一眼看懂
封面预览
提出 StereoVLA,首个系统性地将立体视觉(stereo vision)引入视觉-语言-动作(VLA)模型的机器人学习框架
- 提出 StereoVLA,首个系统性地将立体视觉(stereo vision)引入视觉-语言-动作(VLA)模型的机器人学习框架
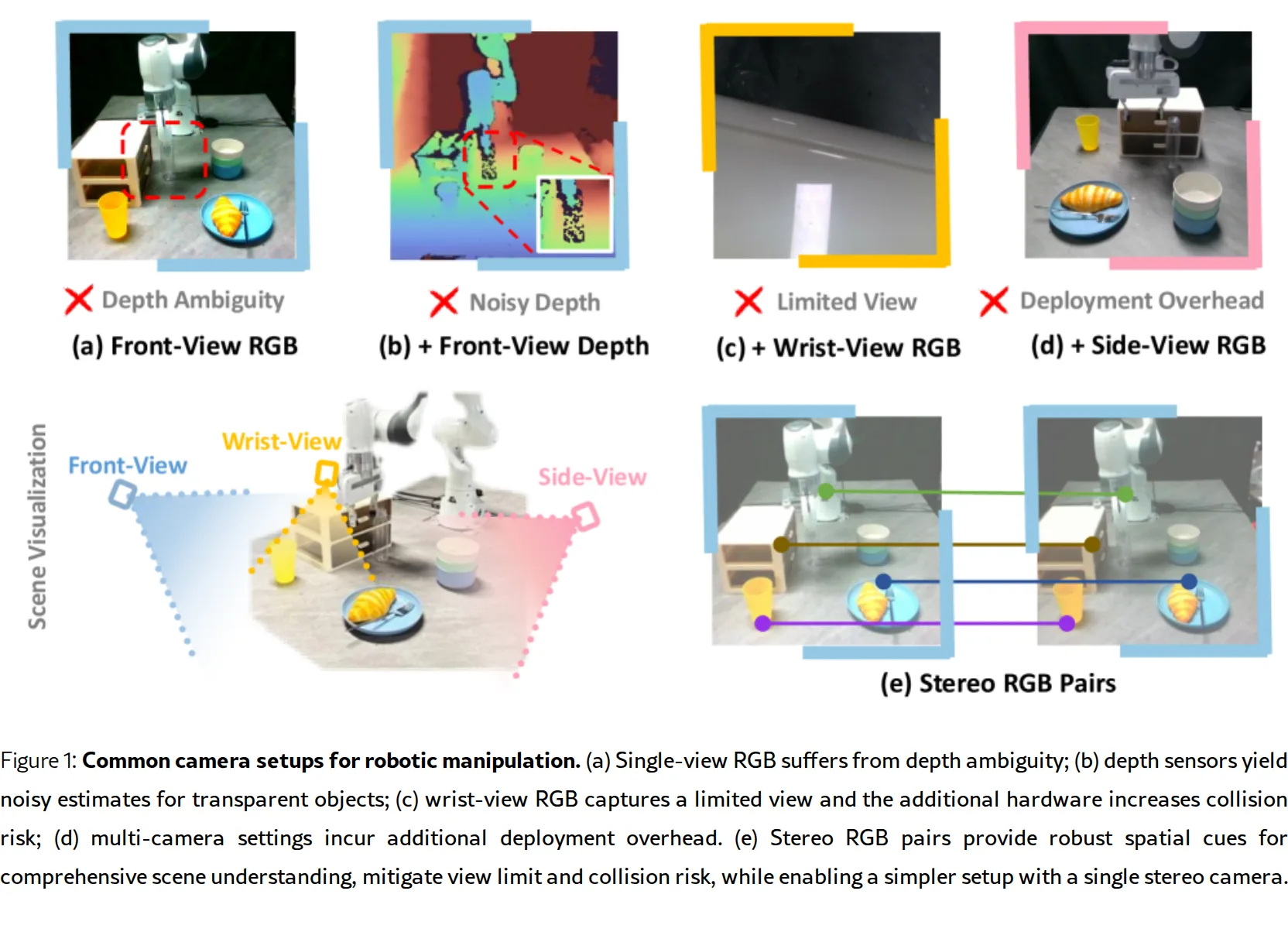
- 解决现有 VLA 模型依赖单目 RGB 输入导致的几何感知不足问题,利用立体视觉提供的丰富空间线索实现精确机器人操作
- 核心挑战在于如何有效融合立体几何特征与预训练视觉语言模型的语义理解能力,同时保持对相机位姿变化的鲁棒性
Card 01
研究单位
研究单位
- Galbot
- Peking University(北京大学)
- The University of Hong Kong(香港大学)
- Institute of Automation, Chinese Academy of Sciences(中国科学院自动化研究所)
- Beijing Academy of Artificial Intelligence(北京人工智能研究院)
- Xiamen University Malaysia(厦门大学马来西亚分校)
Card 02
论文概述
论文概述
- 提出 StereoVLA,首个系统性地将立体视觉(stereo vision)引入视觉-语言-动作(VLA)模型的机器人学习框架
- 解决现有 VLA 模型依赖单目 RGB 输入导致的几何感知不足问题,利用立体视觉提供的丰富空间线索实现精确机器人操作
- 核心挑战在于如何有效融合立体几何特征与预训练视觉语言模型的语义理解能力,同时保持对相机位姿变化的鲁棒性
Card 03
核心贡献
核心贡献
- 提出 Geometric-Semantic Feature Extraction(几何-语义特征提取)模块,从 FoundationStereo 提取密集几何特征,从 SigLIP 和 DINOv2 提取语义特征,实现几何精度与语义丰富性的统一
- 设计 Interaction-Region Depth Estimation(交互区域深度估计) 辅助任务,聚焦夹爪-目标物体区域的关键空间细节,加速模型收敛
