一眼看懂
封面预览
论文提出 Counterfactual VLA (CF-VLA),一种自反思的视觉-语言-动作(VLA)框架,使模型能够在执行前对计划的行动进…
- 论文提出 Counterfactual VLA (CF-VLA),一种自反思的视觉-语言-动作(VLA)框架,使模型能够在执行前对计划的行动进…
- 当前 VLA 模型的推理主要是描述性的,缺乏自我反思能力;CF-VLA 通过反事实推理将推理轨迹从一次性描述升级为因果性自我修正信号
- 论文提出 rollout-filter-label 管道,从基础 VLA 的 rollout 中挖掘高价值场景,并标注反事实推理轨迹用于后续训练
Card 01
研究单位
研究单位
- NVIDIA(主要研究机构)
- UCLA(加州大学洛杉矶分校)
- Stanford University(斯坦福大学)
Card 02
论文概述
论文概述
- 论文提出 Counterfactual VLA (CF-VLA),一种自反思的视觉-语言-动作(VLA)框架,使模型能够在执行前对计划的行动进行推理和修正
- 当前 VLA 模型的推理主要是描述性的,缺乏自我反思能力;CF-VLA 通过反事实推理将推理轨迹从一次性描述升级为因果性自我修正信号
- 论文提出 rollout-filter-label 管道,从基础 VLA 的 rollout 中挖掘高价值场景,并标注反事实推理轨迹用于后续训练
- 实验在大规模驾驶数据集上进行,CF-VLA 将轨迹精度提高 17.6%,将安全指标提高 20.5%
Card 03
核心贡献
核心贡献
- 自反思反事实推理:提出一种新的推理-行动范式,使 VLA 能够基于自身预测的元动作进行推理,预测后果并在生成最终动作前修正计划
- 元动作与反事实数据管道:使用时间分段的元动作实现动作-语言对齐,提出 rollout-filter-label 管道自动从模型 rollout 中筛选反事实数据,形成自改进循环
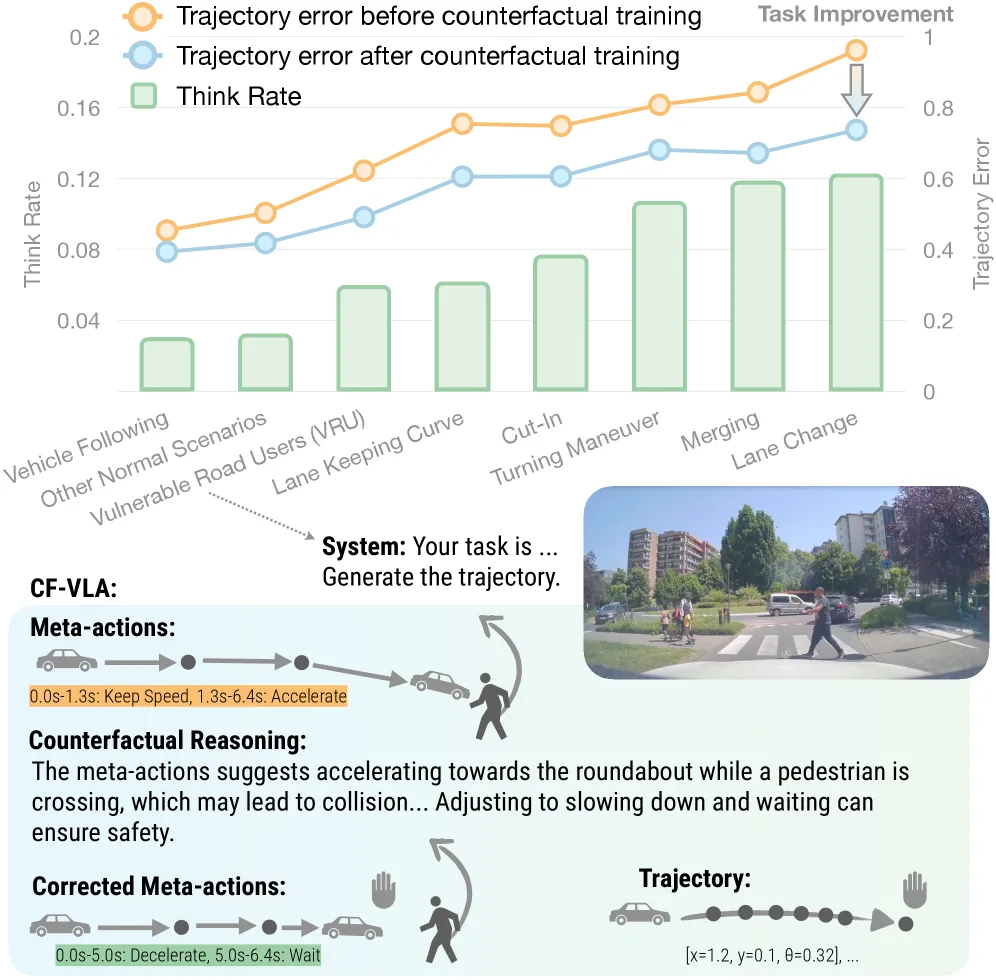
- 自适应思考能力:CF-VLA 表现出「必要时思考」的能力,将反事实推理集中在最具挑战性的场景中,在困难场景中思考更频繁并获得更大的任务性能提升
Card 04
方法描述
方法描述
- 元动作(Meta-Actions):时间分段的语言化中间表示,覆盖 6.4 秒规划范围,包含纵向(加速、减速、保持速度、等待、倒车)、横向(直行、左转、右转)和车道级(保持车道、左变道、右变道)三个维度
