一眼看懂
封面预览
提出 Action Coherence Guidance (ACG),一种无需训练的测试时引导算法,用于改进基于流匹配的视觉-语言-动作(VL…
- 提出 Action Coherence Guidance (ACG),一种无需训练的测试时引导算法,用于改进基于流匹配的视觉-语言-动作(VL…
- 针对人类演示中的噪声(抖动、停顿、震颤)导致动作连贯性下降的问题,这些问题会造成精细操作任务中的不稳定性和轨迹漂移
- 在 RoboCasa、DexMimicGen 模拟基准和 SO-101 真实世界任务上评估,ACG 在各类操作任务中一致提升成功率和动作连贯性
Card 01
研究单位
研究单位
- DAVIAN-Robotics, KAIST AI(韩国科学技术院)
- 作者:Minho Park, Kinam Kim, Junha Hyung, Hyojin Jang, Hoiyeong Jin, Jooyeol Yun, Hojoon Lee, Jaegul Choo
Card 02
论文概述
论文概述
- 提出 Action Coherence Guidance (ACG),一种无需训练的测试时引导算法,用于改进基于流匹配的视觉-语言-动作(VLA)模型的动作连贯性
- 针对人类演示中的噪声(抖动、停顿、震颤)导致动作连贯性下降的问题,这些问题会造成精细操作任务中的不稳定性和轨迹漂移
- 在 RoboCasa、DexMimicGen 模拟基准和 SO-101 真实世界任务上评估,ACG 在各类操作任务中一致提升成功率和动作连贯性
Card 03
核心贡献
核心贡献
- 首次将扰动引导(perturbation guidance)引入机器人控制领域
- 提出通过替换自注意力层中的注意力图为恒等映射来构建不一致动作生成向量场
- 解决动作分块内(intra-chunk)的动作连贯性问题,而非仅关注跨分块的连贯性
- ACG 可即插即用应用于任意使用自注意力处理动作标记的流式 VLA 模型(如 GR00T-N1、π0、SmolVLA)
- 在精细操作任务上表现尤为突出:按钮按压(+23.1%)、插入(+11.8%)、真实世界拾取放置(+28.8%)