- 在多样化真实世界操作任务中,相比基线方法成功率提升 33%,在精细操作场景(如抓取小物体)上实现从 0% 到 30% 的突破
- 系统比较多种相机配置,证明立体视觉在性能、鲁棒性和部署简洁性上的最佳平衡
Card 04
方法描述
方法描述
- 视觉编码:立体图像对输入 FoundationStereo,绕过视差预测组件,提取过滤后的代价体 V_c' 作为几何特征;左视图经 SigLIP 和 DINOv2 提取语义特征
- 特征融合:空间对齐后通道维度拼接(避免序列拼接带来的计算开销),经 MLP 投影器生成混合视觉 token
- 动作生成:基于 InternLM-1.8B 大语言模型,300M 参数动作专家采用 flow-matching 预测 delta 末端执行器位姿
- 多任务训练:联合优化动作预测、交互区域深度估计、边界框预测和关键帧位姿预测,损失权重 5:2:2:1
Card 05
数据集与资源
数据集与资源
- 合成数据:使用 MuJoCo 和 Isaac Sim 渲染 500 万条立体视觉抓取轨迹,图像分辨率 256×256,训练时 resize 至 224×224
- 辅助数据集:引入互联网规模定位数据集 GRIT 增强语义 grounding 能力
- 训练配置:32 张 NVIDIA H800 GPU,batch size 384,学习率 1.6e-4,训练 160k 步
- 模型规模:1.8B 参数语言主干 + 300M 参数动作专家
Card 06
评估与结果
评估与结果
- 评估环境:真实世界 Franka 机械臂,0.5m×0.4m 工作空间,配备 Zed Mini 立体相机
- 任务套件:通用抓取放置任务、条形物体定向抓取(0°/45°/90°)、中小尺寸物体抓取(3-5cm 和 1-2cm)
- 评估指标:任务成功率(严格标准:单次执行、无 gripper sticking 启发式、完全完成才算成功)
- 关键结果:
- 条形物体 90° 定向抓取:100% 成功率,基线最高仅 60%
- 小物体(1-2cm)抓取:30% 成功率,基线全部失败(0%)
- 相机位姿大范围随机化:成功率 61.3%,显著优于 front+side 配置的 24.1% 和 front+wrist 配置的 51.6%