一眼看懂
封面预览
提出了 iFlyBot-VLA,一个基于新型框架训练的大规模视觉-语言-动作(VLA)模型,用于控制双臂机器人
- 提出了 iFlyBot-VLA,一个基于新型框架训练的大规模视觉-语言-动作(VLA)模型,用于控制双臂机器人
- 旨在解决 VLA 模型中如何平衡 VLM 的通用感知能力与精确动作生成能力的问题,以及如何从大规模视频中学习可迁移的潜在动作表示
- 核心创新在于引入双层动作表示框架,结合显式(离散动作 token)和隐式(潜在动作)规划,显著提升模型的泛化能力和任务执行精度
Card 01
研究单位
研究单位
- iFlyTek Research and Development Group
- LindenBot
- 主要作者:Yuan Zhang、Chenyu Xue、Wenjie Xu、Chao Ji、Jiajia Wu、Jia Pan
Card 02
论文概述
论文概述
- 提出了 iFlyBot-VLA,一个基于新型框架训练的大规模视觉-语言-动作(VLA)模型,用于控制双臂机器人
- 旨在解决 VLA 模型中如何平衡 VLM 的通用感知能力与精确动作生成能力的问题,以及如何从大规模视频中学习可迁移的潜在动作表示
- 核心创新在于引入双层动作表示框架,结合显式(离散动作 token)和隐式(潜在动作)规划,显著提升模型的泛化能力和任务执行精度
Card 03
核心贡献
核心贡献
- 构建了基于 VQ-VAE 的潜在动作模型,在大规模人类和机器人操作视频上进行预训练,学习高层通用的动作表示
- 提出了 双层动作表示框架,同时监督 VLM 和动作专家,支持潜在动作 token 和结构化离散动作 token 的联合训练
- 设计了 混合训练策略,将机器人轨迹数据与通用 QA 和空间推理 QA 数据集混合,增强 VLM 的 3D 感知和推理能力
- 采用了 Flow-Matching 机制生成连续动作,利用 Diffusion Transformer 作为下游动作专家
- 在 LIBERO 基准测试和真实机器人平台上进行了全面评估,实现了 93.8% 的平均成功率
Card 04
方法描述
方法描述
- VLM 主干网络:基于 Qwen2.5-VL (3B),接收语言指令、多视角 RGB 图像和机器人本体感知状态作为输入
- 潜在动作模型:使用 VQ-VAE 架构,从连续帧对中提取离散潜在动作表示,采用 NSVQ 算法解决梯度消失问题
- 离散动作编码:采用 FAST (Fast Action Token) 方法,基于 DCT 变换对动作窗口进行压缩和编码
- 动作专家:基于 Flow-Matching Diffusion Transformer,通过去噪生成连续动作块,支持双向注意力机制
- 训练分为三阶段:潜在动作训练 → 基础预训练 → 任务微调,确保 VLM 能力不退化
Card 05
数据集与资源
数据集与资源
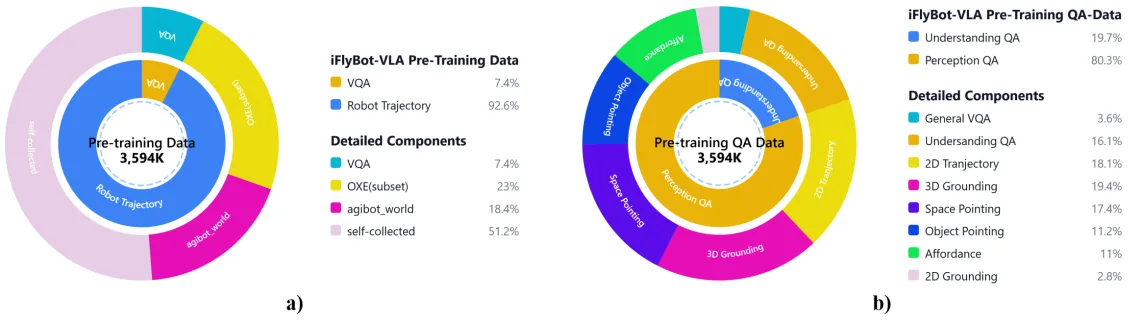
- 训练数据集:OXE、AgiBot-World、自建 iFLYTEK 数据集,内部 VQA 空间理解数据集
- 自建数据规模:
- 26 台双臂机器人
- 布料折叠:约 110 小时(8 种衣物类型)
- 通用抓取放置:约 90 小时(30 类物体,400 条轨迹/类)
- 长程包裹分拣:约 47 小时(2,752 条轨迹)
- 模型规模:基于 Qwen2.5-VL 3B 参数
Card 06
评估与结果
评估与结果
- LIBERO 基准测试:iFlyBot-VLA 达到 93.8% 平均成功率,优于 π₀ (86%) 和 OpenVLA (76.5%)
- 消融实验:完整模型比无 FAST 模块提升 6%,比无 LAM 模块提升 3.5%,双模块移除则下降 20.8%
- 真实世界实验:
- 基础抓取放置:96.25% 成功率
- 光照变化:96.04%
- 未见物体:88.21%
- 未见场景:93.57%
- 长程操作任务:比基线提升 7.5%
- 布料折叠:约 90% 单步成功率