一眼看懂
封面预览
提出 ColaVLA,一个统一的视觉-语言-动作(Vision-Language-Action, VLA)框架,用于端到端自动驾驶轨迹规划
- 提出 ColaVLA,一个统一的视觉-语言-动作(Vision-Language-Action, VLA)框架,用于端到端自动驾驶轨迹规划
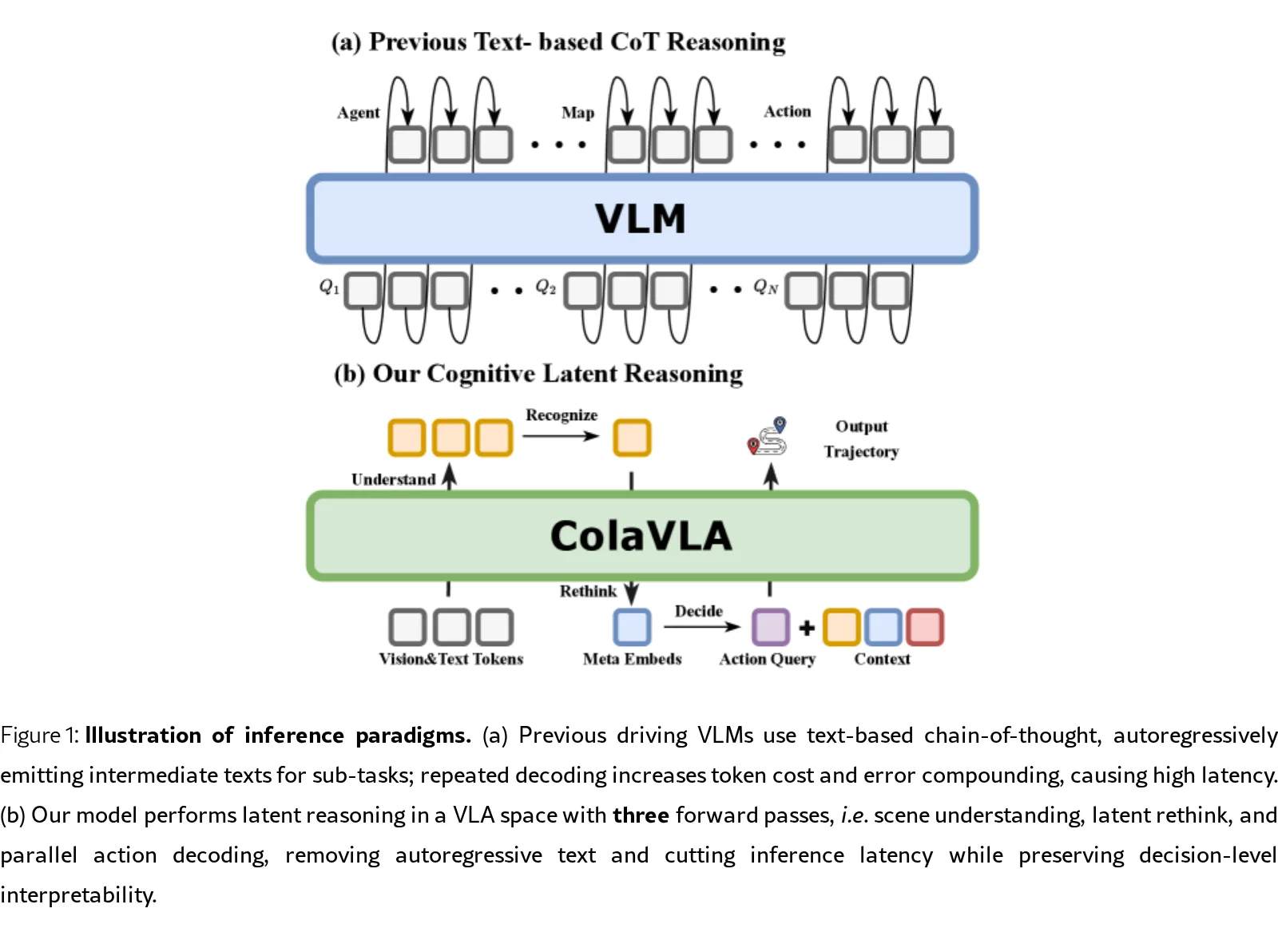
- 解决现有基于视觉语言模型(VLM)的自动驾驶规划器面临的三大挑战:(1)离散文本推理与连续控制之间的模态不匹配;(2)自回归链式思维解码带来的…
- 通过将推理从文本空间转移到统一的潜在空间,并结合层次化并行轨迹解码器,实现高效、准确且安全的轨迹生成
Card 01
研究单位
研究单位
- 清华大学(第一作者单位)
- 香港中文大学 MMLab(CUHK MMLab)
- 滴滴出行 Voyager Research
Card 02
论文概述
论文概述
- 提出 ColaVLA,一个统一的视觉-语言-动作(Vision-Language-Action, VLA)框架,用于端到端自动驾驶轨迹规划
- 解决现有基于视觉语言模型(VLM)的自动驾驶规划器面临的三大挑战:(1)离散文本推理与连续控制之间的模态不匹配;(2)自回归链式思维解码带来的高延迟;(3)低效或非因果的规划器限制实时部署
- 通过将推理从文本空间转移到统一的潜在空间,并结合层次化并行轨迹解码器,实现高效、准确且安全的轨迹生成
Card 03
核心贡献
核心贡献
- 提出 ColaVLA 统一VLA框架,直接在连续轨迹上操作,避免模态不匹配的同时利用VLM先验知识
- 设计 Cognitive Latent Reasoner(认知潜在推理器),将推理从文本链式思维重新定位到统一潜在空间,仅需两次VLM前向传播即可完成场景理解、自适应路由选择和元信息压缩
- 提出 Hierarchical Parallel Planner(层次化并行规划器),在单次前向传播中并行解码所有时间尺度和模式,实现因果一致的轨迹生成
- 在 nuScenes 基准测试上,ColaVLA在开放环路和封闭环路评估中均达到最先进的性能,同时保持强可解释性和计算效率
Card 04
方法描述
方法描述
