一眼看懂
封面预览
论文提出了 SwiftVLA,旨在解决视觉-语言-动作(VLA)模型因参数量大导致部署困难,以及轻量级模型时空推理能力不足的问题。
- 论文提出了 SwiftVLA,旨在解决视觉-语言-动作(VLA)模型因参数量大导致部署困难,以及轻量级模型时空推理能力不足的问题。
- 该方法通过引入 4D 时空特征和掩码重构策略,在保持轻量级设计效率的同时,增强了模型的空间推理和动作规划能力。
- 目标是在推理阶段仅使用 2D 输入即可获得接近使用完整 4D 输入的性能,实现对大参数量模型的性能追赶。
Card 01
研究单位
研究单位
- GigaAI
- Peking University
- Moxin (Huzhou) Technology Co., Ltd.
- Tsinghua University
- X-Humanoid
Card 02
论文概述
论文概述
- 论文提出了 SwiftVLA,旨在解决视觉-语言-动作(VLA)模型因参数量大导致部署困难,以及轻量级模型时空推理能力不足的问题。
- 该方法通过引入 4D 时空特征和掩码重构策略,在保持轻量级设计效率的同时,增强了模型的空间推理和动作规划能力。
- 目标是在推理阶段仅使用 2D 输入即可获得接近使用完整 4D 输入的性能,实现对大参数量模型的性能追赶。
Card 03
核心贡献
核心贡献
- 提出了 SwiftVLA 架构,以极小的计算开销将 4D 时空信息集成到轻量级 VLA 模型中。
- 设计了 Fusion Tokens(融合令牌),通过未来轨迹预测监督,统一了 2D 和 4D 特征的表示,解决了轻量级 VLM 跨模态融合难的问题。
- 提出了掩码与重构策略,在训练时随机遮蔽并重构特征,使模型在推理时移除 4D 分支仍能保持高性能。
- 实验表明,该模型性能媲美参数量大 7x 的模型,且在边缘设备上速度快 18x,内存占用减少 12x。
Card 04
方法描述
方法描述
- 模型架构基于轻量级 VLM 骨干网络 SmolVLM,并集成了一个动作专家模块。
- 利用预训练的 4D visual geometry transformer(StreamVGGT)和时间缓存机制,从 2D 图像中增量提取 4D 特征。
- 引入可学习的 Fusion Tokens 在 VLM 内部交互 2D 与 4D 特征,利用末端执行器的未来轨迹作为监督信号进行训练。
- 训练阶段采用掩码与重构策略,随机遮蔽 2D 或 4D 输入并要求模型重构,以此蒸馏时空知识,允许在推理时丢弃 4D 分支。
Card 05
数据集与资源
数据集与资源
- 仿真环境数据集:RoboTwin 2.0 和 LIBERO 基准测试。
- 真实世界实验:使用 AgileX PiPER 机械臂执行清理桌面、堆叠碗等任务。
- 模型规模:总参数量约 450M(其中动作专家约 100M)。
- 硬件资源:真实世界实验使用 NVIDIA RTX 4090,边缘部署评估使用 NVIDIA Jetson Orin。
Card 06
评估与结果
评估与结果
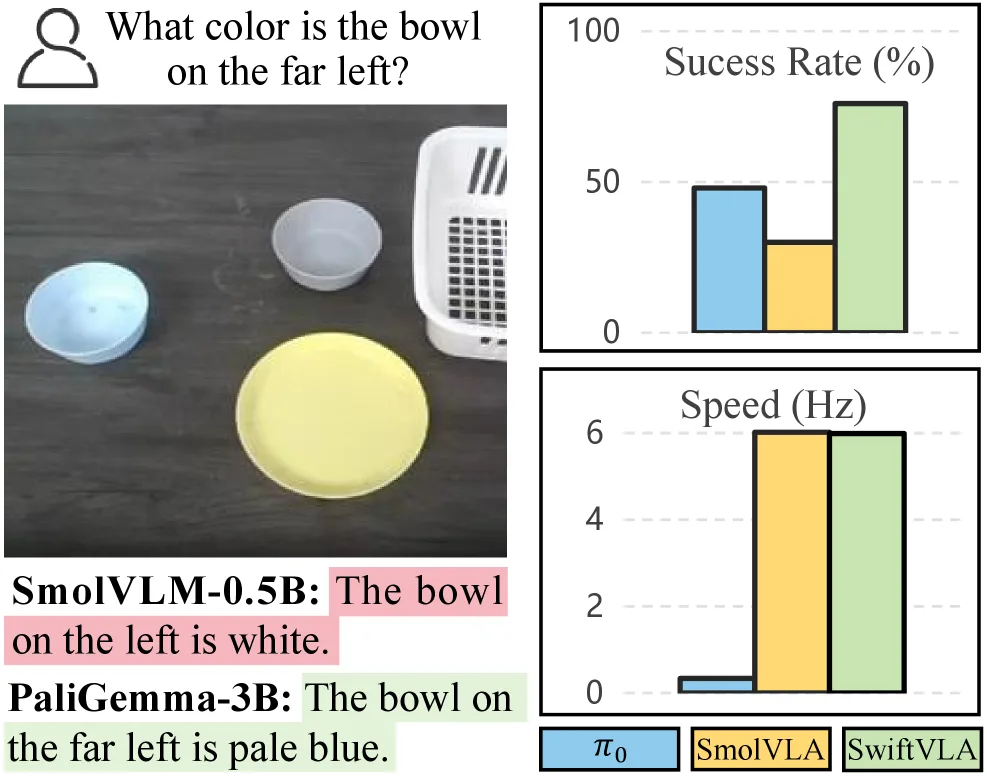
- 在仿真和真实环境中,SwiftVLA 显著优于 SmolVLA 等轻量级基线模型。
- 在 LIBERO 和 RoboTwin 2.0 基准上,性能可媲美参数量是其 7 倍的 $\pi_{0}$ 模型。
- 在 NVIDIA Jetson Orin 边缘设备上,推理速度比 $\pi_{0}$ 快 18 倍,内存占用减少 12 倍,同时保持了更高的任务成功率。