一眼看懂
封面预览
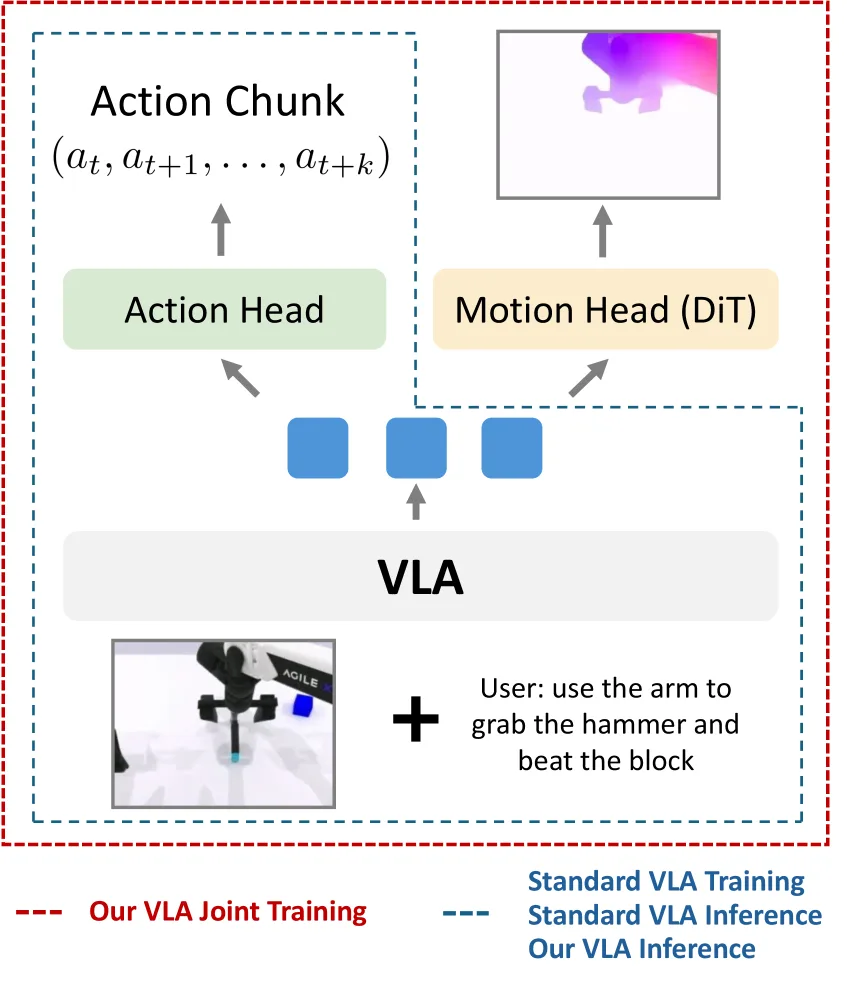
提出与运动图像扩散的联合学习策略,增强视觉-语言-动作(VLA)模型的运动推理能力
- 提出与运动图像扩散的联合学习策略,增强视觉-语言-动作(VLA)模型的运动推理能力
- 解决现有VLA模型仅模仿专家轨迹、缺乏预测性运动推理的问题
- 通过双头设计(动作头+运动头)在保持标准VLA推理效率的同时提升时序理解和物理基础表示
Card 01
研究单位
研究单位
- Salesforce AI Research
- University of North Carolina at Chapel Hill
Card 02
论文概述
论文概述
- 提出与运动图像扩散的联合学习策略,增强视觉-语言-动作(VLA)模型的运动推理能力
- 解决现有VLA模型仅模仿专家轨迹、缺乏预测性运动推理的问题
- 通过双头设计(动作头+运动头)在保持标准VLA推理效率的同时提升时序理解和物理基础表示
Card 03
核心贡献
核心贡献
- 提出联合学习策略,无缝增强VLA模型的运动推理能力,同时保持实时推理效率
- 设计运动图像扩散模块,使用Diffusion Transformer (DiT) 提供密集的像素级动态监督
- 证明基于光流的运动图像是联合动作-运动学习最有效的表示形式
- 在LIBERO基准上达到97.5%成功率,在RoboTwin基准上达到58.0%成功率
- 在真实世界实验中实现23%的性能提升
Card 04
方法描述
方法描述
- 双头架构设计:动作头预测动作块(与标准VLA相同),运动头使用DiT预测基于光流的未来运动图像
- 共享VLM主干:两个头共享相同的多模态表示,实现动作学习与运动学习的耦合
- 流匹配损失:对两个头均采用流匹配损失进行联合优化
- 潜在空间扩散:使用冻结VAE将光流图像编码到紧凑潜在空间,降低计算成本并稳定扩散过程
- 两阶段训练:先预热训练运动头,再联合训练整个架构
Card 05
数据集与资源
数据集与资源
- 预训练数据:DROID数据集(大规模真实机器人数据集)
- 模拟评估:LIBERO基准(四个套件:Spatial/Object/Goal/Long)、RoboTwin 2.0基准(双臂操作)
- 真实世界:自定义桌面操作任务(30次演示/任务)
- 模型规模:Paligemma-3B(VLM主干)、Paligemma-300M(动作头)、400M参数DiT(运动头)
- 训练资源:8× NVIDIA H200 GPU
Card 06
评估与结果
评估与结果
- LIBERO基准:联合学习的π₀达到94.7%平均成功率,π₀.₅达到97.5%,在Long套件上提升4.0%
- RoboTwin基准:平均成功率58.0%,比π₀基线提升13.1%,在困难模式下展现更强鲁棒性
- 消融实验:运动图像表示优于语言描述(86.1%)和未来图像预测(93.6%)
- 数据效率:仅使用25%数据时,长程任务成功率比基线高14.2%
- 真实世界:在有限数据条件下实现23%的性能提升