一眼看懂
封面预览
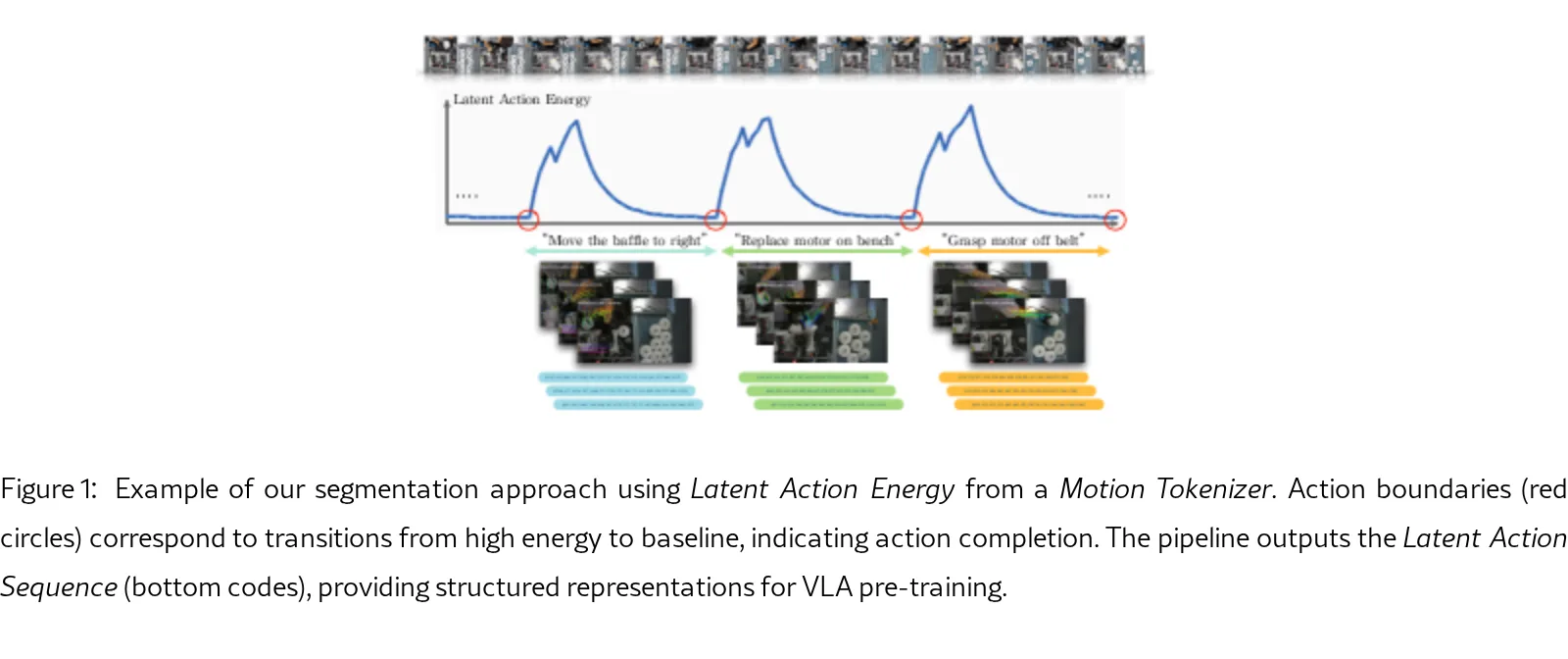
提出了一种名为 LAPS (Latent Action-based Primitive Segmentation) 的无监督框架,旨在从连续的…
- 提出了一种名为 LAPS (Latent Action-based Primitive Segmentation) 的无监督框架,旨在从连续的…
- 核心目标是利用被动观察的视频数据,自动发现和分割语义连贯的动作片段,并将其转化为适用于 VLA 预训练的结构化数据。
- 解决了工业环境中高质量标注数据获取成本高昂的瓶颈问题,实现了从非结构化视频到结构化动作词汇库的自动转化。
Card 01
研究单位
研究单位
- ShanghaiTech University(上海科技大学):School of Information Science and Technology
- Hangzhou Dianzi University(杭州电子科技大学):School of Automation
Card 02
论文概述
论文概述
- 提出了一种名为 LAPS (Latent Action-based Primitive Segmentation) 的无监督框架,旨在从连续的工业视频流中提取动作原语,以解决 VLA 模型预训练的数据稀缺问题。
- 核心目标是利用被动观察的视频数据,自动发现和分割语义连贯的动作片段,并将其转化为适用于 VLA 预训练的结构化数据。
- 解决了工业环境中高质量标注数据获取成本高昂的瓶颈问题,实现了从非结构化视频到结构化动作词汇库的自动转化。
Card 03
核心贡献
核心贡献
- 提出了 Latent Action Energy 这一新指标,用于在抽象的潜在动作空间中识别语义动作边界,区别于传统的像素级或光流变化检测。
- 构建了首个端到端自动化的数据处理管道,能够将长时工业视频转换为结构化的动作原语库,直接服务于工业 VLA 模型的潜在预训练。
- 在公开基准数据集和自有的真实工业电机装配数据集上进行了验证,证明了该方法在无监督动作分割任务上的有效性和可扩展性。
Card 04
方法描述
方法描述
- 运动追踪:利用 CoTracker 等点追踪器从原始视频中提取密集的运动轨迹关键点。
- 动作检测与分割:训练一个轻量级的 Motion Tokenizer 将关键点速度编码为潜在动作序列,并计算 Latent Action Energy(潜在动作能量),通过滞后控制器检测动作边界。
- 语义动作聚类:使用冻结参数的 Transformer(无需训练)对分割出的动作片段进行时间嵌入,随后利用 Cosine k-means 算法将动作原语聚类为语义类别。
Card 05
数据集与资源
数据集与资源
- GTEA:包含 28 个视频的厨房环境数据集。
- Breakfast:包含 1712 个视频的烹饪活动数据集。
- Industrial Motor Assembly Dataset:自采集的工业电机装配线数据集,包含约 10 小时的连续视频(顶视和外观察视角)。
- 模型训练资源:Motion Tokenizer 仅需轻量级训练(约 25 分钟)。
Card 06
评估与结果
评估与结果
- 评估基准:与 Optical Flow、ABD 和 OTAS 等无监督时序动作检测基线方法进行对比。
- 评估指标:使用边界 F1 分数(F1@2s, F1@5s)评估分割精度,使用 ICSS (Intra-Cluster Semantic Similarity) 评估聚类语义一致性。
- 关键结果:在工业数据集上,LAPS 的分割性能显著优于基线方法(F1@2s 达到 81.27% 和 81.93%,而基线最高仅约 40%);聚类结果显示出高语义一致性(ICSS 得分为 0.926)。