一眼看懂
封面预览
论文提出了 DreamTacVLA 框架,旨在解决现有视觉-语言-动作(VLA)模型在接触丰富操作任务中缺乏物理感知的局限性。
- 论文提出了 DreamTacVLA 框架,旨在解决现有视觉-语言-动作(VLA)模型在接触丰富操作任务中缺乏物理感知的局限性。
- 核心目标是将高分辨率触觉感知融入VLA模型,使其能够推理力、纹理和滑动等接触物理特性。
- 通过引入分层感知方案和触觉世界模型,模型能够“感知”并预测未来触觉状态,从而实现更鲁棒的接触交互。
Card 01
研究单位
研究单位
- 论文作者所属机构信息未在提供的HTML原文中明确列出。
Card 02
论文概述
论文概述
- 论文提出了 DreamTacVLA 框架,旨在解决现有视觉-语言-动作(VLA)模型在接触丰富操作任务中缺乏物理感知的局限性。
- 核心目标是将高分辨率触觉感知融入VLA模型,使其能够推理力、纹理和滑动等接触物理特性。
- 通过引入分层感知方案和触觉世界模型,模型能够“感知”并预测未来触觉状态,从而实现更鲁棒的接触交互。
Card 03
核心贡献
核心贡献
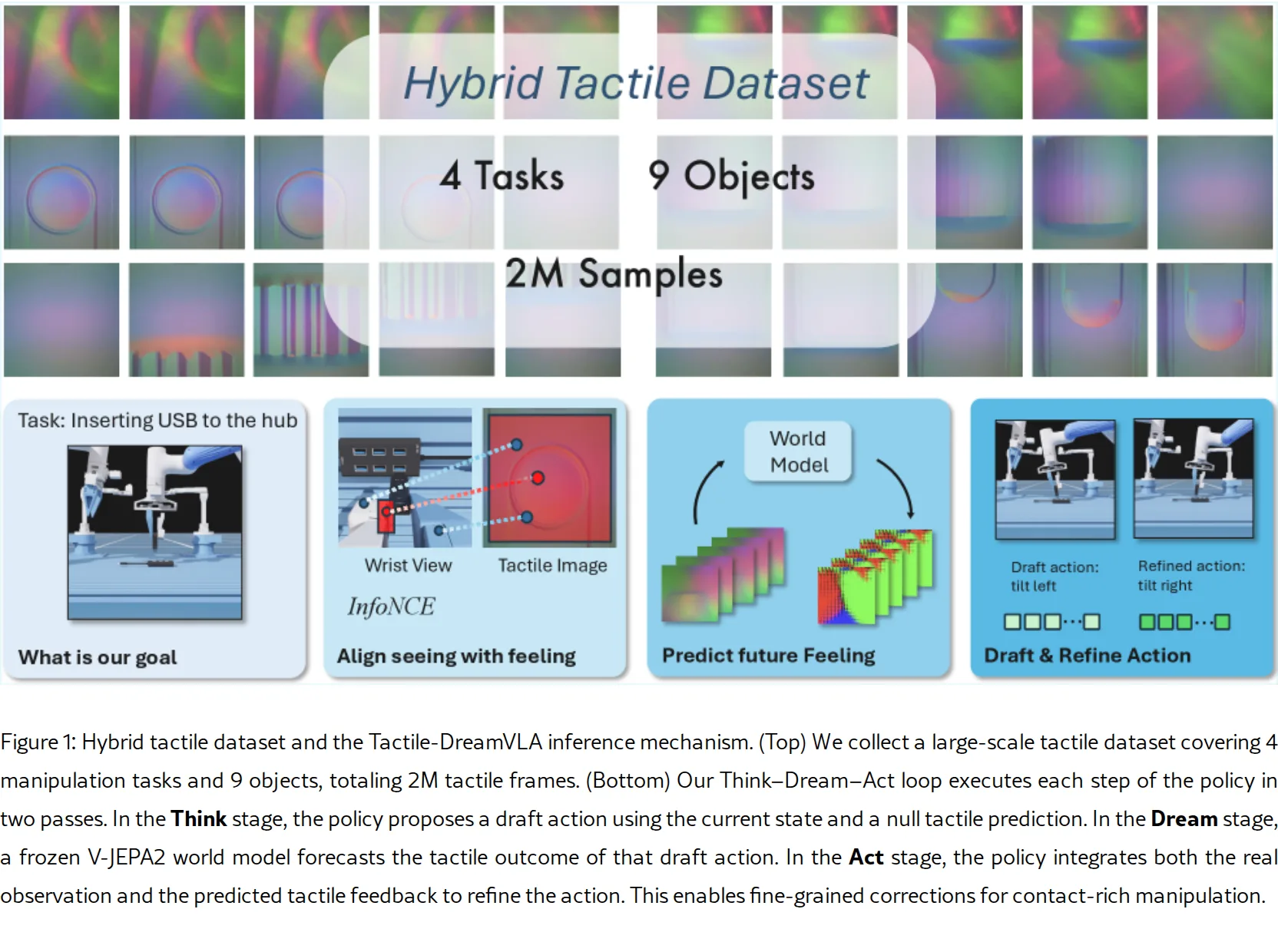
- 提出了 Hierarchical Spatial Alignment (HSA) 损失,通过对比学习将触觉、腕部相机和第三视角相机的多尺度感知信息对齐到统一的潜在空间。
- 引入了触觉世界模型,作为自监督目标来“梦境”未来触觉信号,使模型隐式学习接触物理和材料交互知识。
- 设计了 Think–Dream–Act 两阶段策略:首先提出草案动作,然后预测触觉后果,最后基于预测和实际观测执行精修动作。
- 构建了一个大规模混合触觉数据集,包含来自高保真数字孪生仿真和真实世界实验的数据,总计约200万触觉帧。
Card 04
方法描述
方法描述
- 采用分层感知框架,将触觉图像视为微视觉输入,与腕部局部视觉和第三人称宏观视觉结合。
- 使用两阶段训练流程:第一阶段用HSA损失训练多模态编码器和策略,获取空间对齐;第二阶段冻结预训练的触觉世界模型(基于 V-JEPA2),并训练预测MLP以实现动作精修。
- 技术创新在于利用机器人运动学和相机校准,将触觉激活映射到腕部及第三视角视图中的空间区域,实现跨模态空间对应。
Card 05
数据集与资源
数据集与资源
- 使用的数据集为自建的大规模混合触觉数据集,覆盖4项操作任务(插孔插入、USB插入、齿轮装配、工具稳定)和9种物体。
- 模型基于 CLIP (ViT-L) 作为视觉和语言骨干,并使用 V-JEPA2 (ViT-L/ViT-G) 作为触觉世界模型。
- 触觉世界模型冻结部分约为300M参数,附加的轻量级适配器引入了约5.5M可训练参数(开销1.8%)。
- 数据收集使用 IsaacSim 仿真环境和 TacEx 物理触觉模型,真实世界平台采用 Dobot Xtrainer 机械臂、GelSight 触觉传感器和 Realsense D405 相机。
Card 06
评估与结果
评估与结果
- 评估环境为仿真与真实世界结合,基准包括 ACT、Diffusion Policy、π₀ 以及加入触觉的ACT变体。
- 主要评估指标为任务成功率。
- 在四项真实世界接触丰富任务中,完整模型(HSA & Dream)实现了最高成功率,其中在插孔插入任务上达到 95.0%±0.2%,显著超越所有基线方法。
- 消融实验表明,HSA和触觉世界模型共同作用,平均带来22.3%的性能提升,证明了空间对齐与触觉预测的互补性。