一眼看懂
封面预览
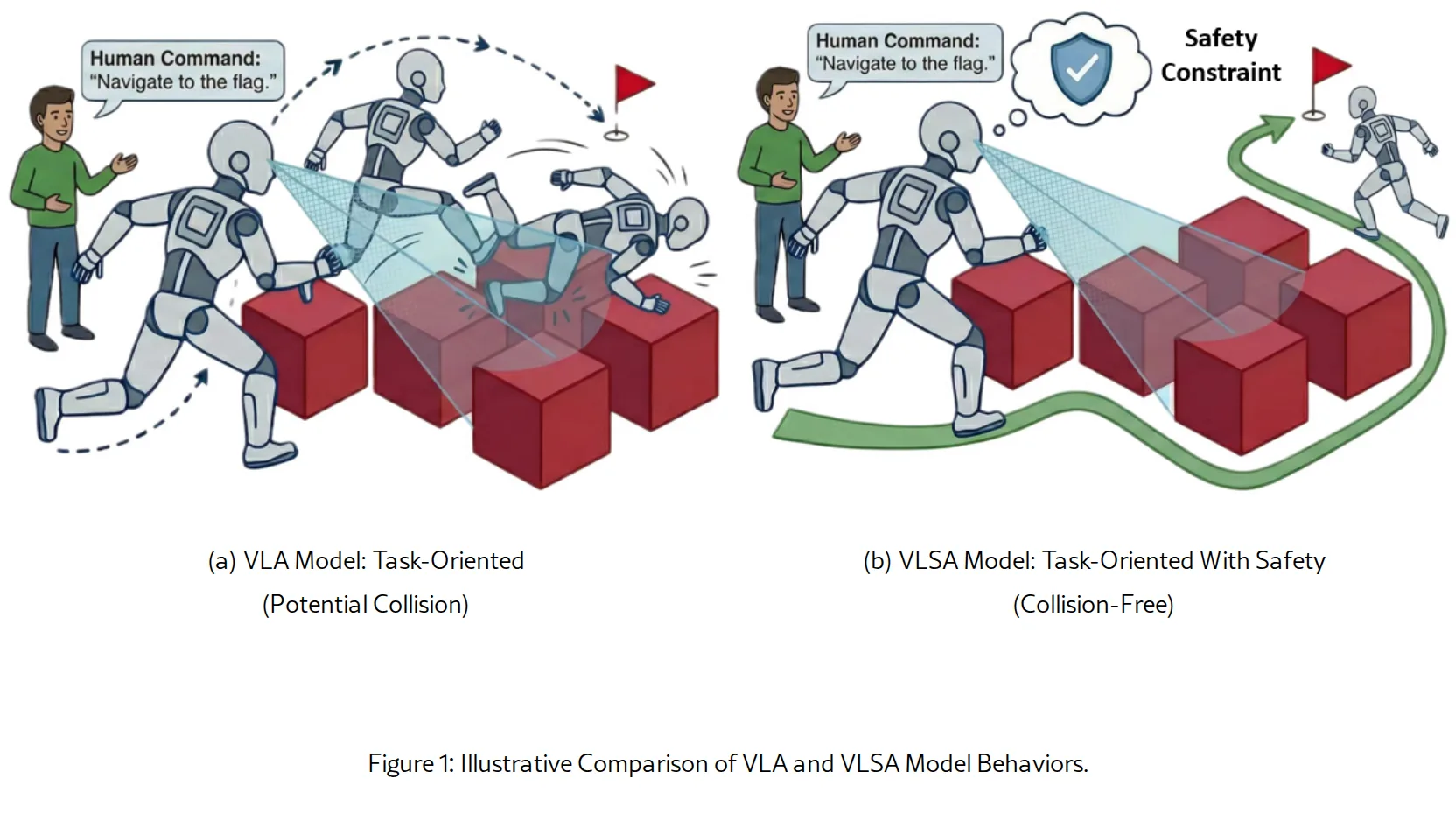
提出一个名为 AEGIS 的视觉-语言-安全动作 架构,旨在解决现有视觉-语言-动作 模型在非结构化环境中部署时缺乏安全保证的关键问题。
- 提出一个名为 AEGIS 的视觉-语言-安全动作 架构,旨在解决现有视觉-语言-动作 模型在非结构化环境中部署时缺乏安全保证的关键问题。
- 核心是设计了一个即插即用的安全约束层,该层利用控制屏障函数来构建,能够在推理过程中动态调整原始动作,在保持任务性能的同时提供理论安全保证。
- 为了评估模型,作者构建了一个名为 SafeLIBERO 的综合性安全关键基准测试集。
Card 01
研究单位
研究单位
- 清华大学 (Tsinghua University)
- TetraBOT
- 达摩院,阿里巴巴集团 (DAMO Academy, Alibaba Group)
Card 02
论文概述
论文概述
- 提出一个名为 AEGIS 的视觉-语言-安全动作 架构,旨在解决现有视觉-语言-动作 模型在非结构化环境中部署时缺乏安全保证的关键问题。
- 核心是设计了一个即插即用的安全约束层,该层利用控制屏障函数来构建,能够在推理过程中动态调整原始动作,在保持任务性能的同时提供理论安全保证。
- 为了评估模型,作者构建了一个名为 SafeLIBERO 的综合性安全关键基准测试集。
Card 03
核心贡献
核心贡献
- 提出了首个将控制屏障函数集成到 VLA 模型中以强制执行显式安全约束的框架 AEGIS,无需重新训练现有模型。
- 设计了一个基于视觉-语言的安全评估模块和一个动作驱动的安全保证控制模块,将视觉感知和语义理解与安全保证的控制相结合。
- 建立了SafeLIBERO基准测试集,这是基于 LIBERO 数据集构建的,包含32个不同场景和1600个测试片段,用于评估安全性能。
- 大量实验表明,AEGIS 在避障率和任务成功率上均显著超越现有最优基线模型。
- 公开了代码、模型和基准数据集,以促进可重复性和未来研究。
Card 04
方法描述
方法描述
- 提出的 VLSA 架构在标准 VLA 模型的基础上,增加了一个安全约束层。
- 核心方法 AEGIS 包含两个模块:
1. 视觉-语言安全评估模块:使用视觉-语言模型 和 GroundingDINO 目标检测器,结合任务指令和视觉观察,识别并定位场景中最可能造成碰撞的障碍物,并获取其三维点云。
2. 动作驱动的安全保证控制模块:将机器人的末端执行器和障碍物建模为椭球体。利用 CBF 公式将动作调整问题构建为一个凸二次规划问题,实时求解以产生安全的控制输入,并提供理论安全保证。
Card 05
数据集与资源
数据集与资源
- 使用的数据集:基于 LIBERO 数据集构建的 SafeLIBERO 基准测试集。
- 模型:以最先进的流匹配 VLA 模型 π0.5 作为基础策略。使用 GLM-4.5V 模型进行安全评估。
- 训练资源:实验在工作站上进行,配备双 NVIDIA GeForce RTX 4090 GPU。
Card 06
评估与结果
评估与结果
- 评估环境:SafeLIBERO 基准测试,包含空间、目标、物体和长程四个任务套件。
- 主要评估指标:避碰率、任务成功率 和执行时间步数。
- 关键实验结果:与 OpenVLA-OFT 和原始 π0.5 相比,AEGIS 在平均避碰率上提升了 59.16%(达到77.85%),平均任务成功率提升了 17.25%(达到68.13%)。同时,AEGIS 的执行效率(ETS)也最高。实验验证了安全约束层具有理论保证且计算开销极小(仅占控制循环总延迟的约1.86%)。