一眼看懂
封面预览
论文提出了 VLA-R,一个面向开放世界端到端自动驾驶(OW-E2EAD)的视觉-语言-动作检索框架。
- 论文提出了 VLA-R,一个面向开放世界端到端自动驾驶(OW-E2EAD)的视觉-语言-动作检索框架。
- 核心目标是通过集成开放世界感知与一种新颖的视觉-动作检索范式,解决自动驾驶在非结构化、未知环境中泛化能力差的问题。
- 该方法利用冻结的视觉语言模型进行开放世界感知,并通过对比学习对齐视觉语言与动作表征,实现可解释、可迁移的决策。
Card 01
研究单位
研究单位
- 韩国科学技术院电气工程学院
Card 02
论文概述
论文概述
- 论文提出了 VLA-R,一个面向开放世界端到端自动驾驶(OW-E2EAD)的视觉-语言-动作检索框架。
- 核心目标是通过集成开放世界感知与一种新颖的视觉-动作检索范式,解决自动驾驶在非结构化、未知环境中泛化能力差的问题。
- 该方法利用冻结的视觉语言模型进行开放世界感知,并通过对比学习对齐视觉语言与动作表征,实现可解释、可迁移的决策。
Card 03
核心贡献
核心贡献
- 提出了 Vision-Language Action Retrieval (VLA-R) 新范式,从开放世界视觉-语言-动作嵌入空间中检索行为最匹配的动作。
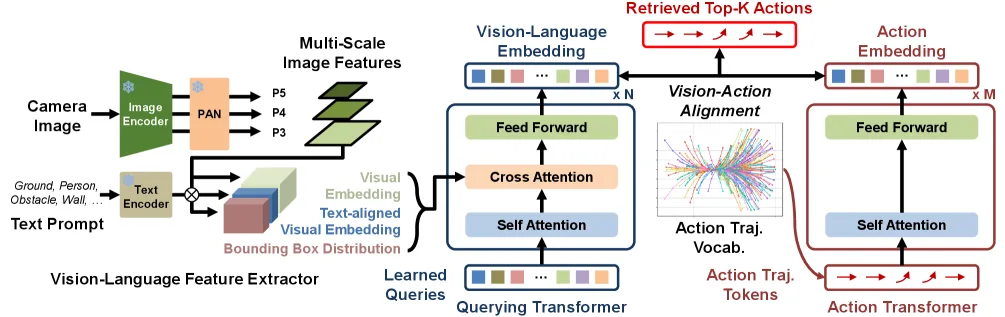
- 设计了 Open-World Querying Transformer (OW-QFormer),聚合冻结视觉语言模型的多源感知特征,形成统一的、可解释的场景嵌入。
- 引入了 Action Transformer 和三维动作令牌词汇表,对动作轨迹进行编码,并与视觉语言嵌入进行对比对齐。
- 提出视觉-动作对比学习方案,在共享潜在空间中有效对齐感知与行为表示,支持零样本泛化。
- 在真实机器人平台上验证了方法在有限数据和未见过的非结构化户外环境中的强泛化与探索能力。
Card 04
方法描述
方法描述
- 感知模块采用冻结的 YOLOE 模型提取多尺度、文本对齐的视觉特征和几何空间先验。
- 使用 OW-QFormer 通过可学习查询聚合视觉、文本和框特征,生成紧凑的视觉-语言场景嵌入。
- 提出基于Transformer的 Action Transformer,将离散化的三维动作轨迹令牌编码为动作嵌入。
- 训练时采用 InfoNCE 损失进行视觉-语言嵌入与动作嵌入的对比学习,构建联合嵌入空间。
- 推理时,计算当前场景嵌入与所有动作嵌入的相似度,检索出语义最匹配的动作令牌作为控制指令。
Card 05
数据集与资源
数据集与资源
- 使用真实世界移动机器人平台 Clearpath Jackal(配备 Intel RealSense D455 相机)进行数据采集与闭环测试。
- 采集了约 36,582个图像-动作对(近2小时驾驶数据),以5Hz频率记录。
- 模型训练耗时 小于4小时,使用单块 RTX 5000 Ada (32 GB) GPU。
- 动作词汇表通过机器人的运动学模型生成六步轨迹并在三维网格空间离散化得到。
Card 06
评估与结果
评估与结果
- 评估环境为真实的、非结构化的户外场景,包括粗糙地形、密林、悬崖和死胡同等挑战性场景。
- 主要评估指标为 碰撞事件次数 和 成功(无碰撞)率。
- 在 粗糙地形 场景中,VLA-R成功率达 0.96,事件数 117,显著优于基线方法。
- 在未见的 密林 环境中,VLA-R保持 0.93 的高成功率,展现了强泛化能力。
- 在 悬崖与死胡同 等极端场景中,VLA-R成功率达 0.85,远超其他方法,证明了在复杂地形中的鲁棒性。
- 实验表明,检索式动作生成结合开放世界感知,在开放世界条件下优于直接回归或分类式策略。