一眼看懂
封面预览
论文提出了 LatBot,这是一个通用的潜在动作学习框架,旨在从大规模物体操作视频中学习可迁移的潜在动作,以增强下游机器人任务的泛化能力。
- 论文提出了 LatBot,这是一个通用的潜在动作学习框架,旨在从大规模物体操作视频中学习可迁移的潜在动作,以增强下游机器人任务的泛化能力。
- 解决了现有方法主要依赖视觉重建目标而忽略物理先验,以及无法有效区分机器人主动运动与环境被动变化的问题。
- 通过将潜在动作蒸馏到视觉-语言-动作(VLA)模型中,实现了在模拟环境和真实机器人上的优异性能,特别是在极少样本(如10条轨迹)下的强泛化能力。
Card 01
研究单位
研究单位
- 中国科学院微电子研究所
- 中国科学院大学
- 微软研究院
Card 02
论文概述
论文概述
- 论文提出了 LatBot,这是一个通用的潜在动作学习框架,旨在从大规模物体操作视频中学习可迁移的潜在动作,以增强下游机器人任务的泛化能力。
- 解决了现有方法主要依赖视觉重建目标而忽略物理先验,以及无法有效区分机器人主动运动与环境被动变化的问题。
- 通过将潜在动作蒸馏到视觉-语言-动作(VLA)模型中,实现了在模拟环境和真实机器人上的优异性能,特别是在极少样本(如10条轨迹)下的强泛化能力。
Card 03
核心贡献
核心贡献
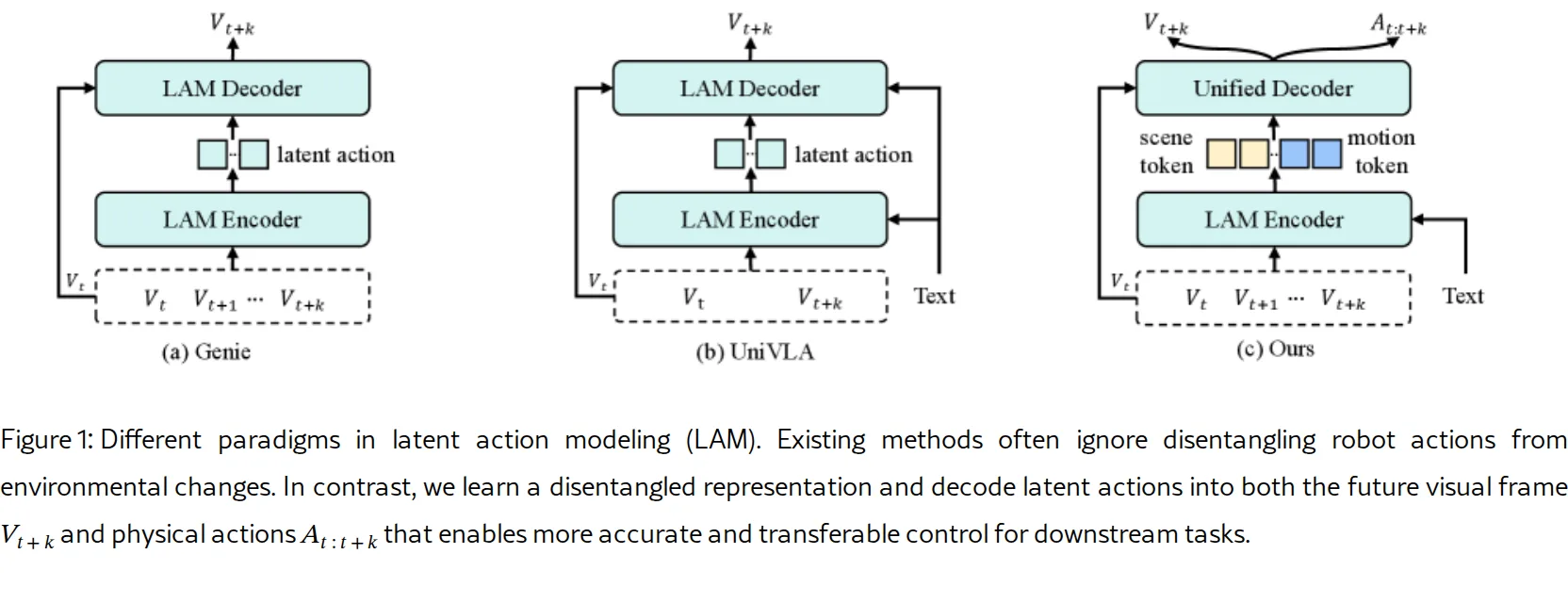
- 提出了 解耦潜在动作表示,将潜在动作分解为 运动Token(捕捉机器人主动运动)和 场景Token(捕捉环境被动变化),有效过滤了无关动态。
- 设计了 统一潜在动作解码器,联合优化未来帧重建和动作序列预测,使模型能够捕获距离和方向等物理先验。
- 提出了一种针对 VLA 模型的 知识蒸馏策略,包含潜在动作对齐损失和推理保留损失,将运动知识迁移到 VLM 中同时保持其推理能力。
- 在真实机器人实验中展示了极强的 少样本迁移能力,仅使用 10 条真实轨迹即可完成具有挑战性的操作任务。
Card 04
方法描述
方法描述
- 框架包含两个主要阶段:潜在动作预训练和知识蒸馏。
- 在预训练阶段,利用预训练的 VLM(如 InternVL3.5)作为编码器,从多帧观测和任务指令中提取解耦的潜在动作表示。
- 使用从 SANA 初始化的统一解码器,通过双向交互融合场景和运动信息,联合预测未来视觉帧和帧间动作。
- 在蒸馏阶段,将教师模型(LAM)学到的潜在动作知识迁移到学生模型(VLA),通过 MSE 和 KL 散度对齐潜在表示,并使用下一词预测目标保留 VLM 的推理能力。
Card 05
数据集与资源
数据集与资源
- 使用的数据集包括 OXE、AgiBoT、DROID 和 EgoDex(人手操作数据集),总计约 100 万条视频片段。
- 模型方面,编码器默认使用 InternVL3.5-2B,解码器架构类似于 SANA-1.6B。
- 训练资源包括 16 台 NVIDIA A100 (40GB) GPU,预训练耗时 14 天,蒸馏阶段耗时 7 天。
Card 06
评估与结果
评估与结果
- 评估环境包括模拟基准 SIMPLER(Google Robot 和 WidowX)和 LIBERO,以及真实世界的 Franka Robot。
- 主要评估指标为任务成功率。
- 在 SIMPLER 基准上,该方法在 Google Robot 和 WidowX 设置下均取得了最优的平均成功率(如 WidowX 上达到 87.5%),显著优于 $\pi_{0.5}$ 和 OpenVLA 等现有模型。
- 在 LIBERO 基准上,达到了 98.0% 的平均成功率。
- 在真实机器人实验中,该方法在少样本设置下表现卓越,例如在 10-shot 设置下,颜色辨别任务成功率达 60%,而基线模型失败率为 0%。