一眼看懂
封面预览
论文针对 Vision-Language-Action (VLA) 模型在实时机器人部署中因处理冗余视觉标记而导致的高计算开销问题。
- 论文针对 Vision-Language-Action (VLA) 模型在实时机器人部署中因处理冗余视觉标记而导致的高计算开销问题。
- 提出了 Compressor-VLA,一种新颖的混合指令条件标记压缩框架,旨在实现高效、任务导向的视觉信息压缩。
- 目标是在保留整体上下文和细粒度细节以实现精确动作的同时,显著降低计算成本,解决现有任务无关修剪方法的关键信息丢失问题。
Card 01
研究单位
研究单位
- 北京工业大学 信息科学与技术学院
- LiAuto Inc.
- 北京工业大学 计算智能与智能系统北京市重点实验室
Card 02
论文概述
论文概述
- 论文针对 Vision-Language-Action (VLA) 模型在实时机器人部署中因处理冗余视觉标记而导致的高计算开销问题。
- 提出了 Compressor-VLA,一种新颖的混合指令条件标记压缩框架,旨在实现高效、任务导向的视觉信息压缩。
- 目标是在保留整体上下文和细粒度细节以实现精确动作的同时,显著降低计算成本,解决现有任务无关修剪方法的关键信息丢失问题。
Card 03
核心贡献
核心贡献
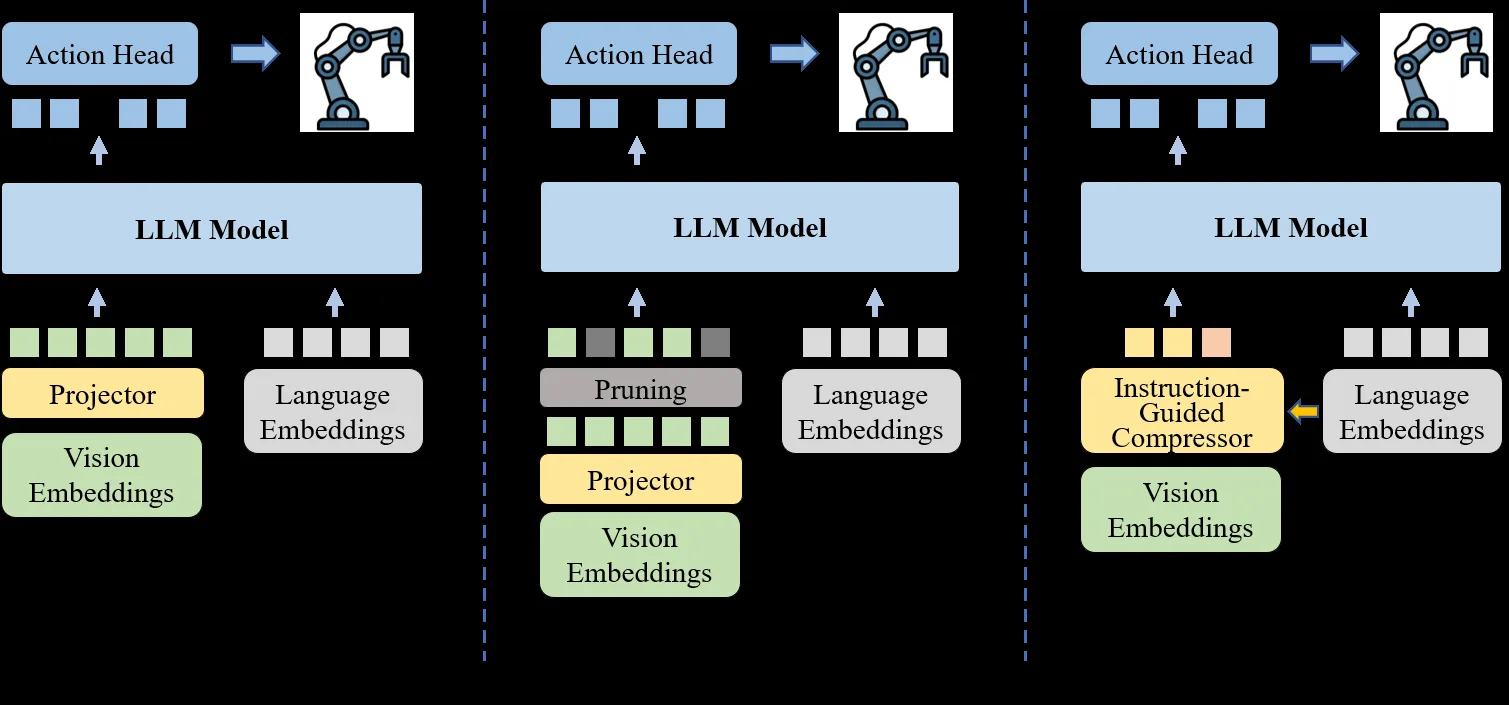
- 提出了 Compressor-VLA,一个新颖的混合指令条件标记压缩框架,它结合了局部和全局信息路径,专为VLA模型中的高效任务导向视觉信息压缩而设计。
- 在 LIBERO 基准测试上进行了广泛实验,证明了所提出的框架实现了优越的效率-性能权衡,FLOPs减少了59%,同时达到了有竞争力的 97.3% 成功率。在双臂机器人平台上的真实机器人部署验证了其Sim-to-Real迁移能力和实用性。
- 提供了定性和定量分析,验证了框架的核心设计原则,揭示了指令引导标记压缩策略的有效性以及全局和局部压缩路径之间的架构协同作用。
Card 04
方法描述
方法描述
- 提出一种混合指令引导压缩器,替换VLA模型中连接视觉编码器和LLM骨干的标准投影器。该模块由两条由语言指令调制的并行路径组成。
- 语义任务压缩器 (STC) 采用交叉注意力压缩,利用由指令通过FiLM层调制的可学习查询,提取整体、任务相关的场景摘要。
- 空间细化压缩器 (SRC) 在非重叠局部窗口上操作,通过引导局部注意力,并直接将语言嵌入注入查询中,以保留细粒度的空间细节。最终压缩的视觉标记序列是STC和SRC输出的拼接。
Card 05
数据集与资源
数据集与资源
- 使用 LIBERO 基准测试进行仿真实验,具体包括 LIBERO-Spatial, LIBERO-Object, LIBERO-Goal 和 LIBERO-Long 任务套件。
- 基础模型为 OpenVLA-OFT,包含一个双分支视觉编码器 (DINOv2 和 SigLIP) 和一个 LLaMA-2-7B 骨干。
- 所有实验在 8块 Nvidia A100 GPU 上进行,使用LoRA技术微调,全局批大小为64。
Card 06
评估与结果
评估与结果
- 评估环境包括 LIBERO 仿真基准和 Mobile ALOHA 真实双臂机器人平台。
- 主要评估指标为任务成功率、计算量 和压缩后的标记数量。
- 在 LIBERO 基准上,与基线 OpenVLA-OFT 相比,Compressor-VLA 将 FLOPs 从 3.95T 降低至 1.62T(减少59%),视觉标记数从512压缩至160(超过3倍),同时平均成功率保持在 97.3%(基线为97.1%)。
- 在真实世界任务上,Compressor-VLA 在空间感知任务上达到 100% 成功率,在语义理解任务上达到 83.3% 成功率,表现与基线相当甚至更好,证明了其实际应用价值。