一眼看懂
封面预览
研究目标: 解决视觉-语言-动作(VLA)模型在具身智能任务中的后训练效率和泛化能力问题,当前方法需要针对每个任务进行独立微调,计算成本高且泛…
- 研究目标: 解决视觉-语言-动作(VLA)模型在具身智能任务中的后训练效率和泛化能力问题,当前方法需要针对每个任务进行独立微调,计算成本高且泛…
- 核心方法: 提出 MetaVLA 框架,采用 Context-Aware Meta Co-Training(上下文感知元协同训练),将多个目标…
- 关键创新: 引入基于 Attentive Neural Processes(ANP)的轻量级元学习模块——Meta-Action-Reason…
Card 01
研究单位
研究单位
- Carnegie Mellon University (CMU): Chen Li, Zhantao Yang, Han Zhang, Fangyi Chen, Anudeepsekhar Bolimera, Marios Savvides
- Meta Reality Labs, USA: Chenchen Zhu
Card 02
论文概述
论文概述
- 研究目标: 解决视觉-语言-动作(VLA)模型在具身智能任务中的后训练效率和泛化能力问题,当前方法需要针对每个任务进行独立微调,计算成本高且泛化性能差
- 核心方法: 提出 MetaVLA 框架,采用 Context-Aware Meta Co-Training(上下文感知元协同训练),将多个目标任务统一到一个微调阶段,同时利用结构多样的辅助任务提升域内泛化能力
- 关键创新: 引入基于 Attentive Neural Processes(ANP)的轻量级元学习模块——Meta-Action-Reasoner(MAR),无需大规模架构改动或推理开销即可实现快速适应
Card 03
核心贡献
核心贡献
- 提出一种后训练方向:通过引入多样化的辅助任务来提升 VLA 模型的泛化能力,同时保持可忽略的优化开销
- 设计 MetaVLA 框架,包含即插即用的模块和训练策略,实现快速、可扩展的适应和强泛化能力,框架与骨干网络和训练管道无关
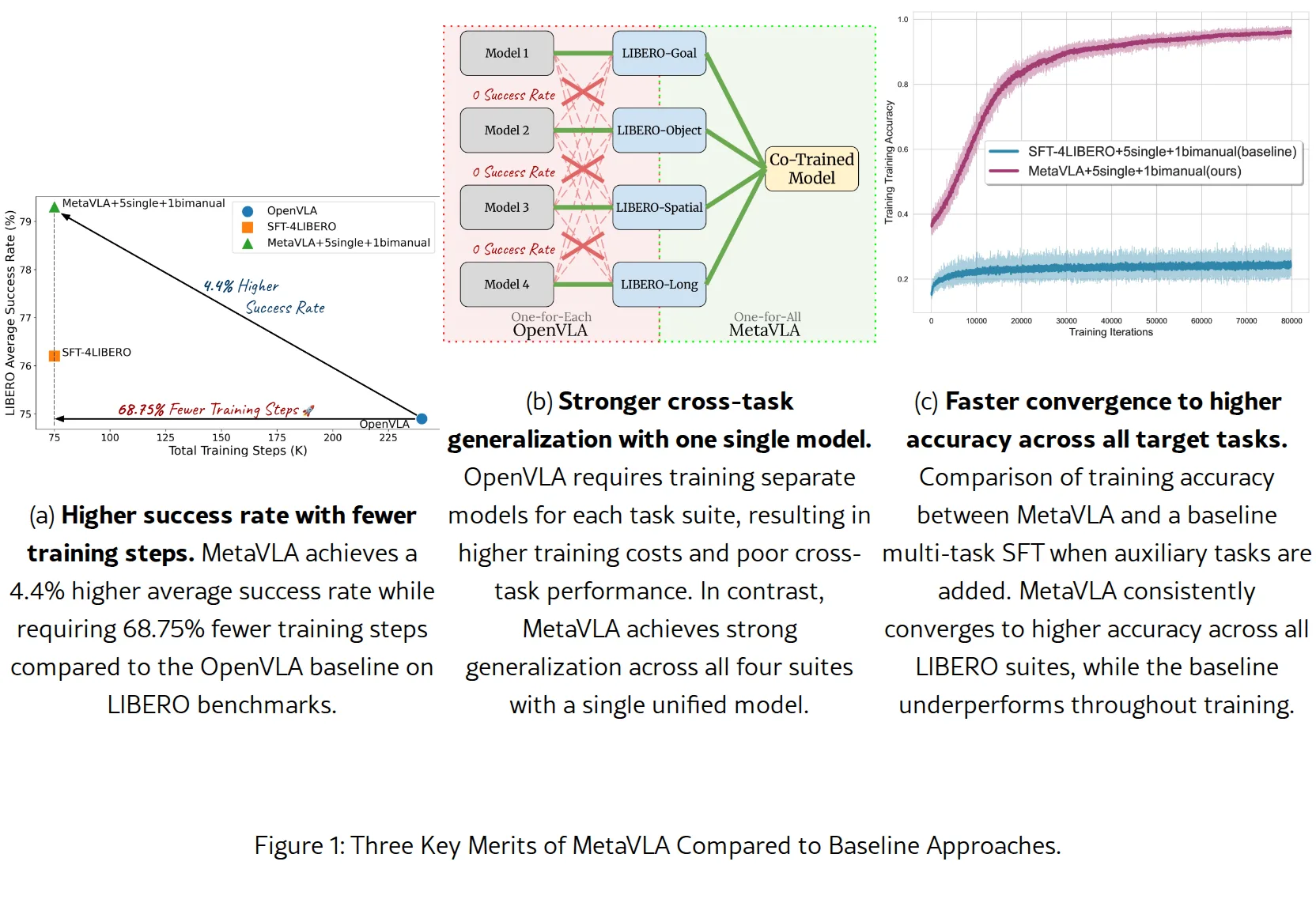
- 在 LIBERO 基准上进行了全面实验,结果表明 MetaVLA 在显著降低训练成本的同时实现了优越性能