- 认知潜在推理:通过"理解-识别-反思-决策"四阶段流程,将场景理解压缩为紧凑的、面向决策的元动作嵌入;采用 ego-adaptive FiLM调制 对齐视觉token与车辆状态,并通过轻量级路由器选择前K个安全关键视觉token
- 层次化并行规划:基于选定的元动作,通过时间嵌入实例化全时域动作块,重采样为S个嵌套的粗到细尺度;设计 因果保持混合注意力掩码,允许粗尺度向细尺度的因果信息流,同时禁止反向信息泄漏
- 置信度引导并行解码:同时处理多个候选驾驶策略,通过轻量级MLP头估计置信度分数并回归多尺度轨迹,采用基于距离的one-hot监督信号防止模式崩溃
Card 05
数据集与资源
数据集与资源
- 数据集:nuScenes(1,000个驾驶场景,约20秒/场景,包含6个相机图像、LiDAR数据、语义地图和3D边界框标注);OmniDrive-nuScenes 扩展(增加QA格式的感知、预测和规划标注)
- 模型规模:基于 LLaVA v1.5 框架,使用 LLaMA-7B 作为语言模型;图像编码器采用 EVA-02-L;SQ-Former架构;900个目标查询和300个车道查询
- 训练资源:使用 AdamW 优化器和余弦退火学习率调度,权重衰减 $1\times 10^{-4}$,初始学习率 $1\times 10^{-4}$;采用LoRA高效微调
- 推理延迟:在单张 NVIDIA H20 GPU 上为 727ms(相比OmniDrive的3727ms和SOLVE-VLM的3719ms,实现5倍以上加速)
Card 06
评估与结果
评估与结果
- 开放环路评估(nuScenes):平均L2误差 0.30m,平均碰撞率 0.23%;相比最强基线SOLVE-E2E,L2降低3%,碰撞率降低23%
- 封闭环路评估(NeuroNCAP):NeuroNCAP分数 3.16(相比ImpromptuVLA提升+1.10,相对提升53%);平均碰撞率从65.1%降至 36.8%;静态碰撞率从54.8%降至 15.0%(降低约73%)
- 关键指标:在1s/2s/3s时间尺度的L2误差分别为 0.14m/0.27m/0.50m;在1s/2s/3s时间尺度的碰撞率分别为 0.04%/0.17%/0.47%
- 消融实验验证:潜在推理模块(含Rethink阶段)将平均L2从32.2cm降至30.4cm;层次化并行规划器在NeuroNCAP上显著优于MLP和扩散基线;保留token数K=256达到最佳效率-性能平衡;插值策略的多尺度回归效果最优