一眼看懂
封面预览
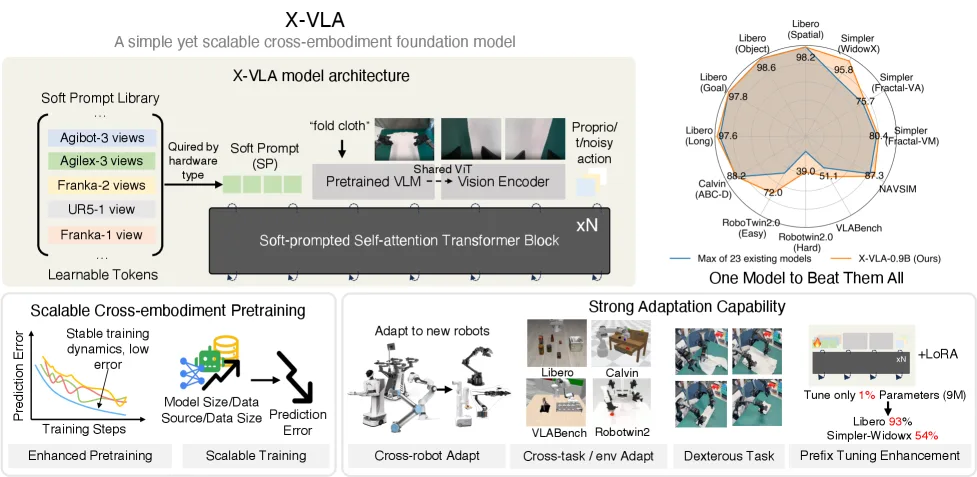
提出 X-VLA,一种基于 Soft Prompt 的可扩展跨本体视觉-语言-动作模型,旨在解决跨本体机器人数据异构性问题
- 提出 X-VLA,一种基于 Soft Prompt 的可扩展跨本体视觉-语言-动作模型,旨在解决跨本体机器人数据异构性问题
- 通过为每个数据源引入可学习的嵌入(soft prompts)作为本体特定提示,使 VLA 模型能够有效利用不同的跨本体特征
- 在 6 个模拟基准(包括自动驾驶基准)和 3 个真实世界机器人平台上同时实现 SOTA 性能
Card 01
研究单位
研究单位
- 清华大学 智能产业研究院 (AIR)
- 上海人工智能实验室 (Shanghai AI Lab)
- 北京大学
Card 02
论文概述
论文概述
- 提出 X-VLA,一种基于 Soft Prompt 的可扩展跨本体视觉-语言-动作模型,旨在解决跨本体机器人数据异构性问题
- 通过为每个数据源引入可学习的嵌入(soft prompts)作为本体特定提示,使 VLA 模型能够有效利用不同的跨本体特征
- 在 6 个模拟基准(包括自动驾驶基准)和 3 个真实世界机器人平台上同时实现 SOTA 性能
Card 03
核心贡献
核心贡献
- 异构软提示学习:引入可学习的 soft prompts 来吸收跨数据源的异构性,无需人工标注即可编码硬件配置
- 简洁架构设计:基于流匹配(flow-matching)的 VLA 框架,仅使用标准 Transformer 编码器,具有良好的可扩展性
- 两阶段训练范式:Phase I 预训练学习本体无关策略,Phase II 领域适配通过新 soft prompts 实现快速部署
- 高效参数微调:使用 LoRA 仅调优 1% 参数(9M)即可达到与全参数微调相当的性能
- 高质量数据集:构建 Soft-Fold 衣物折叠数据集,包含 1,200 条轨迹
Card 04
方法描述
方法描述
- Soft Prompt 机制:为每个数据源分配独立的可学习嵌入,注入到模型早期阶段引导本体感知学习
- 编码管道:使用 Florence-Large 作为 VLM 编码器处理主视觉-语言流,腕部视图使用共享视觉骨干
- 流匹配策略:通过学习速度场将噪声样本传输到目标动作块,使用 OT 路径对齐
- 动作对齐:将动作标准化为末端执行器(EEF)位姿表示(位置 + Rotate6D 旋转 + 夹爪状态)
- 意图抽象:通过时间下采样构建 30 个锚点总结未来 4 秒的意图轨迹
Card 05
数据集与资源
数据集与资源
- 预训练数据:Droid、Robomind、Agibot,跨 7 个平台、5 种机械臂(单臂到双臂)
- 训练数据量:290K episodes
- 模型规模:X-VLA-0.9B(0.9B 参数,隐藏层 1024,24 个 Transformer 块)
- 适配数据:仅需 1,200 条演示即可完成衣物折叠任务
Card 06
评估与结果
评估与结果
- 模拟基准:Libero、Simpler-WidowX、VLABench、RoboTwin-2.0、Calvin、NAVSIM
- 关键结果:
- Simpler-WidowX: 95.8% 成功率
- LIBERO: 98.1% 平均成功率
- Calvin 第一阶段: 97.6% 成功率
- NAVSIM (自动驾驶): 87.3% PDMS
- 真实世界实验:BridgeData-v2 基准上优于所有基线
- PEFT 实验:仅调优 9M 参数(1%),在 Libero 达到 93%,Simpler-WidowX 达到 54%,与 π₀(3B 参数)相当