一眼看懂
封面预览
论文针对 视觉-语言-动作模型 在机器人操作中严重依赖专家演示、导致演示偏差和性能受限的问题。
- 论文针对 视觉-语言-动作模型 在机器人操作中严重依赖专家演示、导致演示偏差和性能受限的问题。
- 现有的VLA强化学习方法(如GRPO)受困于奖励信号稀疏,仅依赖二元成功指示器,浪费了失败轨迹中的宝贵信息。
- 论文提出 自参考策略优化框架,利用模型在当前训练批次中生成的成功轨迹作为自我参考,为失败尝试分配过程奖励,从而提升训练效率。
Card 01
研究单位
研究单位
- 复旦大学
- 同济大学
- 上海创新研究院
Card 02
论文概述
论文概述
- 论文针对 视觉-语言-动作模型 在机器人操作中严重依赖专家演示、导致演示偏差和性能受限的问题。
- 现有的VLA强化学习方法(如GRPO)受困于奖励信号稀疏,仅依赖二元成功指示器,浪费了失败轨迹中的宝贵信息。
- 论文提出 自参考策略优化框架,利用模型在当前训练批次中生成的成功轨迹作为自我参考,为失败尝试分配过程奖励,从而提升训练效率。
Card 03
核心贡献
核心贡献
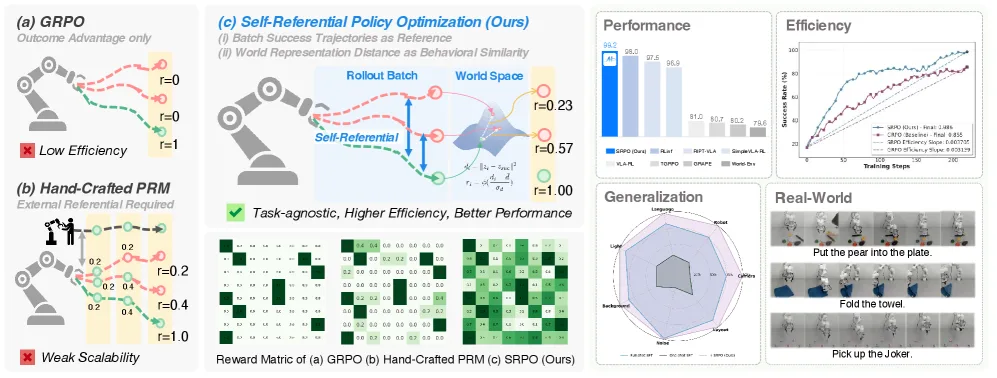
- 提出 SRPO,一个新颖的VLA强化学习框架,通过使用模型生成的成功轨迹提供过程奖励,消除对专家演示或特定任务工程的依赖。
- 引入基于 潜在世界表示 的过程奖励方法,克服了传统像素级世界模型的泛化局限和特定领域训练需求。
- 实验证明该方法在 LIBERO 基准上达到最先进性能,并在 LIBERO-Plus 上展现出强大的泛化能力,且无需在RL训练中增加额外监督。
Card 04
方法描述
方法描述
- 采用 世界模型编码器 将观测编码为潜在表示,并使用 DBSCAN算法 对成功轨迹的表示进行聚类,以获得代表性中心。
- 通过计算失败轨迹表示到最近聚类中心的 L2距离 来衡量其行为与成功模式的对齐程度,从而生成过程奖励。
- 基于GRPO框架,将世界进度奖励用于优势估计,并加入 KL散度正则化 项以保持策略稳定性,最终优化策略。
Card 05
数据集与资源
数据集与资源
- 主要评估基准为 LIBERO(包含Goal, Spatial, Object, Long四个任务套件)和用于评估鲁棒性的 LIBERO-Plus。
- 基础模型采用增强动作分块和并行解码的 OpenVLA*(称为OpenVLA*)。
- 使用大规模视频预训练的潜在世界模型 V-JEPA 2 来获取共享潜在世界表示。
- 训练框架基于 SiiRL 开发。
Card 06
评估与结果
评估与结果
- 在 LIBERO 基准上,SRPO从基线模型的48.9%成功率,在仅200个RL步后达到 99.2% 的最先进成功率,相对提升103%。
- 在 LIBERO-Plus 鲁棒性基准上,SRPO实现了 167% 的性能提升,显著超越了全样本SFT基线。
- 真实机器人实验表明,该方法能将扩散型策略 π₀ 和自回归策略 π₀-FAST 的性能分别提升66.8%和86.7%。
- 分析证明,相比像素级或ImageBind基方法,SRPO的奖励信号更平滑、单调,更能准确反映任务进展,并有效激励策略探索新型轨迹。