一眼看懂
封面预览
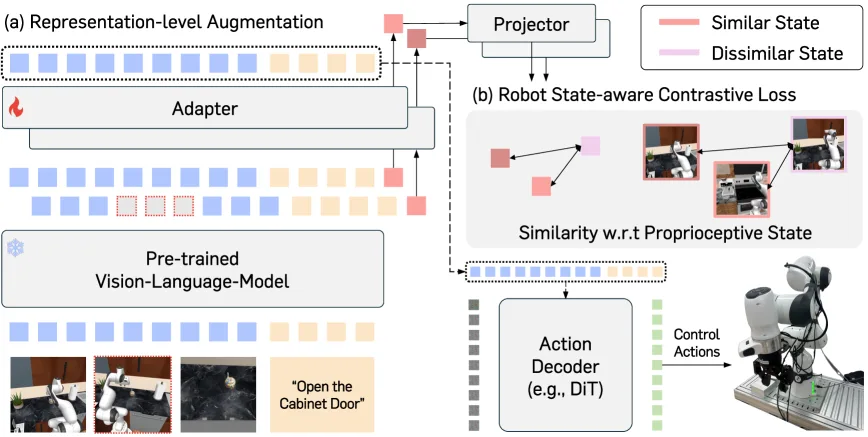
论文提出 Robot State-aware Contrastive Loss (RS-CL),用于解决 VLA(Vision-Languag…
- 论文提出 Robot State-aware Contrastive Loss (RS-CL),用于解决 VLA(Vision-Languag…
- 核心思想是通过对比学习,利用机器人本体感知状态的相对距离作为软监督,使 VLM 表征更好地对齐机器人物理状态
- RS-CL 作为辅助目标与原有动作预测目标(flow-matching loss)联合优化,实现端到端训练
Card 01
研究单位
研究单位
- KAIST(韩国科学技术院)
- UC Berkeley(加州大学伯克利分校)
- RLWRLD
Card 02
论文概述
论文概述
- 论文提出 Robot State-aware Contrastive Loss (RS-CL),用于解决 VLA(Vision-Language-Action)模型中预训练 VLM 表征对机器人信号(如控制动作和本体感知状态)不敏感的问题
- 核心思想是通过对比学习,利用机器人本体感知状态的相对距离作为软监督,使 VLM 表征更好地对齐机器人物理状态
- RS-CL 作为辅助目标与原有动作预测目标(flow-matching loss)联合优化,实现端到端训练
Card 03
核心贡献
核心贡献
- 提出 Robot State-aware Contrastive Loss (RS-CL),一种显式对齐 VLM 表征与本体感知状态的新型目标函数
- 设计了轻量级的表征级增强方法 view cutoff,通过随机掩码某个视角的嵌入来构建对比样本
- 方法保持轻量且完全兼容现有 VLA 训练流程,无需额外训练阶段或精心策划的数据集
- 在 RoboCasa-Kitchen、LIBERO 等多任务操作基准和真实机器人实验中验证了有效性
Card 04
方法描述
方法描述
- 可学习汇总 token:引入可学习向量 appended 到 VLM 输出,经 adapter 处理后生成紧凑的代表性嵌入
- 软权重对比学习:基于本体感知状态的欧氏距离计算样本对的相似性权重,使状态接近的样本在表征空间中更接近
- View cutoff 增强:随机选择一个视角并掩码其对应特征,在表征层面生成多样化的对比样本
- 训练目标:L = L_FM + λ * L_RS-CL,其中 λ 采用余弦 schedule 衰减
Card 05
数据集与资源
数据集与资源
- 数据集:RoboCasa-Kitchen(30/100/300 demos)、LIBERO(spatial/object/goal/long 四类任务)、真实机器人任务(4 个 pick-and-place + 1 个 close-lid)
- 基础模型:GR00T N1.5(基于 Qwen2.5-VL/Eagle 2.5)
- 动作解码器:16 层 DiT,0.5B 参数
- 投影头:2 层 MLP,隐藏维度 2048,投影维度 128
Card 06
评估与结果
评估与结果
- RoboCasa-Kitchen(300 demos):平均成功率从 65.7% 提升至 69.7%(+4.0%)
- Pick-and-place 任务:从 30.3% 提升至 41.5%(+11.2%)
- LIBERO:平均成功率从 95.7% 提升至 96.4%(+0.7%)
- 真实机器人任务:从 45.0% 提升至 58.3%(+13.3%)
- 消融实验:验证了当前状态距离作为软标签优于下一动作距离;view cutoff 优于其他表征增强方法