一眼看懂
封面预览
提出 MindDrive,首个通过在线强化学习(Online RL)训练的视觉-语言-动作(VLA)自动驾驶模型,解决传统模仿学习(IL)中的…
- 提出 MindDrive,首个通过在线强化学习(Online RL)训练的视觉-语言-动作(VLA)自动驾驶模型,解决传统模仿学习(IL)中的…
- 核心创新在于将连续动作空间转换为离散语言决策空间,通过动态语言-动作映射实现高效探索,并利用轨迹级奖励优化推理能力
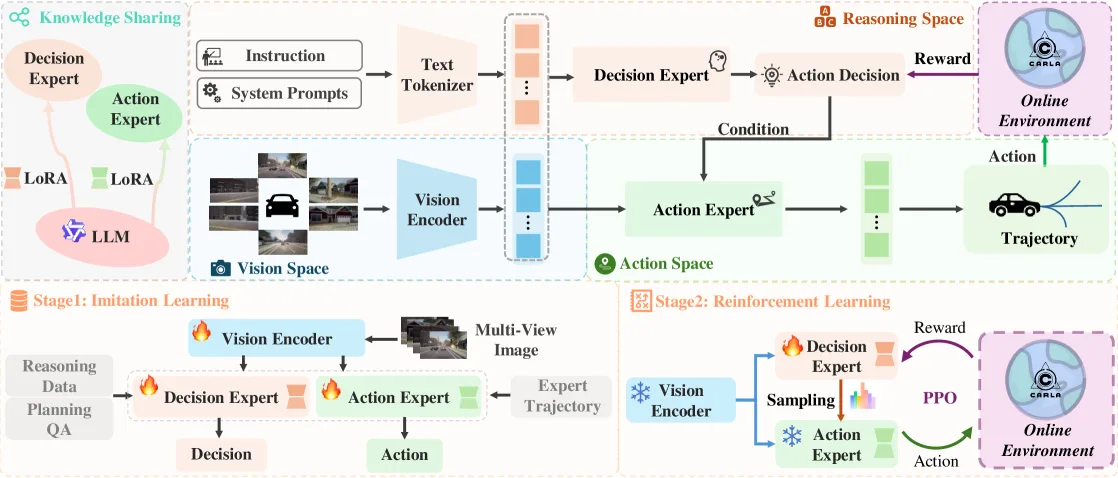
- 提出双专家架构:Decision Expert(决策专家)负责场景推理和驾驶决策,Action Expert(动作专家)将语言决策动态映射为可…
Card 01
研究单位
研究单位
- Huazhong University of Science and Technology(华中科技大学)
- Xiaomi EV(小米汽车)
Card 02
论文概述
论文概述
- 提出 MindDrive,首个通过在线强化学习(Online RL)训练的视觉-语言-动作(VLA)自动驾驶模型,解决传统模仿学习(IL)中的分布偏移和因果混淆问题
- 核心创新在于将连续动作空间转换为离散语言决策空间,通过动态语言-动作映射实现高效探索,并利用轨迹级奖励优化推理能力
Card 03
核心贡献
核心贡献
- 提出双专家架构:Decision Expert(决策专家)负责场景推理和驾驶决策,Action Expert(动作专家)将语言决策动态映射为可行轨迹,两者共享基础LLM但使用不同LoRA参数
- 建立语言-动作映射机制,通过模仿学习预训练建立元动作与多模态轨迹的一一对应,为在线RL提供高质量候选轨迹并缩小探索空间
- 设计计算高效的在线RL框架,基于CARLA模拟器实现闭环交互训练,采用稀疏奖励函数和PPO算法优化决策专家的推理能力
- 在Bench2Drive基准上取得SOTA性能:使用轻量级Qwen2-0.5B模型,Driving Score达78.04,Success Rate达55.09%,超越同规模IL基线ORION 5.15 DS和9.26% SR
Card 04
方法描述
方法描述
- 两阶段训练流程:第一阶段用模仿学习(IL)训练语言-动作对齐,包括交叉熵损失、行为克隆损失、VAE损失和检测损失;第二阶段用在线强化学习(RL)优化决策专家,采用PPO算法、GAE优势估计和KL散度正则化防止灾难性遗忘
- 动态映射机制:Decision Expert生成7种速度元动作和6种路径元动作,Action Expert通过VAE和GRU解码器将其转换为6个速度航点(3秒轨迹,2Hz采样)和20个路径航点(20米路径,1米间隔)
- 高效RL训练:部署24个并行CARLA采集器,使用状态嵌入缓存减少内存开销,支持大批量训练;价值网络共享LLM权重,仅最后一层替换为MLP
Card 05
数据集与资源
数据集与资源
- 数据集:Bench2Drive基准,基于CARLA模拟器,包含1000个训练片段(base set)和220个短路线用于闭环评估,覆盖44种交互场景
- 模型规模:基础LLM为Qwen2-0.5B(5亿参数),视觉编码器为EVA-02-L,LoRA秩维度为16
- 训练资源:32块NVIDIA A800 GPU(80GB显存),24个并行CARLA模拟器用于RL数据收集
Card 06
评估与结果
评估与结果
- 评估环境:CARLA模拟器闭环评估,官方Bench2Drive基准
- 主要指标:Driving Score (DS)、Success Rate (SR)、Multi-Ability(包含Merging、Overtaking、Emergency Brake、Give Way、Traffic Sign五种能力)
- 关键结果:MindDrive在Overtaking能力提升55.56%,Give Way提升30%;相比离线RL方法RecogDrive,DS提升6.68,SR提升9.64%;相比同规模IL方法ORION(Qwen2-0.5B),Mean Ability提升5.57%