一眼看懂
封面预览
论文提出了一个名为 Visual Spatial Tuning (VST) 的综合框架,旨在增强视觉语言模型(VLMs)的类人视觉空间能力,涵…
- 论文提出了一个名为 Visual Spatial Tuning (VST) 的综合框架,旨在增强视觉语言模型(VLMs)的类人视觉空间能力,涵…
- 研究旨在解决当前 VLMs 在从视觉输入中捕捉空间关系方面存在的局限性,这种局限限制了其在机器人、自动驾驶和AR/VR等领域的应用。
- 核心方法是通过构建大规模、精心策划的数据集,采用渐进式训练流水线,在不引入额外专家编码器、不损害模型通用能力的前提下,显著提升 VLMs 的空…
Card 01
研究单位
研究单位
- 香港大学
- ByteDance Seed
- 清华大学
Card 02
论文概述
论文概述
- 论文提出了一个名为 Visual Spatial Tuning (VST) 的综合框架,旨在增强视觉语言模型(VLMs)的类人视觉空间能力,涵盖从空间感知到推理的全过程。
- 研究旨在解决当前 VLMs 在从视觉输入中捕捉空间关系方面存在的局限性,这种局限限制了其在机器人、自动驾驶和AR/VR等领域的应用。
- 核心方法是通过构建大规模、精心策划的数据集,采用渐进式训练流水线,在不引入额外专家编码器、不损害模型通用能力的前提下,显著提升 VLMs 的空间感知与推理能力。
Card 03
核心贡献
核心贡献
- 提出了 Visual Spatial Tuning (VST) 框架,这是一个用于培养 VLMs 空间能力的全面解决方案。
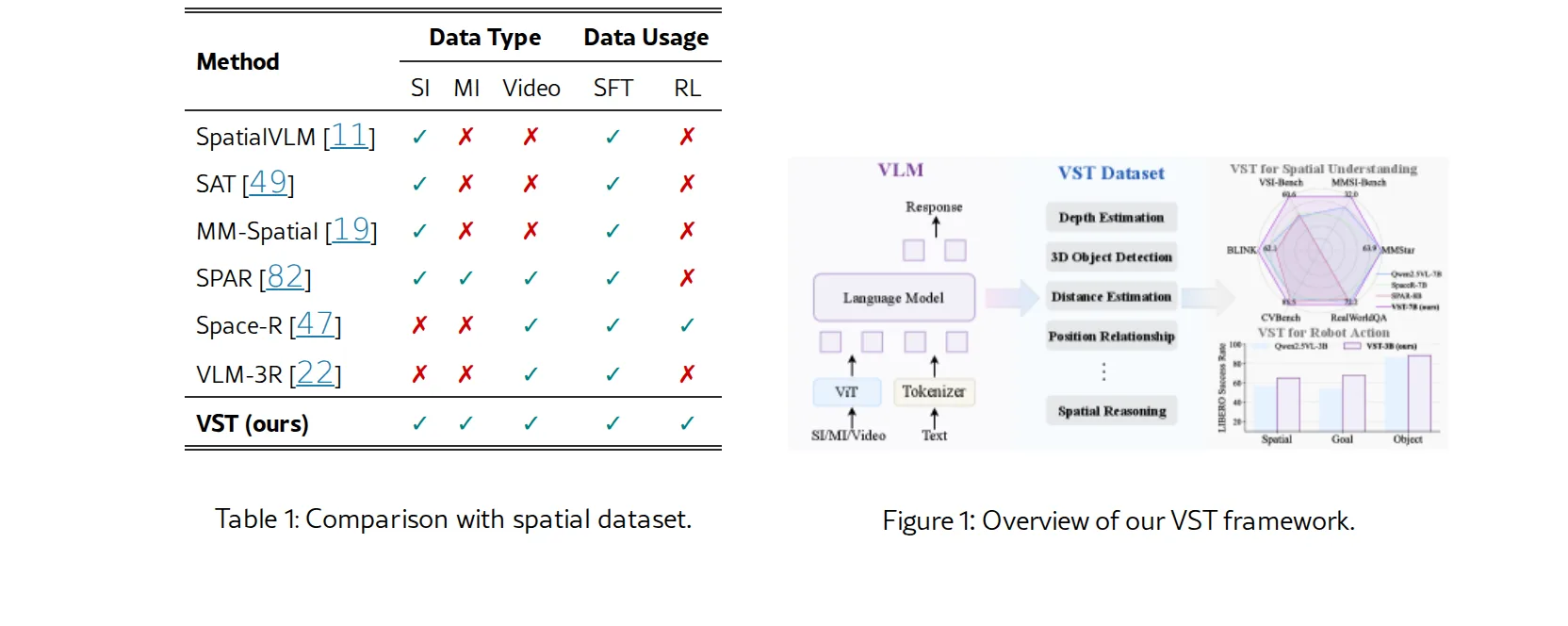
- 构建了大规模数据集 VST-Perception (VST-P)(410万样本,涵盖19项技能)和 VST-Reasoning (VST-R)(13.5万样本),分别用于建立空间感知基础和提升空间推理能力。
- 设计了渐进式训练策略:首先通过监督微调注入空间知识,再利用强化学习进一步增强空间推理能力,该策略模拟了人类空间智能的发展过程。
- 实验结果表明,VST 在多个空间基准上取得了最先进的性能,同时保持了模型的通用多模态能力,并能有效提升下游 Vision-Language-Action (VLA) 模型的性能。
Card 04
方法描述
方法描述
