一眼看懂
封面预览
论文提出 Evo-1,一个轻量级的视觉-语言-动作 (VLA) 模型,旨在解决现有VLA模型参数庞大、依赖大规模机器人数据预训练、计算成本高和…
- 论文提出 Evo-1,一个轻量级的视觉-语言-动作 (VLA) 模型,旨在解决现有VLA模型参数庞大、依赖大规模机器人数据预训练、计算成本高和…
- 该模型通过保留预训练视觉-语言模型的语义对齐能力,在无需机器人数据预训练的情况下,实现了低成本训练和高效实时推理。
- 核心目标是构建一个参数量小(0.77B)、性能强、泛化能力好的高效VLA模型。
Card 01
研究单位
研究单位
- 上海交通大学人工智能学院
- EvoMind Tech
- IAAR-Shanghai
- 卡内基梅隆大学
- 剑桥大学
- 南洋理工大学
Card 02
论文概述
论文概述
- 论文提出 Evo-1,一个轻量级的视觉-语言-动作 (VLA) 模型,旨在解决现有VLA模型参数庞大、依赖大规模机器人数据预训练、计算成本高和实时部署难的问题。
- 该模型通过保留预训练视觉-语言模型的语义对齐能力,在无需机器人数据预训练的情况下,实现了低成本训练和高效实时推理。
- 核心目标是构建一个参数量小(0.77B)、性能强、泛化能力好的高效VLA模型。
Card 03
核心贡献
核心贡献
- 提出了 Evo-1,一个仅有0.77B参数的轻量级VLA架构,显著降低了训练成本并提升了在消费级GPU上的推理速度。
- 引入了一种两阶段训练范式,在将模型适应于动作生成的同时,有效保留了视觉-语言骨干网络固有的多模态理解能力,从而提升了泛化性能。
- 通过大量实验证明,Evo-1 在无需大规模机器人数据预训练的前提下,于仿真和真实世界任务中均取得了最先进 (SOTA) 性能,大幅降低了对昂贵数据收集的需求。
Card 04
方法描述
方法描述
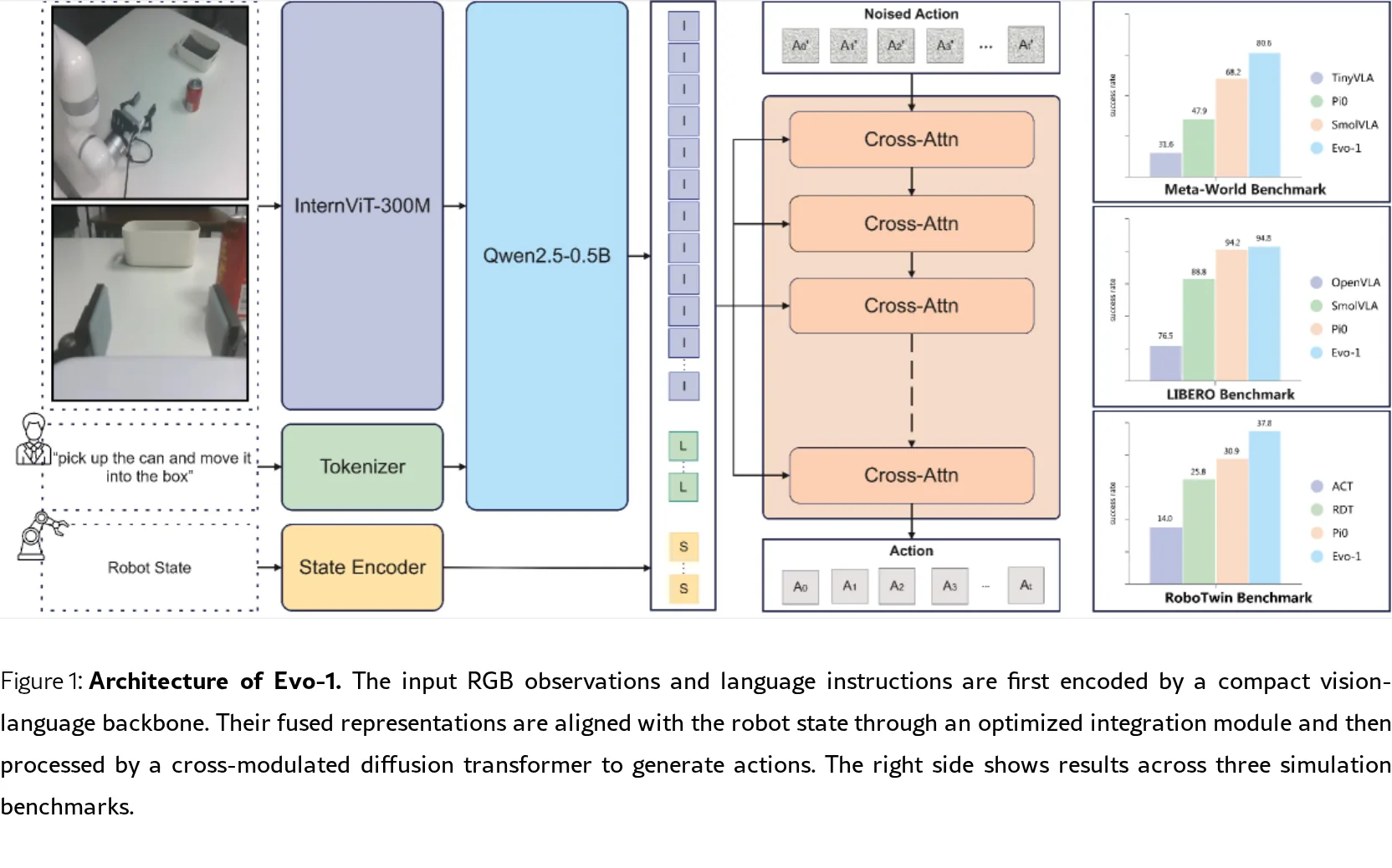
- 架构:模型由三部分组成:基于InternVL3-1B的视觉-语言骨干网络、一个新颖的交叉调制扩散变换器 作为动作专家,以及一个优化的集成模块。
- 创新点:骨干网络采用原生多模态训练范式,视觉编码器使用轻量化的InternViT-300M,语言模型使用Qwen2.5-0.5B。动作专家采用纯交叉注意力层的扩散变换器,用于生成连续动作轨迹。集成模块通过拼接视觉-语言特征与机器人状态来保留完整信息。
- 训练策略:提出两阶段训练流程。第一阶段冻结VLM骨干,仅训练动作专家和集成模块以对齐特征空间;第二阶段解冻VLM进行全参数微调,实现深度融合与任务适应。该策略有效保留了VLM的语义空间。
Card 05
数据集与资源
数据集与资源
- 使用了Meta-World、LIBERO、RoboTwin 三个仿真基准,以及自采的真实世界机器人操作任务数据。
- 模型总参数量为 0.77B。
- 训练使用 8块 NVIDIA A100 GPU。
Card 06
评估与结果
评估与结果
- 仿真实验:在Meta-World基准上达到 80.6% 的平均成功率,超越之前最佳模型 12.4%;在RoboTwin基准上达到 37.8%,超越之前最佳 6.9%;在LIBERO基准上达到 94.8% 的竞争力结果。
- 真实世界实验:在四个代表性机器人任务上取得 78% 的总体成功率,高于所有基线模型。
- 效率评估:在RTX 4090d GPU上,模型显存占用仅 2.3 GB,推理频率达 16.4 Hz,在效率与性能上取得了最佳平衡。泛化实验表明,模型在面对未见干扰物、背景变化、目标位置和高度变化时,表现均优于基线模型。