一眼看懂
封面预览
研究视觉-语言-动作(VLA)模型中人类到机器人迁移能力的涌现现象,探索如何利用人类视频数据提升机器人策略的泛化能力
- 研究视觉-语言-动作(VLA)模型中人类到机器人迁移能力的涌现现象,探索如何利用人类视频数据提升机器人策略的泛化能力
- 提出简单的协同训练(co-training)方法,将人类视频视为另一种机器人 embodiment 进行训练,无需显式对齐
- 解决的核心问题:如何有效利用大规模、易获取的人类视频数据来扩展机器人学习的数据来源,克服传统方法需要手动工程对齐的局限
Card 01
研究单位
研究单位
- Physical Intelligence(主要研究机构)
- Georgia Institute of Technology(佐治亚理工学院)
Card 02
论文概述
论文概述
- 研究视觉-语言-动作(VLA)模型中人类到机器人迁移能力的涌现现象,探索如何利用人类视频数据提升机器人策略的泛化能力
- 提出简单的协同训练(co-training)方法,将人类视频视为另一种机器人 embodiment 进行训练,无需显式对齐
- 解决的核心问题:如何有效利用大规模、易获取的人类视频数据来扩展机器人学习的数据来源,克服传统方法需要手动工程对齐的局限
Card 03
核心贡献
核心贡献
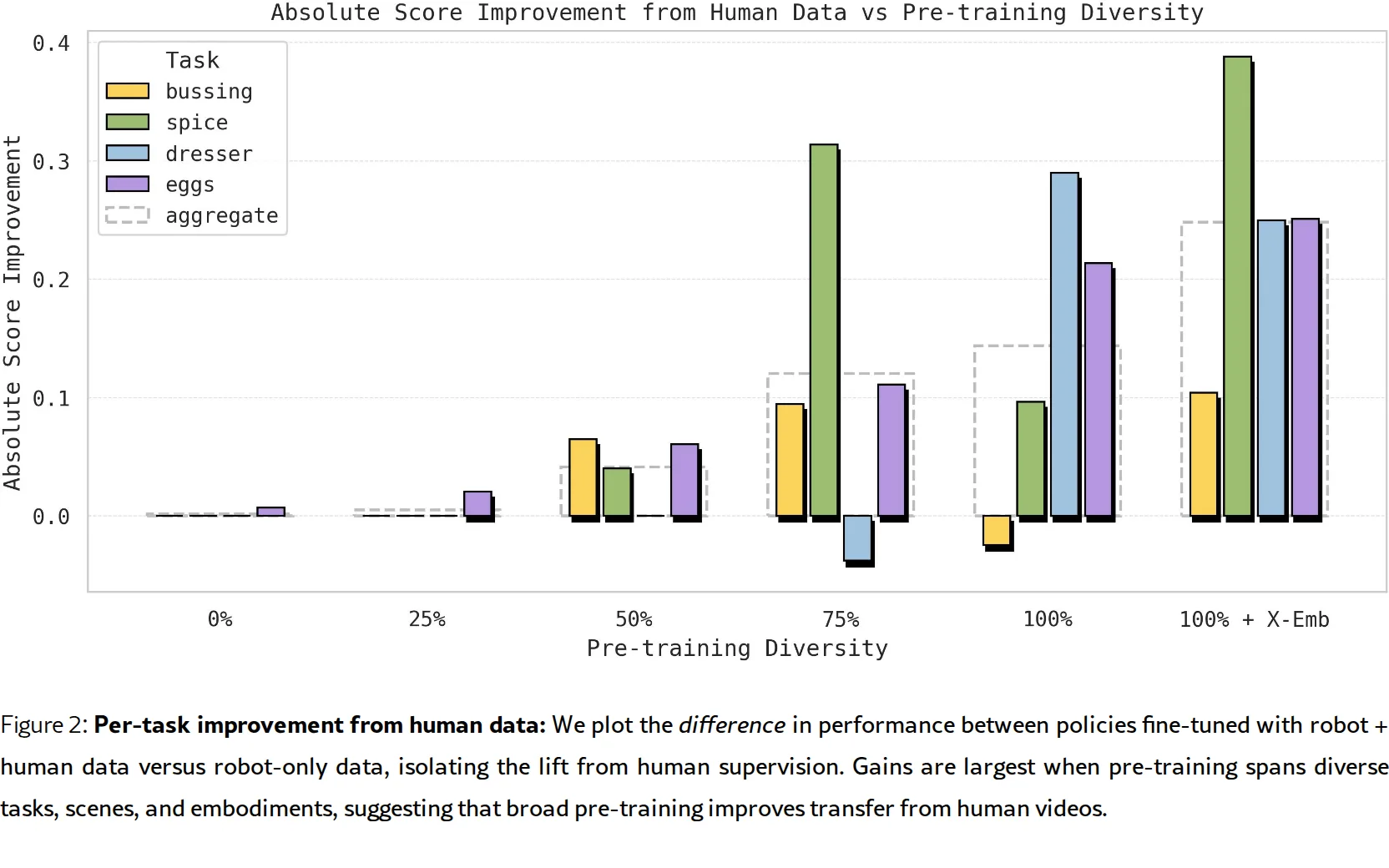
- 发现人类到机器人迁移是VLA预训练的涌现特性——当预训练数据在场景、任务和机器人形态上足够多样化时,迁移能力自然出现
- 提出π₀.₅ + ego 训练配方:基于π₀.₅模型,通过协同训练人类数据和机器人数据,在未见场景、新物体类别和新任务语义上实现近2倍性能提升
- 揭示多样化预训练产生形态无关表征(embodiment-agnostic representations)——通过t-SNE分析证明,预训练多样性增加时,人类和机器人数据的潜在表征自然对齐
