一眼看懂
封面预览
论文提出了 VLA-4D,一种具有 4D 感知能力的视觉-语言-动作模型,旨在解决机器人在时空连贯性操作中的精细控制问题。
- 论文提出了 VLA-4D,一种具有 4D 感知能力的视觉-语言-动作模型,旨在解决机器人在时空连贯性操作中的精细控制问题。
- 针对现有 VLA 模型在时间维度控制上的不足(如操作停顿或抖动),该研究通过将 3D 位置和 1D 时间嵌入视觉表征,并扩展动作表征至时空域。
- 该模型实现了空间平滑和时间连贯的机器人操作,并在多项任务中取得了优越性能。
Card 01
研究单位
研究单位
- 新加坡国立大学 (National University of Singapore)
- 华中科技大学 (Huazhong University of Science and Technology)
Card 02
论文概述
论文概述
- 论文提出了 VLA-4D,一种具有 4D 感知能力的视觉-语言-动作模型,旨在解决机器人在时空连贯性操作中的精细控制问题。
- 针对现有 VLA 模型在时间维度控制上的不足(如操作停顿或抖动),该研究通过将 3D 位置和 1D 时间嵌入视觉表征,并扩展动作表征至时空域。
- 该模型实现了空间平滑和时间连贯的机器人操作,并在多项任务中取得了优越性能。
Card 03
核心贡献
核心贡献
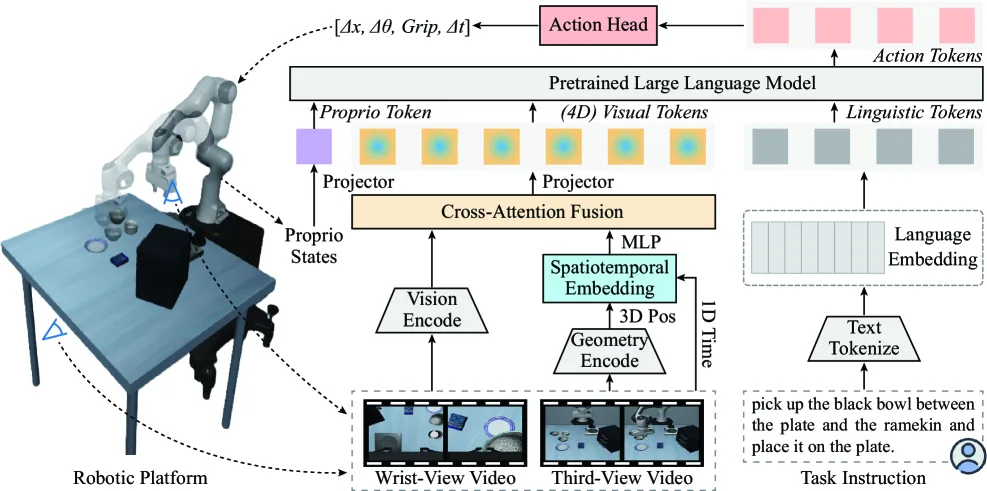
- 提出了 VLA-4D 模型,这是首个将 4D 感知嵌入视觉和动作表征的通用 VLA 模型,用于精细的视觉推理和动作规划。
- 设计了 4D 感知视觉表征,通过跨注意力机制将 3D 位置和 1D 时间融合到视觉特征中,增强了时空推理能力。
- 构建了 时空动作表征,在传统空间控制参数中引入时间变量,提升了机器人操作的空间平滑度和时间连贯性。
- 扩展了 LIBERO 数据集,增加了时间动作标注,用于模型微调并验证了方法的有效性。
Card 04
方法描述
方法描述
- 采用 VGGT 作为几何编码器提取 3D 位置,并结合时间信息通过 傅里叶编码策略 生成 4D 嵌入。
- 利用 跨注意力机制 将 4D 时空嵌入融合到由 ViT 变体提取的视觉特征中,形成统一的视觉表征。
- 将传统的空间动作参数(位移、旋转、夹持)扩展为时空动作参数(增加时间变量 $\Delta t$),并通过 LLM 进行预测。
- 训练分为两个阶段:第一阶段进行 4D 视觉-语言对齐,第二阶段在机器人数据集上进行时空动作预测的微调。
Card 05
数据集与资源
数据集与资源
- 预训练数据集包括 Scan2Cap、ScanQA、ScanRef、Multi3DRefer 和 Chat4D。
- 机器人微调数据集为扩展后的 LIBERO 数据集,包含 40 个子任务和 150k 个样本。
- 模型主干网络为 Qwen2.5-VL-7B,几何编码器为 VGGT。
- 训练硬件资源为 8 张 RTX 6000 Ada GPU。
Card 06
评估与结果
评估与结果
- 在 LIBERO 基准测试(Spatial, Object, Goal, Long)上进行评估,对比模型包括 OpenVLA、Octo、SpatialVLA 和 4D-VLA 等。
- 主要评估指标为任务成功率 和任务完成时间。
- 在微调任务中,VLA-4D 达到了最高的平均成功率 97.4% 和最短的平均完成时间 5.8秒,显著优于现有 SOTA 模型。
- 消融实验证明了 4D 视觉表征和时空动作表征对提升性能的关键作用。