一眼看懂
封面预览
论文提出 LCDrive(Latent-CoT-Drive),一种用于端到端自动驾驶的视觉-语言-动作(VLA)模型,通过潜在空间中的思维链(…
- 论文提出 LCDrive(Latent-CoT-Drive),一种用于端到端自动驾驶的视觉-语言-动作(VLA)模型,通过潜在空间中的思维链(…
- 核心动机:自然语言不适合表达驾驶中的时空几何和多智能体交互,且文本推理引入显著延迟;潜在推理更高效且与动作对齐
- 提出 LCDrive 框架,在潜在空间中进行思维链推理,使用与动作相同的词汇表表示推理过程
Card 01
研究单位
研究单位
- UT Austin(德克萨斯大学奥斯汀分校)
- NVIDIA(英伟达)
- Stanford University(斯坦福大学)
Card 02
论文概述
论文概述
- 论文提出 LCDrive(Latent-CoT-Drive),一种用于端到端自动驾驶的视觉-语言-动作(VLA)模型,通过潜在空间中的思维链(Latent Chain-of-Thought)推理替代传统的自然语言推理
- 核心动机:自然语言不适合表达驾驶中的时空几何和多智能体交互,且文本推理引入显著延迟;潜在推理更高效且与动作对齐
Card 03
核心贡献
核心贡献
- 提出 LCDrive 框架,在潜在空间中进行思维链推理,使用与动作相同的词汇表表示推理过程
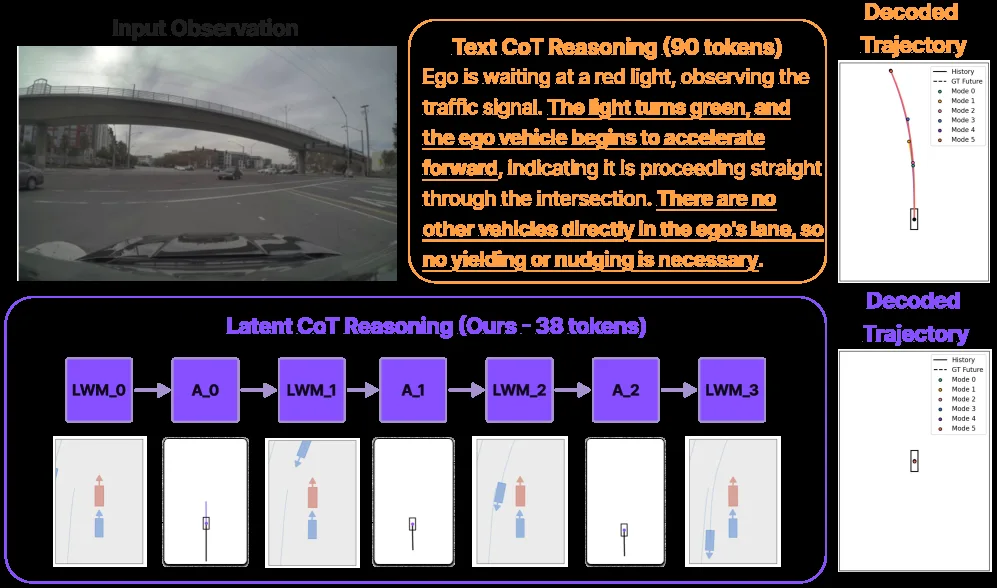
- 设计交错式潜在推理机制:交替生成动作提议令牌(action-proposal tokens)和潜在世界模型令牌(LWM tokens),实现反事实未来模拟
- 开发三阶段训练流程:非推理预训练 → 潜在CoT冷启动(监督学习)→ 闭环强化学习优化
- 证明潜在CoT比文本CoT具有更快的推理速度、更高的轨迹质量,且从RL中获得更大提升
Card 04
方法描述
方法描述
- 潜在世界模型(LWM):编码自车周围智能体的1秒时序窗口状态,压缩为2个紧凑令牌
- 推理令牌结构:每个推理分支为交错序列
[A₀, LWM₁, A₁, LWM₂, ..., A_{K-1}, LWM_K],其中A为1秒动作块(10个令牌),LWM为预测的未来世界状态 - 多分支推理:默认使用B=2个分支,顺序生成以利用先前推理上下文
- 三阶段训练:
- Stage 0:训练非推理VLA基线
- Stage 1:用冻结基线生成动作提议,结合GT未来构建监督信号,训练潜在CoT结构
- Stage 2:使用GRPO(Group Relative Policy Optimization)进行强化学习,以ADE为奖励优化推理和动作生成
Card 05
数据集与资源
数据集与资源
- 数据集:PhysicalAI-AV 数据集,1727小时真实驾驶数据,使用场景平衡子集(87小时训练,53小时验证,23,758个验证片段)
- 模型架构:Qwen3-0.5B 作为语言-动作模块,DINOv2 ViT作为图像编码器
- 训练配置:Stage 0(100k步,batch size 128),Stage 1(10k步),Stage 2 GRPO(3k步,group size 8)
- 推理深度:K=5(5个1秒推理步),B=2(2个分支)
Card 06
评估与结果
评估与结果
- 评估指标:ADE(平均位移误差)、OffRoad(驶离道路比例)、Coll(碰撞比例)、Corner Dist(角点距离)
- 主要结果(Table 1):
- LCDrive(Latent CoT + RL):ADE 1.626,OffRoad₂.₅ 1.219,Coll₅.₀ 0.836
- 优于非推理基线(ADE 1.762)和文本CoT基线(ADE 1.650)
- 使用GT LWM的Latent CoT* + RL达到最佳性能(ADE 1.197)
- 场景分析(Table 2):在复杂交互场景(Intersection Navigation、Merging、Turning Maneuver)中优势显著,RL对潜在CoT的提升效果明显大于基线
- 推理效率:潜在CoT比文本CoT显著减少令牌数量,推理速度更快