- 使用 Qwen2.5-VL 作为基础模型,遵循“ViT-MLP-LLM”架构。
- 提出三阶段训练策略:1) 在 VST-P 数据集上进行监督微调,建立空间感知基础;2) 使用思维链数据进行冷启动训练,赋予模型基本推理模式;3) 使用 Group Relative Policy Optimization (GRPO) 算法进行强化学习,进一步提升推理能力。
- 关键技术创新包括:FoV统一策略以消除不同数据源相机内参的差异性;基于BEV标注的提示方法,利用俯视图辅助生成更准确、连贯的空间推理链。
- 该方法证明了无需在 VLM 中引入具有3D归纳偏置的特殊编码器,仅通过数据和训练策略即可实现强大的空间能力。
Card 05
数据集与资源
数据集与资源
- VST-Perception (VST-P):包含 4.1M 样本,涵盖单图像、多图像和视频三种模态下的 19 项空间感知任务。
- VST-Reasoning (VST-R):包含 135K 样本,用于训练模型的空间推理能力,包含思维链和规则可验证的样本。
- 基础模型规模包括 Qwen2.5-VL-3B、7B、32B。
- 论文HTML原文中未明确提及具体的GPU/TPU等训练硬件资源信息。
Card 06
评估与结果
评估与结果
- 评估基准:空间能力评估涵盖单图像、多图像和视频能力,包括 CVBench, 3DSRBench, MMSI-Bench, BLINK, VSIBench;通用能力评估包括 MMStar, MMBench, RealworldQA, MMMU, OCRBench, AI2D;3D目标检测在 SUN RGB-D 和 ARKitScenes 数据集上评估。
- 关键结果:
- VST-7B-RL 在 MMSI-Bench 上达到 34.8%,在 VSIBench 上达到 61.2%,均取得领先水平。
- 在 CVBench 上,VST-7B-SFT 达到 87.8%,超越了私有模型 Seed1.5-VL。
- 在 SUN RGB-D 3D目标检测任务中,VST-7B-RL 取得了 44.2% AP@15,在通用VLM和专用方法中均排名第一。
- VST框架能有效提升VLA模型性能,在 LIBERO 基准上使 Qwen2.5VL-3B 的性能提升了 8.6%。
- 所有模型在保持空间能力显著提升的同时,通用多模态能力(MM-AVG)并未受损。