一眼看懂
封面预览
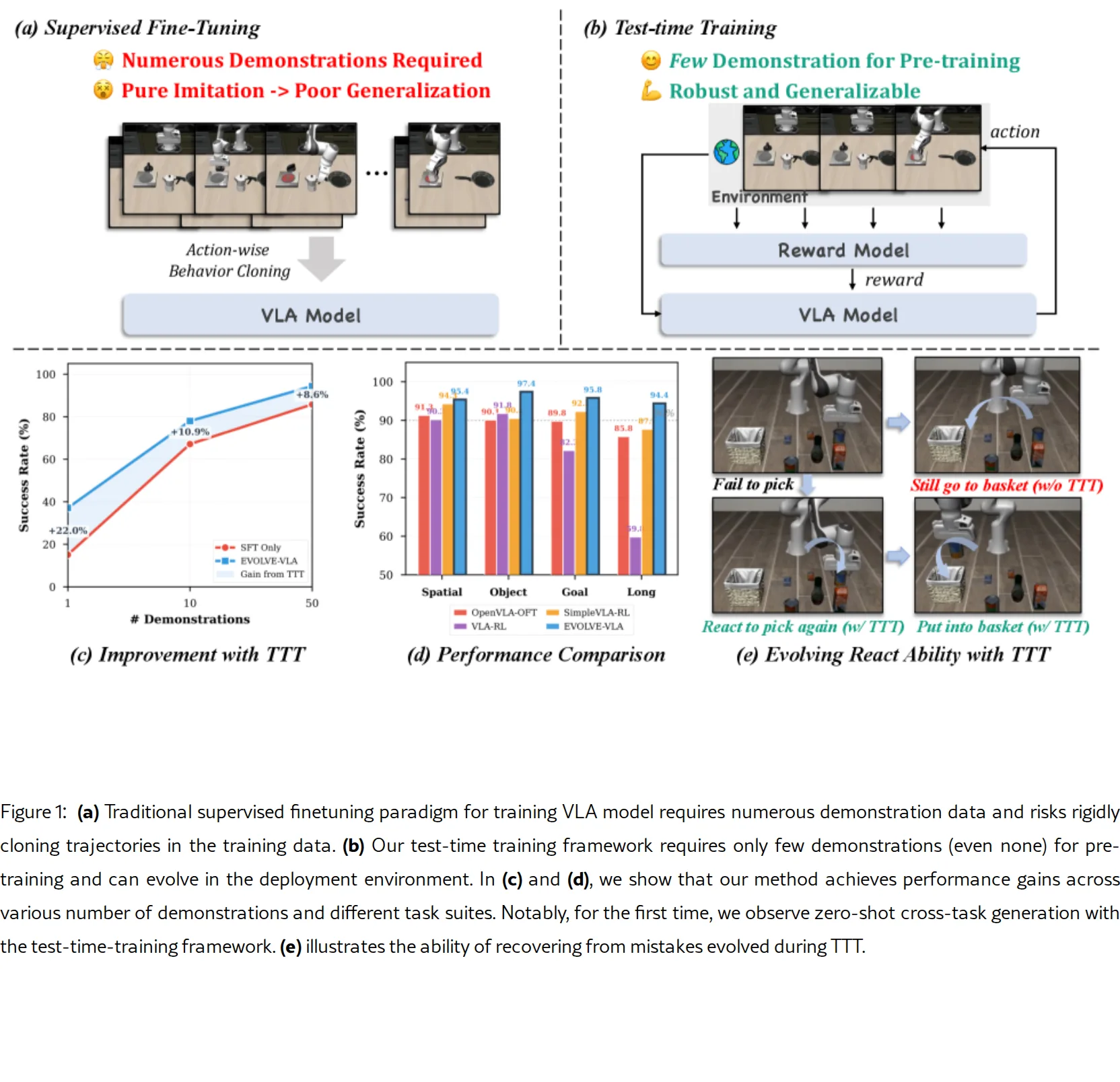
提出 EVOLVE-VLA,首个通过环境反馈实现测试时训练(Test-Time Training, TTT)的视觉-语言-动作(VLA)模型框…
- 提出 EVOLVE-VLA,首个通过环境反馈实现测试时训练(Test-Time Training, TTT)的视觉-语言-动作(VLA)模型框…
- 解决传统VLA模型的核心局限:监督微调(SFT)需要大量演示数据、僵化记忆轨迹、无法适应分布外场景
- 核心挑战在于用学习得到的进度估计器替代测试时不可用的真实奖励信号,并通过技术创新"驯服"固有的噪声信号
Card 01
研究单位
研究单位
- Show Lab, National University of Singapore (新加坡国立大学)
- 作者:Zechen Bai, Chen Gao, Mike Zheng Shou (通讯作者)
Card 02
论文概述
论文概述
- 提出 EVOLVE-VLA,首个通过环境反馈实现测试时训练(Test-Time Training, TTT)的视觉-语言-动作(VLA)模型框架,使机器人能够从环境交互中持续学习而非仅模仿静态演示
- 解决传统VLA模型的核心局限:监督微调(SFT)需要大量演示数据、僵化记忆轨迹、无法适应分布外场景
- 核心挑战在于用学习得到的进度估计器替代测试时不可用的真实奖励信号,并通过技术创新"驯服"固有的噪声信号
Card 03
核心贡献
核心贡献
- 提出测试时训练框架,仅需极少演示(甚至零演示)即可初始化,部署后通过在线强化学习持续自适应
- 设计累积进度估计机制(Accumulative Progress Estimation):基于区间采样的里程碑框架,通过增量计算和"收益递减"原则平滑噪声点估计
- 提出渐进式视野扩展策略(Progressive Horizon Extension):分阶段逐步增加探索范围,使策略先掌握简单子任务再学习完整任务
- 实现显著性能提升:长程任务 +8.6%、1-shot学习 +22.0%、首次实现零样本跨任务泛化(0% → 20.8%)
