一眼看懂
封面预览
研究了视觉-语言-动作(VLA)模型在新颖相机视角和视觉扰动下性能急剧下降的问题
- 研究了视觉-语言-动作(VLA)模型在新颖相机视角和视觉扰动下性能急剧下降的问题
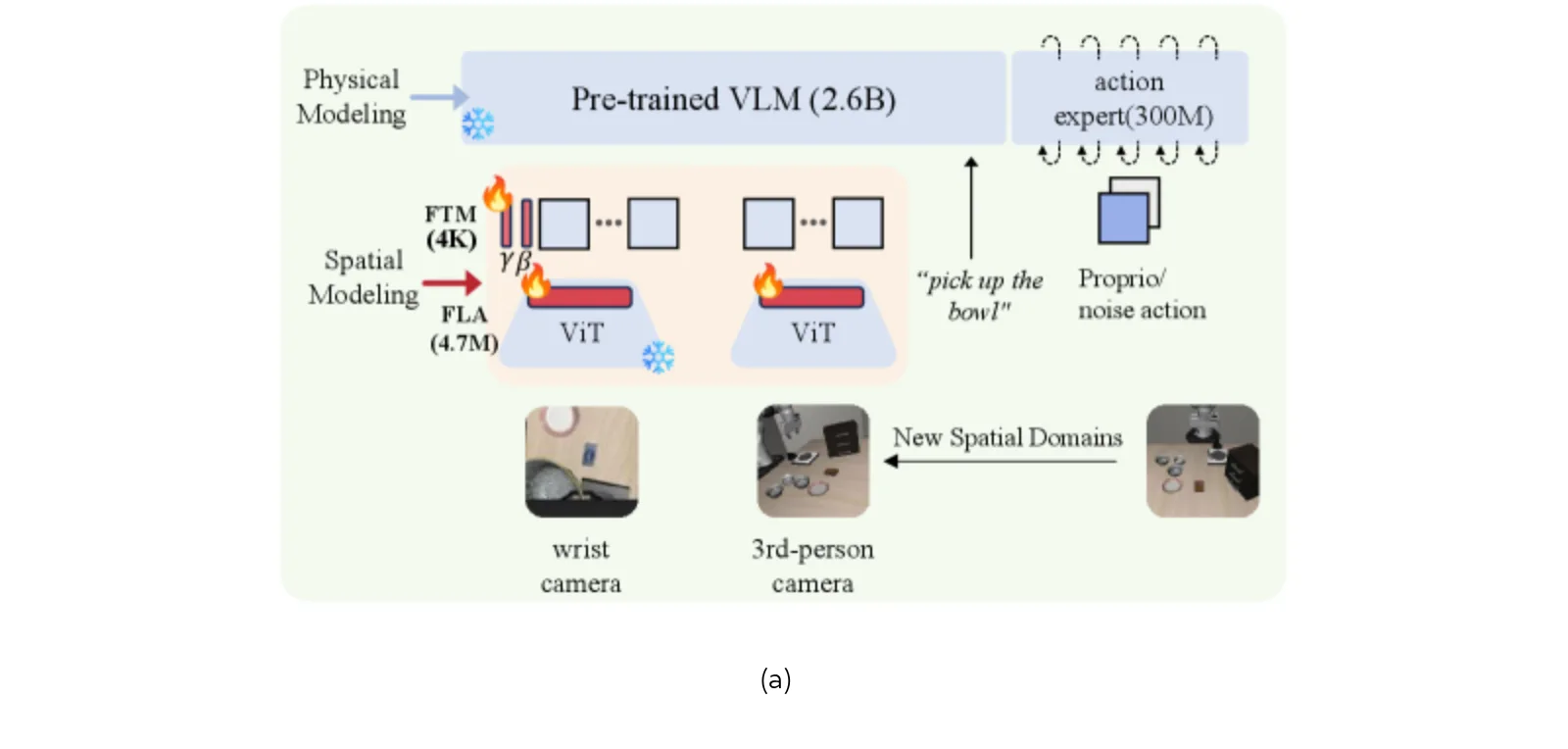
- 提出性能下降主要源于 Spatial Modeling(空间建模) 的表示错位,而非 Physical Modeling(物理建模) 的能力不足
- 提出了一种单次适应框架,通过极轻量级的参数更新重新校准视觉表示,以恢复模型的泛化能力
Card 01
研究单位
研究单位
- Sun Yat-sen University
- Guangdong Key Laboratory of Big Data Analysis and Processing
- X-Era AI Lab
Card 02
论文概述
论文概述
- 研究了视觉-语言-动作(VLA)模型在新颖相机视角和视觉扰动下性能急剧下降的问题
- 提出性能下降主要源于 Spatial Modeling(空间建模) 的表示错位,而非 Physical Modeling(物理建模) 的能力不足
- 提出了一种单次适应框架,通过极轻量级的参数更新重新校准视觉表示,以恢复模型的泛化能力
Card 03
核心贡献
核心贡献
- 重新评估了预训练 VLA 模型的鲁棒性,揭示了视觉扰动下的性能瓶颈在于视觉编码器的表示漂移
- 提出了 Feature Token Modulation (FTM),仅需 4K 参数即可通过全局仿射变换显著提升视角鲁棒性
- 提出了 Feature Linear Adaptation (FLA),通过对 ViT 编码器的低秩更新,以极低的成本达到了全量微调的效果
- 构建了 Libero-V 基准测试,整合了多种视觉扰动类型以系统评估模型鲁棒性
Card 04
方法描述
方法描述
- Feature Token Modulation (FTM):在视觉 Token 输出层应用全局仿射变换,通过两个可学习参数向量 $\gamma$ 和 $\beta$ 对特征分布进行缩放和偏移
- Feature Linear Adaptation (FLA):借鉴 LoRA 思想,仅在 ViT 编码器内部的线性层引入低秩分解矩阵进行微调,保持主干网络冻结
- 方法基于 $\pi_{0.5}$ 模型,通过最小化干预视觉路径来修复空间表示错位,无需重新训练整个策略模型
Card 05
数据集与资源
数据集与资源
- Libero-V Benchmark:基于 LIBERO 和 Libero-Plus 构建,包含相机视角变化、光照变化、背景纹理变化和图像噪声四种视觉扰动
- 基础模型:$\pi_{0.5}$ (Vision-Language-Action policy) 及其 SigLIP 视觉骨干网络
- 训练资源:单张 NVIDIA A100 GPU (80GB VRAM)
Card 06
评估与结果
评估与结果
- 评估环境:LIBERO 模拟环境及搭载 Franka Emika 机械臂的真实世界环境
- 评估指标:成功率
- 关键结果:
- 在新颖相机视角下,FLA 方法仅用 4.7M 参数(相比 LoRA 的 467M 参数减少了 99 倍)达到了 90.8% 的成功率,超越了 LoRA 微调基线(90.3%)
- FTM 方法仅用 4K 参数将零样本准确率从 48.5% 提升至 87.1%
- 在 Libero-V 基准上,该方法在光照、纹理和噪声扰动下均表现出优异的鲁棒性