一眼看懂
封面预览
提出 WAM-Diff,一个用于端到端自动驾驶的 Vision-Language-Action 框架,首次探索离散掩码扩散模型用于轨迹生成。
- 提出 WAM-Diff,一个用于端到端自动驾驶的 Vision-Language-Action 框架,首次探索离散掩码扩散模型用于轨迹生成。
- 旨在解决自动驾驶中轨迹生成问题,克服自回归模型固有的从左到右解码限制,支持灵活的、场景感知的解码策略。
- 核心目标是将多模态传感器输入和语言指令集成到一个统一模型中,以生成规划和控制的轨迹序列。
Card 01
研究单位
研究单位
- Fudan University
- Yinwang Intelligent Technology Co., Ltd
Card 02
论文概述
论文概述
- 提出 WAM-Diff,一个用于端到端自动驾驶的 Vision-Language-Action 框架,首次探索离散掩码扩散模型用于轨迹生成。
- 旨在解决自动驾驶中轨迹生成问题,克服自回归模型固有的从左到右解码限制,支持灵活的、场景感知的解码策略。
- 核心目标是将多模态传感器输入和语言指令集成到一个统一模型中,以生成规划和控制的轨迹序列。
Card 03
核心贡献
核心贡献
- 系统地将掩码扩散模型适配于自动驾驶场景,提出一种混合离散动作标记化方案,支持灵活的、非因果的解码顺序。
- 通过集成基于 LoRA 的稀疏混合专家架构 来扩展模型容量,并在运动预测和面向驾驶的视觉问答上进行联合训练,以提升运动规划能力。
- 引入针对 MoE 框架的在线强化学习方法——组序列策略优化,以优化基于仿真的序列级驾驶奖励(安全性、舒适度、进度等)。
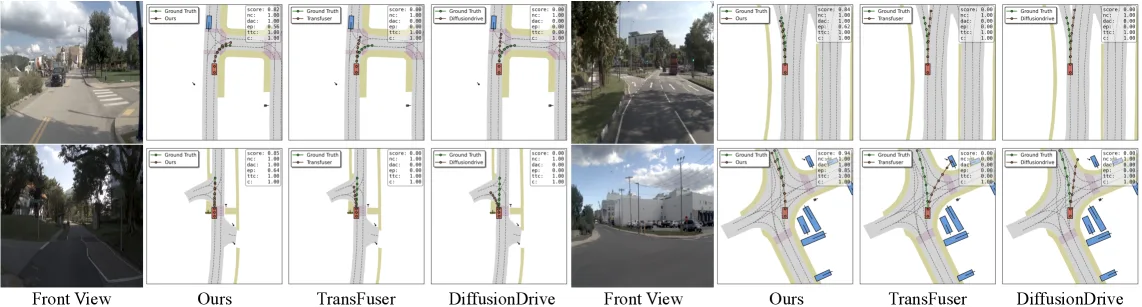
- 所提出的框架在 NAVSIM 和 nuScenes 基准测试中达到了领先的性能,展示了掩码扩散在自动驾驶领域的有效性。
Card 04
方法描述
方法描述
- 使用离散掩码扩散作为解码器,将未来轨迹生成为离散标记序列的迭代填充过程。
- 关键技术包括:混合标记化(数值路径点与语义文本交错)、灵活的再掩码调度(随机、因果、反因果)以控制解码顺序、基于 LoRA 的稀疏 MoE 主干网络以扩展容量、以及用于策略优化的 GSPO 强化学习算法。
- 主要创新点在于将掩码扩散的双向并行解码能力应用于轨迹生成,并结合 MoE 和 在线强化学习,超越了自回归和连续扩散策略的限制。
Card 05
数据集与资源
数据集与资源
- 使用的数据集包括:NAVSIM-v1/v2 和 nuScenes。
- 模型规模和参数量:基于 Llada-V 多模态主干,集成包含 64 个专家的稀疏 MoE。模型总参数量为 8.4B,其中 MoE 部分仅增加 0.5B,推理时激活约 0.05B 参数。
- 训练资源:在 4 x 8 Ascend 910B NPUs 上进行训练。
Card 06
评估与结果
评估与结果
- 评估环境和基准:在 NAVSIM-v1/v2 和 nuScenes 自动驾驶仿真基准上进行评估。
- 主要评估指标:PDMS(规划驾驶指标得分)、EPDMS(扩展规划驾驶指标得分),以及细分的 NC(无碰撞)、DAC(可驾驶区域合规)、TTC(碰撞时间)、Comf.(舒适度)、EP(自我进度)等。
- 关键实验结果:在 NAVSIM-v1 上获得 91.0 PDMS,在 NAVSIM-v2 上获得 89.7 EPDMS,均达到或超越了当前最先进的自回归基线方法。消融实验证实了 MoE、GSPO 和灵活解码调度的有效性。