一眼看懂
封面预览
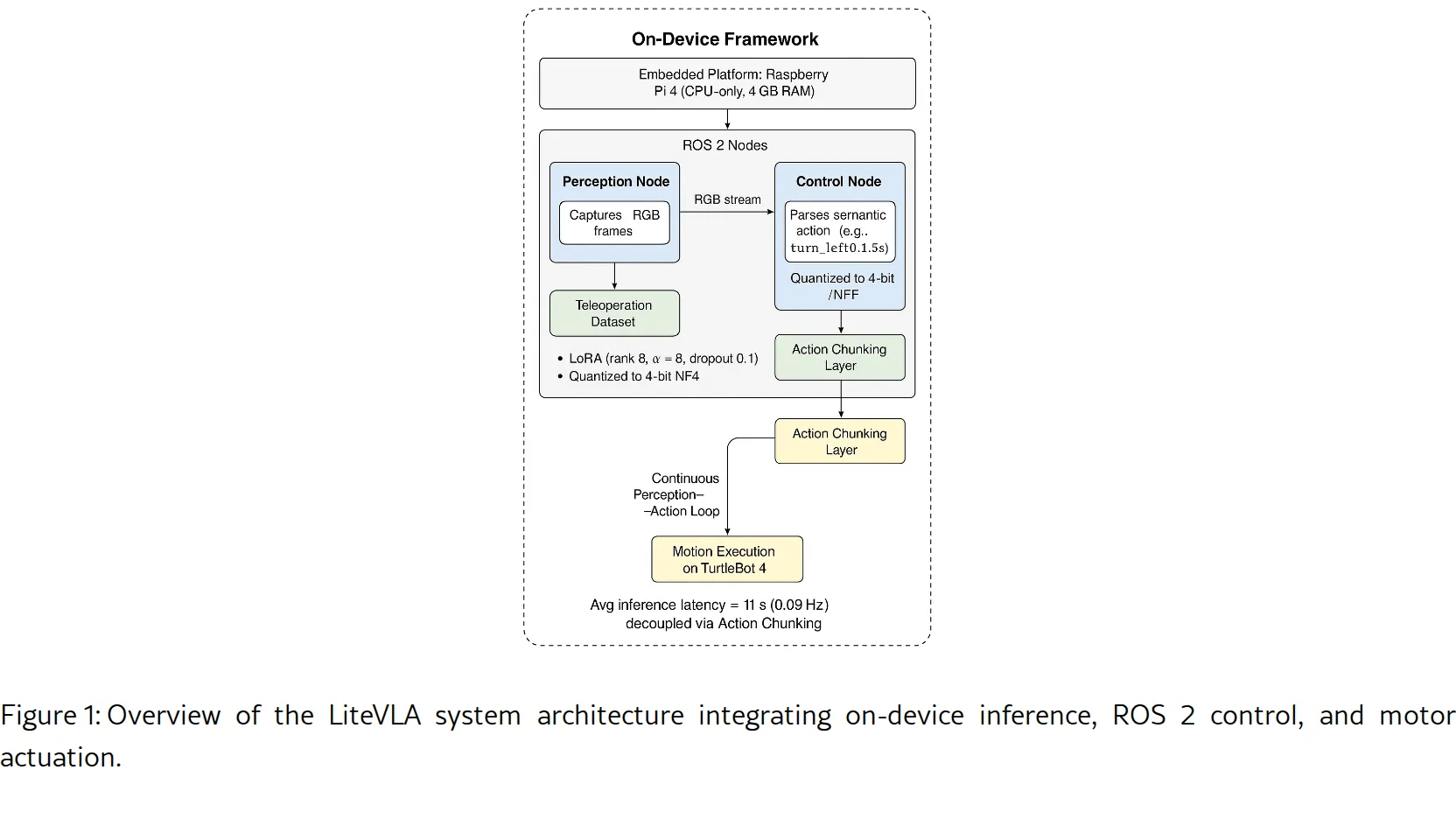
论文提出了 LiteVLA,一个轻量级的视觉-语言-动作模型,旨在资源受限的边缘机器人上实现高效的端侧推理与控制。
- 论文提出了 LiteVLA,一个轻量级的视觉-语言-动作模型,旨在资源受限的边缘机器人上实现高效的端侧推理与控制。
- 该系统解决了传统大型 VLA 模型(如 PaLM-E, RT-2)依赖云端算力、难以在无 GPU 的移动机器人上部署的问题。
- 通过模型量化与参数高效微调,实现了在 Raspberry Pi 4 上仅使用 CPU 进行实时场景理解与运动控制。
Card 01
研究单位
研究单位
- Clark Atlanta University(网络物理系统系)
- Siemens Corporation
Card 02
论文概述
论文概述
- 论文提出了 LiteVLA,一个轻量级的视觉-语言-动作模型,旨在资源受限的边缘机器人上实现高效的端侧推理与控制。
- 该系统解决了传统大型 VLA 模型(如 PaLM-E, RT-2)依赖云端算力、难以在无 GPU 的移动机器人上部署的问题。
- 通过模型量化与参数高效微调,实现了在 Raspberry Pi 4 上仅使用 CPU 进行实时场景理解与运动控制。
Card 03
核心贡献
核心贡献
- 实现了首个基于 GGUF 量化策略的 VLA 模型与 ROS 2 的集成,在 Raspberry Pi 4 上实现了完全基于 CPU 的异步推理与控制。
- 提出了混合精度量化方案(NF4 主干 + FP32 投影头),在保持输出稳定性的同时,相比 FP32 基线实现了 9 倍 的推理加速和约 75% 的内存节省。
- 利用 LoRA 技术对模型进行参数高效微调,使其适应视觉运动控制任务,同时保持较低的计算开销。
- 构建了端到端的流水线,将 RGB 图像直接映射为结构化的运动指令,并在 TurtleBot 4 上验证了可行性。
Card 04
方法描述
方法描述
- 模型架构基于轻量级多模态模型 SmolVLM-256M。
- 训练流程包括数据采集(遥操作)、预处理(缩放至 224x224、归一化)、数据集划分(85:15)及模型微调。
- 使用 LoRA(低秩适应)进行微调,配置为 rank=8, alpha=8, dropout=0.1。
- 采用 NF4(4-bit NormalFloat)量化技术压缩模型权重,并保留投影头为 FP32 精度以防止控制信号的不稳定。
- 利用 llama-cpp-python 运行时库在边缘设备上执行推理。
Card 05
数据集与资源
数据集与资源
- 数据集:包含 15,083 个图像-动作对,通过手动遥操作 TurtleBot 4 采集,包含前进、后退、转向等动作标签。
- 硬件平台:Raspberry Pi 4(4GB RAM, 四核 ARM Cortex-A72 CPU),TurtleBot 4 移动机器人。
- 模型规模:基础模型参数量约 2.56 亿(SmolVLM-256M)。
Card 06
评估与结果
评估与结果
- 评估环境:在 Raspberry Pi 4 CPU 上进行推理延迟与内存占用测试。
- 主要结果:
- SmolVLM-256 (FP32) 基线推理延迟约为 11 秒。
- LiteVLA (FP32) 推理延迟约为 18 分钟(模型较大或未优化)。
- LiteVLA (Hybrid, NF4+FP32) 推理延迟约为 2 分钟,相比 FP32 版本加速 9 倍,且输出稳定。
- 全量化模型(LiteVLA 4b)延迟约为 1.5 分钟,但输出不稳定。
- 系统通过 ROS 2 的 Action Chunking 机制实现了高频低级控制与异步高级推理的结合。