一眼看懂
封面预览
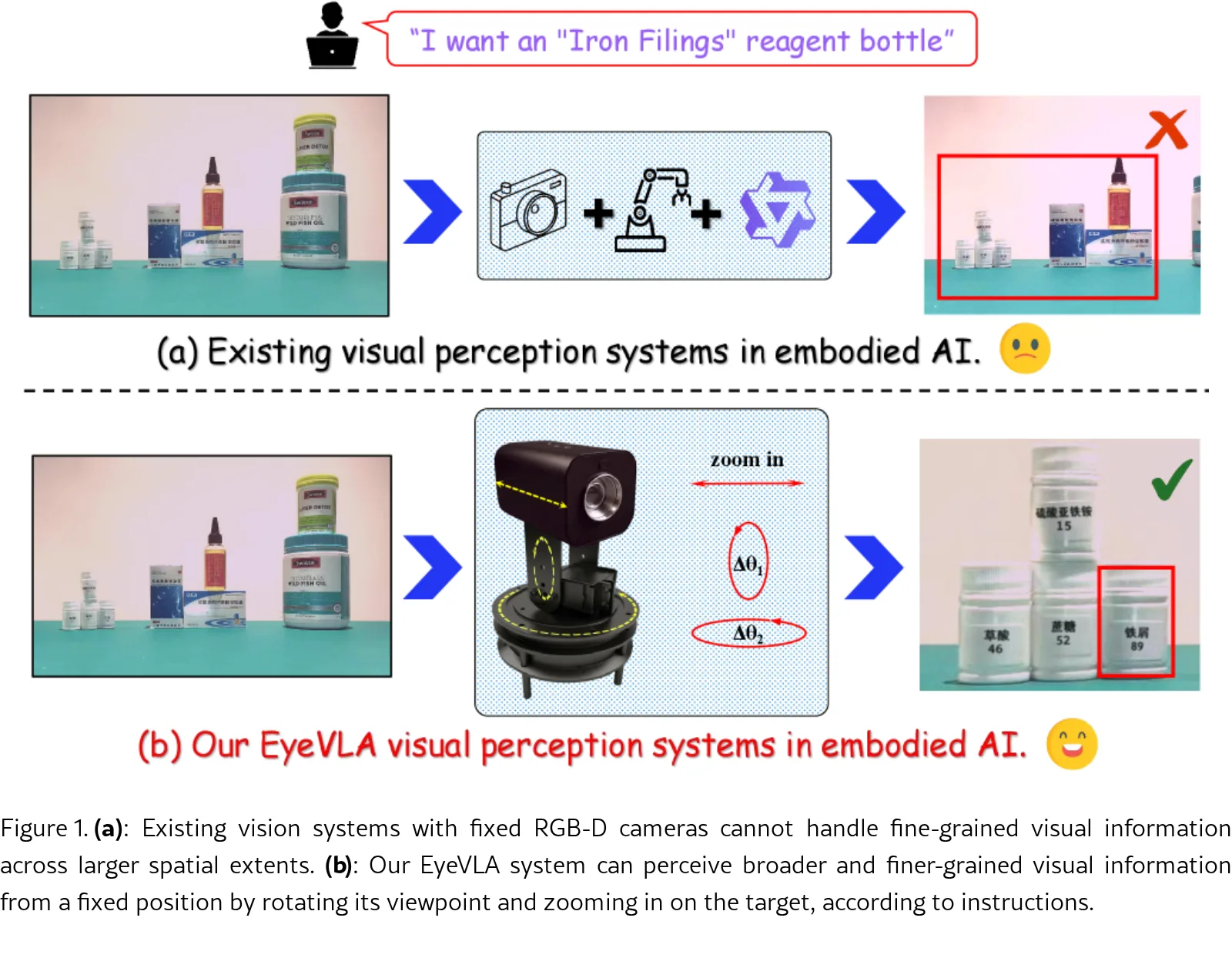
论文提出 EyeVLA,一个用于主动视觉感知的机器人眼球系统,能够根据指令主动执行旋转和变焦动作,在宽空间范围内清晰观察细粒度目标物体。
- 论文提出 EyeVLA,一个用于主动视觉感知的机器人眼球系统,能够根据指令主动执行旋转和变焦动作,在宽空间范围内清晰观察细粒度目标物体。
- 旨在解决现有视觉模型和固定RGB-D相机系统无法兼顾大范围覆盖与细粒度细节获取的问题。
- 将动作行为离散化为动作标记,并与视觉语言模型集成,在单个自回归序列中联合建模视觉、语言和动作。
Card 01
研究单位
研究单位
- 上海交通大学 人工智能学院
- 中国科学院自动化研究所
- 大连理工大学
Card 02
论文概述
论文概述
- 论文提出 EyeVLA,一个用于主动视觉感知的机器人眼球系统,能够根据指令主动执行旋转和变焦动作,在宽空间范围内清晰观察细粒度目标物体。
- 旨在解决现有视觉模型和固定RGB-D相机系统无法兼顾大范围覆盖与细粒度细节获取的问题。
- 将动作行为离散化为动作标记,并与视觉语言模型集成,在单个自回归序列中联合建模视觉、语言和动作。
Card 03
核心贡献
核心贡献
- 将摄像机运动与变焦控制形式化为一个离散的、标记化的决策过程,无缝集成并联合优化多模态推理。
- 引入平移/倾斜/变焦调整的层次化离散化方法,并将其嵌入VLM词汇表中,无需单独的控制头即可实现图像、语言和动作的统一自回归建模。
- 利用2D区域(边界框)信号作为推理链中的结构指导和奖励塑造元素,通过强化学习将开放世界语义转化为细粒度主动控制。
- 展示了一种数据高效流程,仅使用500个真实世界样本和伪标签扩展,即可学习可执行策略并在开放世界场景中实现零样本能力。
Card 04
方法描述
方法描述
- 基于 Qwen2.5-VL 框架构建系统,集成视觉感知、语言理解和动作生成能力。
- 提出分层动作编码方案,使用基数集 {5, 2, 1} 将连续摄像机动作转化为离散动作标记,优化标记效率。
- 采用两阶段训练策略:第一阶段为带有伪标签的监督对齐;第二阶段通过强化学习进行策略细化,使用 GRPO 算法优化策略。
- 利用合成数据生成器扩展数据集,通过IoU阈值筛选高质量伪标签样本。
Card 05
数据集与资源
数据集与资源
- 使用自建机器人眼球系统采集的 500个真实世界数据样本。
- 从 Rexverse-2M 数据集中抽取 50,000张 小目标图像用于合成数据生成。
- 基础模型为 Qwen2.5-VL-7B-Instruct,参数量约 7B。
- 训练过程采用两阶段策略,包括监督微调和强化学习。
Card 06
评估与结果
评估与结果
- 在真实世界环境中评估,主要指标为平均绝对误差(MAE)和任务完成率(CR)。
- 最佳模型(RL3)在测试集上达到 θ₁ MAE: 2.04°,θ₂ MAE: 1.68°,Zoom MAE: 65.37。
- 在真实世界场景测试中,任务完成率达到 96%。
- 消融实验证明,引入边界框指导和IoU筛选策略、使用强化学习均显著提升了模型性能。