一眼看懂
封面预览
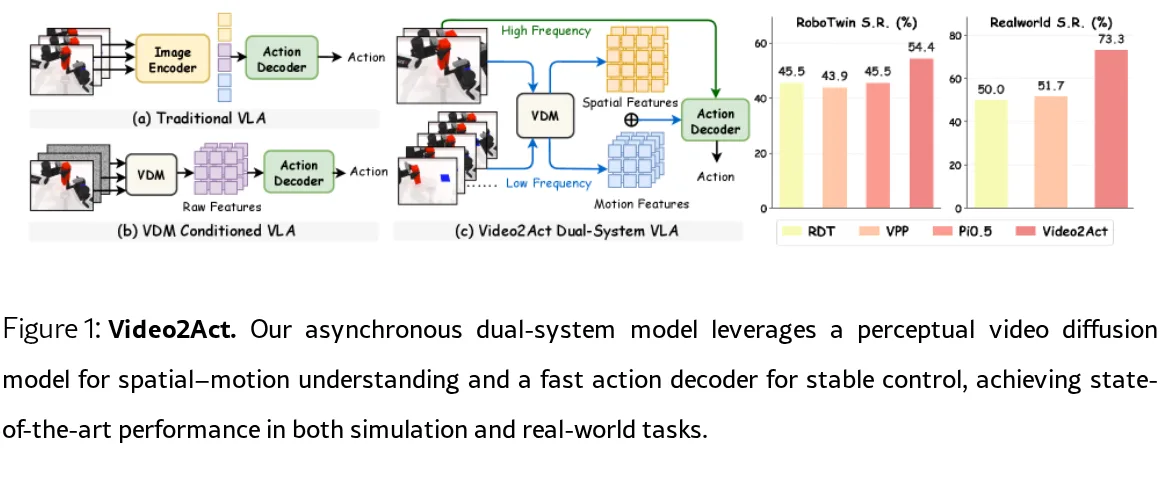
论文提出了 Video2Act,一种视觉-语言-动作(VLA)框架,利用视频扩散模型(VDM)增强机器人策略学习。
- 论文提出了 Video2Act,一种视觉-语言-动作(VLA)框架,利用视频扩散模型(VDM)增强机器人策略学习。
- 旨在解决现有方法未充分利用 VDM 中隐含的空间结构和运动动态表示的问题,以实现更鲁棒的感知和动力学建模。
- 构建了一个异步双系统架构,将慢速感知模块(System 2)与快速执行模块(System 1)结合,实现稳定且高频的动作生成。
Card 01
研究单位
研究单位
- Peking University(北京大学多媒体信息处理国家重点实验室)
- AI2Robotics
- Hong Kong University of Science and Technology(香港科技大学)
Card 02
论文概述
论文概述
- 论文提出了 Video2Act,一种视觉-语言-动作(VLA)框架,利用视频扩散模型(VDM)增强机器人策略学习。
- 旨在解决现有方法未充分利用 VDM 中隐含的空间结构和运动动态表示的问题,以实现更鲁棒的感知和动力学建模。
- 构建了一个异步双系统架构,将慢速感知模块(System 2)与快速执行模块(System 1)结合,实现稳定且高频的动作生成。
Card 03
核心贡献
核心贡献
- 对机器人场景下的 VDM 表征进行了系统分析,揭示了其捕捉稳定空间结构和运动一致性特征的能力。
- 提出了显式提取空间-运动表征的方法,利用 Sobel 算子提取空间边界,利用 FFT 捕捉运动动态。
- 设计了表征驱动的异步双系统架构,利用低频的 VDM 特征指导高频的 DiT 动作专家进行实时控制。
- 在仿真和真实世界实验中均取得了最先进(SOTA)的性能,验证了方法的有效性。
Card 04
方法描述
方法描述
- 采用 Hunyuan Video Diffusion Model 作为慢速系统(System 2),通过反演轨迹提取特征。
- 设计双流输入:高分辨率短时序图像用于空间结构提取,常规分辨率长时序图像用于运动动态提取。
- 在潜空间应用 Sobel 空间滤波算子提取前景边界,应用 快速傅里叶变换(FFT)提取帧间运动变化。
- 使用 1B 参数的 Diffusion Transformer (DiT) 作为快速系统(System 1),通过交叉注意力机制融合提取的表征与实时视觉 Token,生成动作序列。
Card 05
数据集与资源
数据集与资源
- 仿真环境:RoboTwin 1.0 和 RoboTwin 2.0 基准测试,包含 12 项双臂操作任务。
- 真实环境:基于 Agilex Cobot Magic (ALOHA) 平台收集的 6 项任务数据集,每项任务包含 100 次演示。
- 硬件资源:使用 NVIDIA 4090 GPU 进行真实世界推理。
Card 06
评估与结果
评估与结果
- 对比基线包括 Diffusion Policy、ACT、RDT-1B、$\pi_0$、$\pi_{0.5}$、VPDD 和 VPP。
- 在仿真实验中,平均成功率分别达到 54.6% (RoboTwin 1.0) 和 54.1% (RoboTwin 2.0),超越之前最优方法 8.9%。
- 在真实世界实验中,平均成功率达到 73.3%,超越之前最优方法 21.7%。
- 实验表明该方法在高精度协调和复杂动态任务中表现优异,并具备良好的泛化能力。