一眼看懂
封面预览
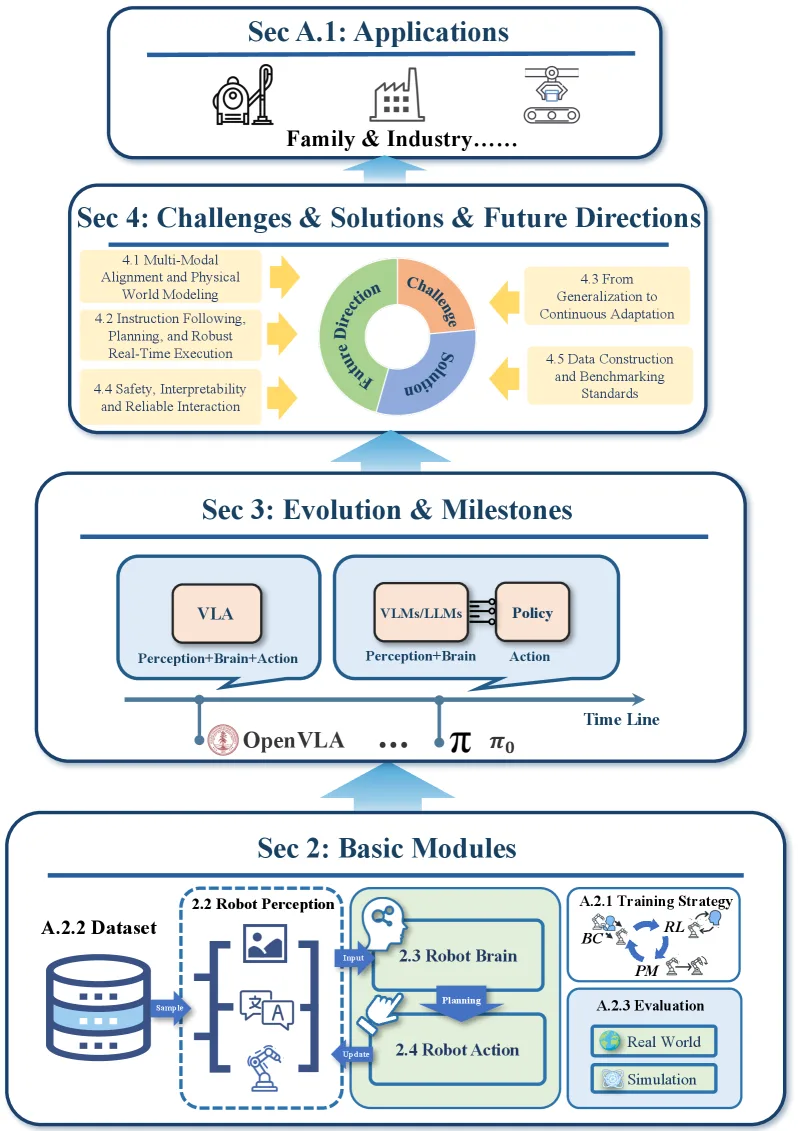
本文是一篇关于Vision-Language-Action (VLA) 模型的综合性综述论文,系统性地分析了VLA领域从基础模块到核心挑战的完…
- 本文是一篇关于Vision-Language-Action (VLA) 模型的综合性综述论文,系统性地分析了VLA领域从基础模块到核心挑战的完…
- 论文采用独特的金字塔结构组织内容:从Basic Modules(基础模块)出发,经过Evolution & Milestones(发展历程与里…
- 旨在解决现有综述的两个关键缺口:将研究挑战置于核心位置进行深度结构化分析,以及提供符合研究者自然学习路径的渐进式知识组织方式
Card 01
研究单位
研究单位
- IROOTECH TECHNOLOGY
- Wolf 1069 b Lab, Sany Group
- King's College London, Department of Engineering
- Hong Kong Polytechnic University
- Technische Universität Darmstadt, Computer Science Department
- University of Agder (UiA), Department of ICT and Center for AI Research
- Imperial College London, Department of Computing
Card 02
论文概述
论文概述
- 本文是一篇关于Vision-Language-Action (VLA) 模型的综合性综述论文,系统性地分析了VLA领域从基础模块到核心挑战的完整研究图景
- 论文采用独特的金字塔结构组织内容:从Basic Modules(基础模块)出发,经过Evolution & Milestones(发展历程与里程碑),最终深入探讨Challenges & Solutions & Future Directions(挑战、解决方案与未来方向)
- 旨在解决现有综述的两个关键缺口:将研究挑战置于核心位置进行深度结构化分析,以及提供符合研究者自然学习路径的渐进式知识组织方式
Card 03
核心贡献
核心贡献
- 系统性地解构了VLA模型的三大核心模块:Robot Perception(感知)、Robot Brain(决策大脑)、Robot Action(动作执行),涵盖视觉编码器、语言编码器、本体感受编码器、Transformer/Diffusion/VLM架构以及动作表示与解码等关键技术
- 梳理了VLA领域从2017年至2025年的完整发展脉络,识别出关键里程碑模型如RT-2、PaLM-E、Diffusion Policy、OpenVLA、π₀、GR-2、π₀.₅等