- 在 LIBERO-Long 任务上比 OpenVLA 提升 8.0%,平均提升 4.4%
- 训练步骤从 240K 减少到 75K(减少 68.75%),GPU 时间减少 76%
Card 04
方法描述
方法描述
- MAR(Meta-Action-Reasoner)架构: 基于 Attentive Neural Processes,构建对目标动作的条件分布建模,包含自注意力(聚合上下文表示)和交叉注意力(融合目标查询)机制
- 数据银行设计: 包含上下文银行(context bank)和目标银行(target bank);上下文银行由域内任务(4个 LIBERO 套件)和辅助任务(GR00T 数据集)组成,目标银行仅包含域内任务
- 训练协议: 每 K=200 步刷新一次上下文集,从每个上下文任务中随机采样 b_C=32 个示例
- 辅助任务选择: 选择 GR00T 数据集中与 LIBERO 部分相关但结构不同(侧视图、双臂操作等)的任务,增强上下文多样性
Card 05
数据集与资源
数据集与资源
- 基准数据集: LIBERO benchmark(4个任务套件:Goal、Spatial、Object、Long)
- 辅助数据: GR00T 数据集(NVIDIA 的人形机器人数据)
- 骨干网络: OpenVLA(7B 参数)、NORA-Long(3B Qwen2.5-VL 基础)
- 训练资源: 8 张 A100 80GB GPU,训练时间约 24 小时(相比原来约 100 小时)
- 推理开销: 仅增加 0.3 ms/token 的延迟
Card 06
评估与结果
评估与结果
- 评估环境: LIBERO 模拟环境,使用 RTX-4090 GPU 进行评估
- 主要指标: 成功率(Success Rate, SR)
- 关键结果:
- MetaVLA(6个辅助任务)平均成功率 79.3%,比 OpenVLA(4个独立模型)提升 4.4%
- 在 LIBERO-Long 上提升 8.0%,在 LIBERO-Goal 上提升 2.7%
- 单一模型替代四个任务特定模型,训练步骤减少 68.75%
- 在不同骨干网络(NORA-Long)上验证了方法的有效性,平均提升 4.9%-6.4%
- 消融实验验证了上下文批次大小、辅助任务选择、多任务协同训练机制等各组件的贡献