一眼看懂
封面预览
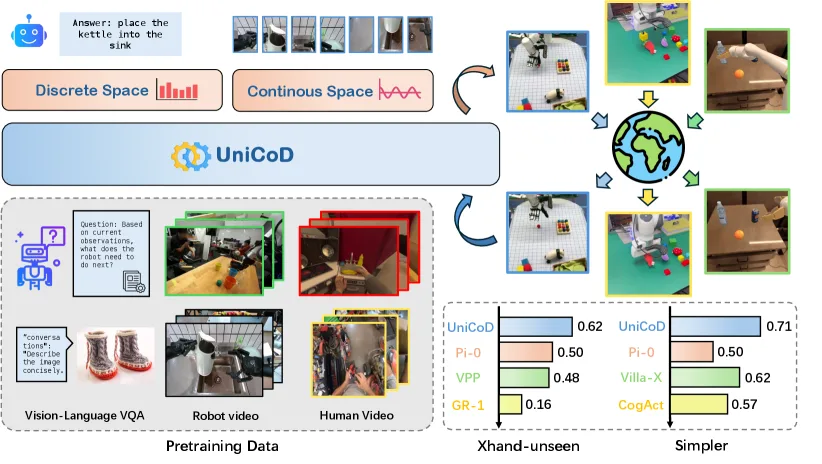
论文提出 UniCoD,一个统一的视觉-语言-动作(VLA)框架,通过结合离散表示(语言理解)和连续表示(视觉预测)来增强机器人策略学习
- 论文提出 UniCoD,一个统一的视觉-语言-动作(VLA)框架,通过结合离散表示(语言理解)和连续表示(视觉预测)来增强机器人策略学习
- 旨在解决现有 VLA 模型的局限性:基于 VLM 的方法缺乏动态建模能力,而基于生成模型的方法缺乏语义理解能力
- 核心目标是通过大规模预训练(超过 100 万条互联网规模的指令操作视频)学习高维视觉特征的动态建模,然后通过机器人具体数据微调,学习从预测表示…
Card 01
研究单位
研究单位
- 清华大学交叉信息研究院 (Institute for Interdisciplinary Information Sciences, Tsinghua University)
- 上海期智研究院 (Shanghai Qizhi Institute)
- 北京大学 (Peking University)
- 上海人工智能实验室 (Shanghai AI Lab)
Card 02
论文概述
论文概述
- 论文提出 UniCoD,一个统一的视觉-语言-动作(VLA)框架,通过结合离散表示(语言理解)和连续表示(视觉预测)来增强机器人策略学习
- 旨在解决现有 VLA 模型的局限性:基于 VLM 的方法缺乏动态建模能力,而基于生成模型的方法缺乏语义理解能力
- 核心目标是通过大规模预训练(超过 100 万条互联网规模的指令操作视频)学习高维视觉特征的动态建模,然后通过机器人具体数据微调,学习从预测表示到动作令牌的映射
Card 03
核心贡献
核心贡献
- 提出一种新型 VLA 模型,集成离散和连续表示用于理解和学习动态世界模型,在大规模机器人及人类演示数据上进行预训练,实现有效的具身任务迁移
- 提出两阶段训练框架,在保持对齐的中间表示的同时对齐动作表示
- 采用 MoT(Mixture-of-Transformers)架构处理文本理解和规划、连续视觉预测及动作执行
- 在模拟环境和真实世界分布外任务中均实现 9% 和 12% 的性能提升
Card 04
方法描述
方法描述
- 第一阶段(联合视觉-语言嵌入学习):使用 TI2E(Text-Image to Embedding)任务,在机器人视频、人类演示视频和通用 VQA 数据上进行预训练,离散分支使用交叉熵损失,连续分支使用 MSE 损失
- 第二阶段(统一动作建模):引入动作专家和状态专家,使用 Flow Matching 建模动作分布,同时继续预测未来视觉状态
- 采用 PaliGemma 作为 VLM 专家,使用 SigLIP 进行连续视觉特征编码
- 使用 Mixture-of-Transformers 架构,在模态内使用双向注意力,跨模态使用因果掩码
Card 05
数据集与资源
数据集与资源
- 预训练数据:32 万条机器人视频(带细粒度子任务描述)、87 万条机器人和人类操作视频(带任务指令)、56 万条通用视觉-语言问答数据
- 微调数据:模拟环境和真实机器人环境收集的 VLA 数据
- 模拟基准:Calvin(ABC-D 分割)、SimplerEnv(WindowX 和 Google Robot)
- 真实机器人:Franka Emika Panda 臂(7-DoF,2000 条轨迹)和 XArm + 12-DoF X-Hand(4000 条轨迹)
- 训练资源:8 张 A100 GPU,22k 步微调,batch size 1024,学习率 5×10⁻⁵
Card 06
评估与结果
评估与结果
- SimplerEnv-WindowX:UniCoD 达到 71.0% 平均成功率,优于 π₀ 的 49.8%
- SimplerEnv-Google Robot:UniCoD 达到 78.4% 平均成功率
- Calvin ABC→D:平均完成序列长度为 4.11,优于 UP-VLA 的 4.08
- 真实世界 Franka Panda:在 Seen 任务上 88% 成功率,Unseen 任务上 80% 成功率,显著优于基线
- 真实世界 XArm:在未见任务上展现出显著的对象和场景泛化优势,能够成功抓取完全未见过的对象