一眼看懂
封面预览
论文提出 PosA-VLA 框架,旨在解决现有视觉-语言-动作模型无法生成一致、精确且面向目标的动作的问题。
- 论文提出 PosA-VLA 框架,旨在解决现有视觉-语言-动作模型无法生成一致、精确且面向目标的动作的问题。
- 研究指出,现有模型的缺陷源于其“空间均匀感知场”,导致模型易被无关物体分心,从而产生冗余或不稳定的运动轨迹。
- 目标是通过位姿条件监督锚定视觉注意力,引导模型感知任务相关区域,从而提升动作生成的精度和效率。
Card 01
研究单位
研究单位
- MBZUAI
- AI2 Robotics
- The University of Sydney
- The University of Melbourne
Card 02
论文概述
论文概述
- 论文提出 PosA-VLA 框架,旨在解决现有视觉-语言-动作模型无法生成一致、精确且面向目标的动作的问题。
- 研究指出,现有模型的缺陷源于其“空间均匀感知场”,导致模型易被无关物体分心,从而产生冗余或不稳定的运动轨迹。
- 目标是通过位姿条件监督锚定视觉注意力,引导模型感知任务相关区域,从而提升动作生成的精度和效率。
Card 03
核心贡献
核心贡献
- 对现有VLA模型动作不一致的现象进行了实证分析,将其根源归结于模型的空间均匀感知场。
- 提出了 PosA-VLA 框架,通过位姿条件锚点注意力机制,显式地将机器人末端执行器的位姿与视觉感知关联,以锚定任务相关区域。
- 在多个机器人操作基准测试中实现了更高的成功率、更平滑的轨迹和更快的推理速度,同时保持了在环境变化下的强泛化能力。
Card 04
方法描述
方法描述
- 提出位姿条件锚点生成方法,生成两种互补的注意力锚点:任务相关锚点和末端执行器锚点,前者标记交互发生的关键区域,后者追踪每个时间步的末端执行器位置。
- 设计位姿条件锚点损失,由空间注意力损失和批量对比损失组成,用于监督模型关注正确的空间区域并增强跨样本一致性。
- 使用 Flow Matching Transformer 进行动作序列预测,以高效、平滑的方式生成连续动作块。
Card 05
数据集与资源
数据集与资源
- 使用 AlphaBot 1s 机器人平台采集的真实世界数据集,针对不同物体,每个物体收集 200条 演示轨迹。
- 模型训练在单个 NVIDIA A100 GPU 上进行,推理在 NVIDIA RTX 4090 GPU 上进行。
- 使用 CLIP-Base 作为文本和图像编码器,DINOv2-Base 作为密集视觉骨干网络。
Card 06
评估与结果
评估与结果
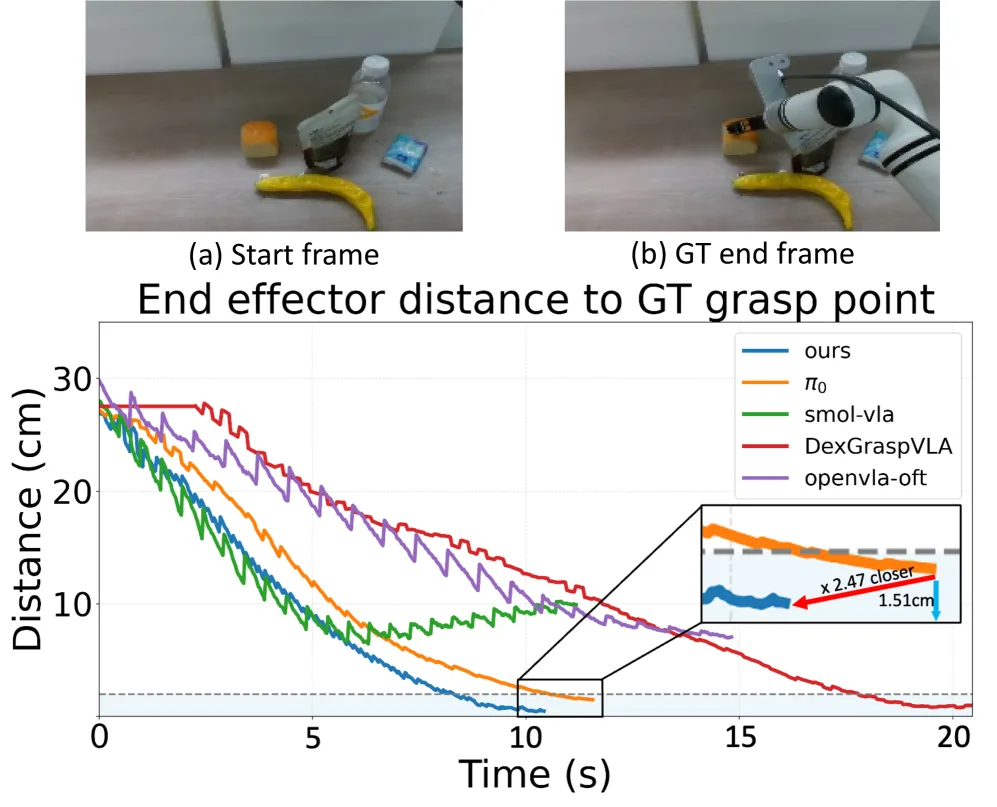
- 在真实世界的抓取任务上进行评估,测试环境包括基础设置、未见背景、未见光照、干扰物体、未见物体等多种条件。
- 主要评估指标为任务成功率。PosA-VLA 在平均成功率上达到 55.3%,显著高于其他基线模型(如DexGraspVLA的50.5%,π₀的31.6%)。
- 在长期操作任务(开盖并放入物体)中,PosA-VLA 的整体成功率达到 61.1%,远超其他模型。
- 效率分析显示,PosA-VLA 训练仅需 20 GPU小时,平均动作推理时间为 24.5ms,总执行步骤最少,总执行时间最短,展现出卓越的效率。