- 发现涌现能力:错误恢复、新颖策略探索等训练演示中不存在的行为
Card 04
方法描述
方法描述
- 在线强化学习:使用 GRPO(Group Relative Policy Optimization) 进行策略优化,通过温度采样生成多样化轨迹
- 进度估计作为奖励:采用基础模型 VLAC 作为critic,输入两帧图像和任务指令输出进度值
- 关键技术创新1——累积进度估计:维护里程碑帧列表,以固定间隔(如64步)采样,增量计算进度并应用递归公式平滑噪声,仅需单次critic调用即可估计当前进度
- 关键技术创新2——渐进式视野扩展:将训练分为多个阶段,逐步增加最大视野长度,实现课程学习效果
- 动作表示:采用离散动作token(而非连续回归),兼容自回归VLA架构
Card 05
数据集与资源
数据集与资源
- 数据集:LIBERO 基准测试,包含4个任务套件(Spatial、Object、Goal、Long),每任务50条专家演示
- 基础模型:OpenVLA-OFT(基于OpenVLA改进,采用动作分块和并行解码)
- 进度估计模型:VLAC(预训练的基础critic模型)
- 训练资源:未明确说明GPU/TPU配置,实验在仿真环境中进行
Card 06
评估与结果
评估与结果
- 评估环境:LIBERO仿真基准的4个任务套件
- 主要指标:成功率(Success Rate, SR),每任务50次试验取平均
- 关键实验结果:
- 完整数据设置(50演示):平均SR从89.2%提升至95.8%(+6.5%),其中Long套件提升+8.6%(85.8%→94.4%)
- 极低数据设置(1演示):平均SR从43.6%提升至61.3%(+17.7%),Long套件提升+22.0%
- 零样本跨任务泛化:LIBERO-Long预训练模型直接部署到LIBERO-Object,通过TTT达到20.8%成功率(SFT基线为0%)
- 消融验证:累积进度估计的区间采样策略在保持32次奖励调用的计算效率下实现最佳F-Score(0.20)和SR(91.3%);渐进式视野扩展额外带来+3.1%增益