,包括 BLEU、ROUGE-L、压缩比、BERTscore、POS 模式、树核相似度等
Card 04
方法描述
方法描述
- 分析了 Open X-Embodiment(OXE) 集合中的主流 VLA 数据集,并与其他机器人和指令调优数据集进行比较
- 三个分析维度:
- A.1 词汇多样性:独特命令数量、句子长度、词汇重叠度、BLEU、ROUGE-L、压缩比、Jaccard、Levenshtein 距离
- A.2 语义多样性:使用多种编码器(USE、SBERT、CLIP、SONAR)的句子嵌入,通过 BERTScore 和 PCA 内在维度分析测量
- A.3 结构多样性:POS 模式分布、句法树核相似度、否定/条件句/多步指令/循环结构的频率分析
Card 05
数据集与资源
数据集与资源
- VLA 数据集:RT-1、BRIDGE、TacoPlay、Language Table、LIBERO(来自 OXE)
- 语言导向机器人数据集:ALFRED、SCOUT
- NLU 和指令调优数据集:GLUE、OASST2、Alpaca、LLaVA-Instruct
- 数据规模:RT-1 约 370 万条指令,Language Table 约 700 万条指令
Card 06
评估与结果
评估与结果
- VLA 数据集中不到 2% 的指令是独特的,而指令调优数据集通常超过 70%
- RT-1 仅包含 49 个独特词汇,是所有数据集中最低的
- 否定语在不到 1% 的指令中出现,条件句同样罕见
- 压缩比指标显示 VLA 数据集重复度极高(RT-1 为 118.195)
- 多步指令在机器人数据集中最为常见,但缺乏逻辑结构(否定、条件、循环)
- POS 模式分析显示高度重复:RT-1 最频繁的句型占 11%,TacoPlay 占 24%
- 跨数据集词汇重叠低,仅有四个词(move、close、open、pick)在所有数据集中出现