- 建立人类到机器人迁移基准测试,涵盖场景迁移(Spice、Dresser)、物体迁移(Bussing)和任务迁移(Sort Eggs)三个维度
- 证明人类数据价值可与跨形态机器人数据(cross-embodiment robot data)相媲美,为大规模人类数据收集提供理论基础
Card 04
方法描述
方法描述
- 数据收集:使用头戴相机+双腕部相机的轻量化设备采集人类第一视角视频,通过视觉SLAM重建6D头部运动,提取17个3D手部关键点
- 动作空间对齐:将人类手部关键点转换为相对6-DoF末端执行器姿态,与机器人动作表示对齐(忽略夹爪开合)
- 训练目标:同时使用(1)基于流的连续动作预测和(2)高层子任务语言预测,与人类和机器人数据共享相同目标
- 微调策略:50-50比例混合人类数据(用于泛化任务)和最近邻机器人任务数据进行协同微调
Card 05
数据集与资源
数据集与资源
- 人类数据集:约14小时人类视频(Bussing 3小时、Spice 3小时、Dresser 3小时、Sort Eggs 5小时)
- 基础模型:π₀.₅(3B参数VLA模型,基于PaliGemma VLM架构)
- 预训练数据:包含大规模多样化机器人遥操作数据,涵盖多种场景、任务和机器人形态(ARX、mobile ARX等)
- 对比实验:使用不同预训练程度初始化(0%、25%、50%、75%、100%、100%+X-emb跨形态数据)
Card 06
评估与结果
评估与结果
- 评估基准:4个真实机器人任务,测试场景/物体/任务三个维度的泛化
- 关键结果:
- Spice任务:32% → 71%(场景迁移)
- Dresser任务:25% → 50%(场景迁移)
- Bussing任务:53% → 63%(物体迁移)
- Sort Eggs任务:57% → 78%(任务迁移,新增排序语义概念)
- 核心发现:预训练多样性从25%提升到100%+X-emb时,人类数据带来的迁移增益显著增加;低多样性预训练甚至出现负迁移