- 深度分析了五大核心挑战:Multi-Modal Alignment and Physical World Modeling(多模态对齐与物理世界建模)、Instruction Following, Planning, and Robust Real-Time Execution(指令遵循、规划与鲁棒实时执行)、From Generalization to Continuous Adaptation(从泛化到持续适应)、Safety, Interpretability and Reliable Interaction(安全、可解释性与可靠交互)、Data Construction and Benchmarking Standards(数据构建与评测标准)
- 针对每个挑战提供了细粒度的子问题分解、现有解决方案对比以及可操作的未来研究方向
- 构建了"活文档"形式的持续更新机制,通过项目页面跟踪领域前沿进展
Card 04
方法描述
方法描述
- 采用文献综述与系统性分析方法,对VLA领域的技术发展进行全景式梳理
- 提出层次化分析框架:将复杂挑战分解为可管理的子问题(如多模态对齐挑战分解为Vision-Language Gap、Vision-Language-Action Gap、Multi-modal Sensory Fusion三个层次)
- 创新性地采用发展路线图式的叙事结构,模拟研究者从入门到精通的自然学习曲线
- 对每个技术方向进行多维度对比分析:包括架构设计(CNN vs ViT vs VLM)、训练范式(模仿学习 vs 强化学习)、动作表示(离散 vs 连续 vs 混合)、解码策略(自回归 vs 非自回归 vs 混合)等
- 强调跨模态融合机制:如SigLIP+DINOv2混合视觉编码、语言对齐的视觉特征提取、触觉/力觉等多模态感知整合
Card 05
数据集与资源
数据集与资源
- 涵盖Open X-Embodiment (OXE):大规模跨机器人数据集,约800k机器人轨迹
- AgiBot World:显式技能标注与隐式行为压缩相结合的数据集
- GR系列数据集:基于大规模人类第一视角视频(如Ego4D)的预训练数据
- 1.5M-EO-Data:EO-1模型使用的150万规模数据集
- 仿真环境:ManiSkill3等支持GPU并行渲染的物理仿真平台
- 模型规模覆盖从77M参数(Evo-1)到数十亿参数(RDT-1B、GR-2等)的广泛范围
Card 06
评估与结果
评估与结果
- 评估基准涵盖VLN(视觉语言导航)、ALFRED、ALFWorld、BEHAVIOR等经典具身智能评测
- 关键性能指标包括:任务成功率、跨形态泛化能力、实时推理延迟、样本效率、持续学习能力等
- OpenVLA作为首个完全开源的7B参数VLA模型,显著降低了大规模研究与部署门槛
- π₀.₅通过层次化Transformer实现高层推理与底层控制的统一,无需目标特定机器人数据即可完成长时程操作
- GEN-0提供了机器人领域缩放律的早期证据,表明大规模交互数据可实现跨形态泛化的相变
- 实时性优化方面,SARA-RT、RoboMamba、OpenVLA-OFT等方法在保持性能的同时显著降低推理延迟