- 自反思循环:元动作 → 反事实推理 → 更新的元动作 → 轨迹,不是直接映射元动作到轨迹,而是执行自我反思循环
- Rollout-Filter-Label 管道:
- 数据 Rollout:生成自由生成轨迹和预填充元动作轨迹
- 数据过滤:使用轨迹不一致性(minADE(x_pf, x*) < minADE(x_free, x*) 且 minADE(x_free, x*) > ε)筛选高价值场景
- 数据标注:使用 Qwen2.5-VL-72B-Instruct 教师模型生成反事实推理轨迹
- 训练策略:混合数据训练(D_traj ∪ D_meta ∪ D_CF),分阶段训练,损失掩码和加权,支持多轮训练
Card 05
数据集与资源
数据集与资源
- 数据集:大规模内部数据集,包含来自 25 个国家、80,000 小时的人类驾驶数据,涵盖高速公路和城市驾驶、各种天气条件和昼夜场景
- D_traj:约 1160 万个 20 秒视频片段
- D_meta:训练集 433K 片段(20 秒)+ 801K 样本(8.4 秒),验证集 39K 片段 + 73K 样本
- D_CF:约 20 万样本
- 模型架构:与 Alpamayo-R1 规模和设计相似,输入包括文本提示、两个前置摄像头视频(120° 广角和 30° 长焦,2Hz,过去 2 秒)和自车轨迹历史
- 训练资源:使用轨迹标记器将未来运动表示为离散轨迹 token,扩展 VLM 词表以容纳新 token
Card 06
评估与结果
评估与结果
- 评估指标:
- 轨迹精度:MinADE/AvgADE、MinFDE/AvgFDE、Corner Distance
- 安全指标:Collision Rate、Off-road Rate
- 推理质量:Meta-Action IOU(初始 → 编辑后)、Output Length、Think Rate
- 主要结果:
- CF-VLA (w/ route, round2):MinADE 0.6813,MinFDE 1.8291,Collision 0.0174,Off-road 0.0585
- 比 traj-only 基线提升约 17.6% 轨迹精度
- 比 meta-act 基线提升约 9% 轨迹精度
- 安全指标(碰撞率)降低约 20.5%
- 多轮训练效果:第二轮训练进一步提升性能同时降低 think rate(从 0.219 降至 0.123)
- 自适应推理:CF-VLA 在简单场景(如车辆跟随)很少触发反事实推理,在高不确定性或高风险场景(如变道、转弯、VRU)显著增加 CF 推理,think rate 与轨迹误差强相关