Card 04
方法描述
方法描述
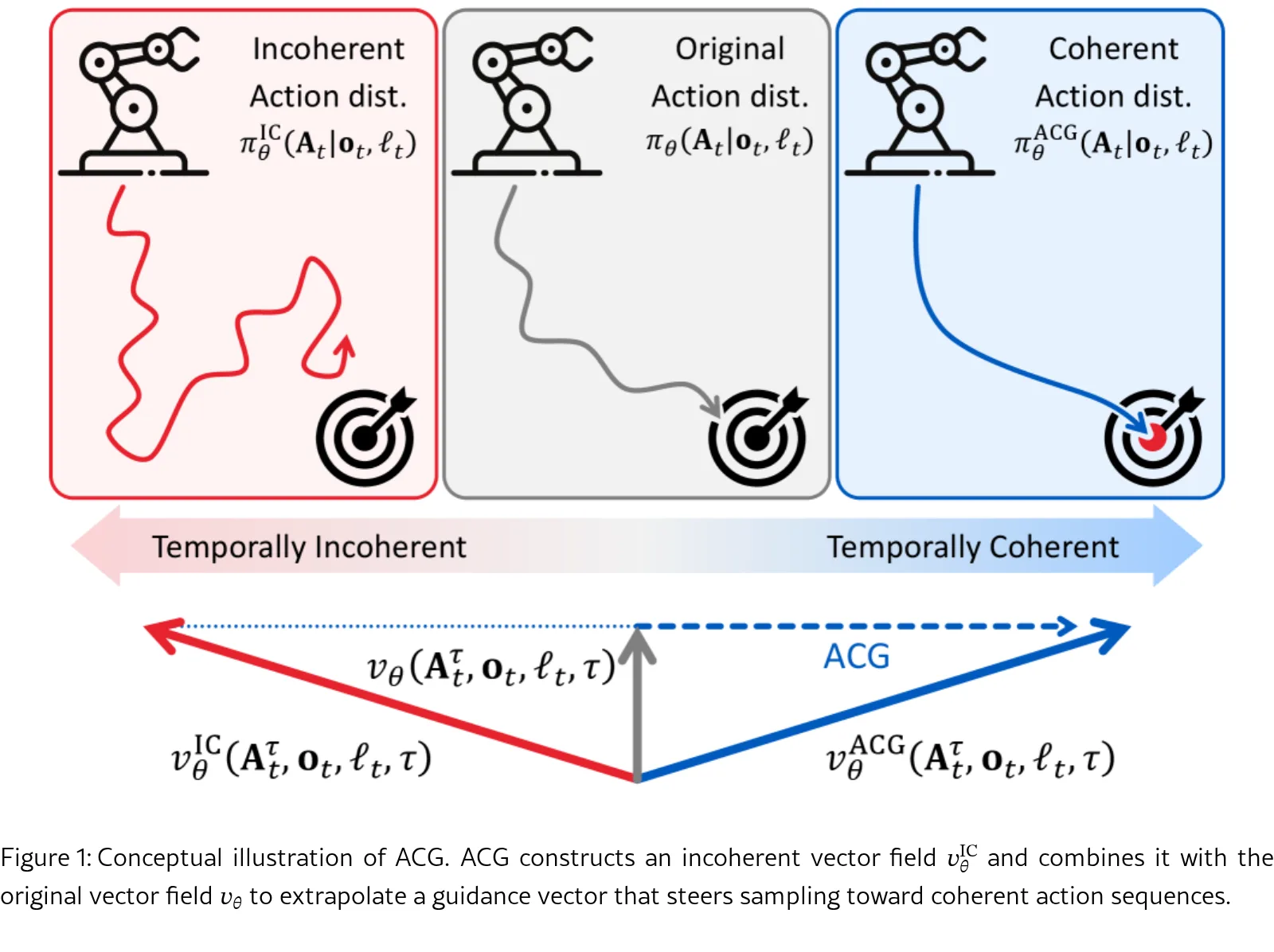
- 技术基础:基于流匹配策略(Flow Matching Policy)的 VLA 模型,使用 Transformer 架构处理动作序列
- 核心创新:通过恒等注意力图(Identity Attention Map)破坏时间通信,使每个动作标记仅关注自身,产生时间不一致的动作序列
- 引导机制:将原始去噪向量场与不一致向量场结合,引导采样向连贯动作方向移动
- 公式:$v_{\theta}^{ACG} = (1+\lambda)v_{\theta} - \lambda v_{\theta}^{IC}$
- 关键参数:默认使用第 4-6 层(共 8 层)进行扰动,引导尺度 λ=3.0
Card 05
数据集与资源
数据集与资源
- 基准数据集:
- RoboCasa:24 个厨房环境操作任务,7 个技能域
- DexMimicGen:双手灵巧操作任务,多种机器人形态
- SO-101:真实世界拾取放置任务(Three Strawberries、Tic-Tac-Toe)
- 基础模型:主要使用 GR00T-N1,并泛化到 π0 和 SmolVLA
- 训练配置:批量大小 128,60,000 次迭代,峰值学习率 0.0001
- 计算开销:约 1.5 倍于基线推理时间(通过仅扰动部分层优化)
Card 06
评估与结果
评估与结果
- 主要基准:Vanilla GR00T-N1 作为基线
- 关键指标:成功率、动作全变差(ATV)、均方根抖动(JerkRMS)
- 实验结果:
- RoboCasa:32.6% → 39.3%(+6.7%)
- DexMG:40.6% → 44.0%(+3.4%)
- Three Strawberries:43.6% → 74.4%(+30.8%)
- Tic-Tac-Toe:38.3% → 56.7%(+18.4%)
- 平均提升:+9.6%
- 消融实验:验证了引导尺度、中间层扰动、超参数鲁棒性;与 Self-GAD(跨分块连贯性)结合可进一步提升性能