一眼看懂
封面预览
论文旨在解决 Vision-Language-Action (VLA) 模型在混合质量数据上训练后执行质量不一致的问题。
- 论文旨在解决 Vision-Language-Action (VLA) 模型在混合质量数据上训练后执行质量不一致的问题。
- 提出了一种解耦的优化框架,通过 Elegance Critic 和 Just-in-Time Intervention (JITI) 机制,在…
- 核心目标是让机器人控制不仅关注任务成功,还要关注动作执行的质量,即满足 Implicit Task Constraints (ITCs)。
Card 01
研究单位
研究单位
- Jilin University
- Microsoft Research Asia
Card 02
论文概述
论文概述
- 论文旨在解决 Vision-Language-Action (VLA) 模型在混合质量数据上训练后执行质量不一致的问题。
- 提出了一种解耦的优化框架,通过 Elegance Critic 和 Just-in-Time Intervention (JITI) 机制,在不重新训练基础策略的情况下提升机器人操作的优雅度。
- 核心目标是让机器人控制不仅关注任务成功,还要关注动作执行的质量,即满足 Implicit Task Constraints (ITCs)。
Card 03
核心贡献
核心贡献
- 形式化定义了 Elegant Execution,将其定义为对 Implicit Task Constraints (ITCs) 的可靠满足,超越了二元的成功标准。
- 构建了 LIBERO-Elegant Benchmark,这是一个用于评估操作执行质量的基准,包含明确的优雅度标准。
- 提出了一种非侵入式的优化框架,包含离线训练的 Elegance Critic 和推理时的 Just-in-Time Intervention (JITI) 机制。
- 在仿真和真实机器人环境中验证了方法的有效性,显著提升了执行质量。
Card 04
方法描述
方法描述
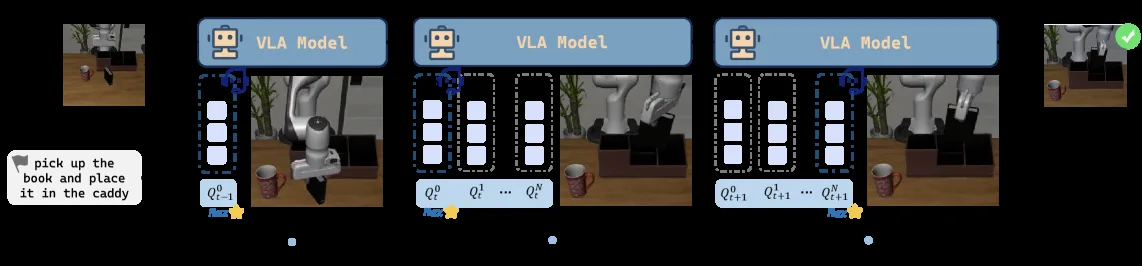
- 方法分为三个阶段:基础策略训练、优雅度评价器训练和即时干预。
- Stage 1:使用 Flow-matching 生成模型在混合质量数据上训练基础 VLA 策略,捕捉人类行为的整体分布。
- Stage 2:利用 LIBERO-Elegant 数据集的细粒度奖励标注,通过 Calibrated Q-Learning (Cal-QL) 算法离线训练 Elegance Critic,以评估动作的优雅度。
- Stage 3:提出 Just-in-Time Intervention (JITI) 算法,通过监控 Q 值的波动来识别关键决策时刻,仅在关键点进行多候选动作采样并选择最优动作。
Card 05
数据集与资源
数据集与资源
- 提出了 LIBERO-Elegant Benchmark,包含 8 个操作任务、327 个演示片段和约 52.7K 帧的数据。
- 基础模型包括 SmolVLA (450M) 和 Isaac GR00T N1.5 (3B),评价器使用了 SmolVLM2-256M-Video-Instruct 和 Eagle2-1B。
- 训练资源包括 NVIDIA RTX 5090 GPU 和 NVIDIA A40 GPU。
- 真实世界实验使用了 SO-100 机械臂。
Card 06
评估与结果
评估与结果
- 评估指标为 Elegant Success Rate (ESR),要求任务成功且满足所有优雅度约束。
- 在 LIBERO-Elegant 仿真基准上,结合 JITI 的 SmolVLA 平均 ESR 从 49.8% 提升至 67.2%,GR00T N1.5 从 46.0% 提升至 67.2%。
- 消融实验表明,JITI 机制比全时干预更高效,干预次数减少超过 60%。
- 在真实世界任务中,JITI 将 SO-100 机械臂的平均 ESR 从 34.3% 提升至 58.0%,证明了其有效性。