一眼看懂
封面预览
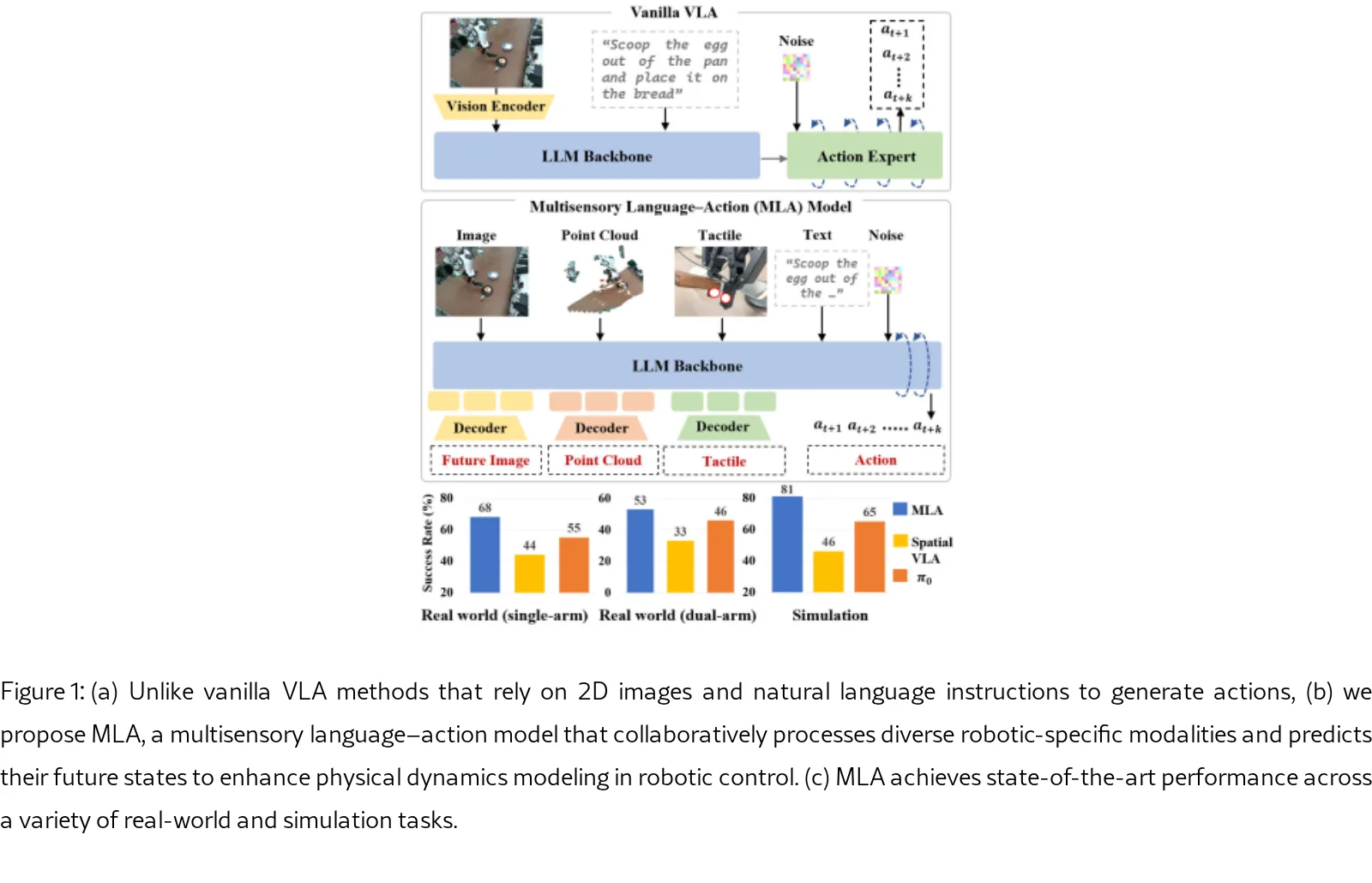
提出了 MLA(多感官语言-动作模型),用于机器人操作中的多模态理解和预测
- 提出了 MLA(多感官语言-动作模型),用于机器人操作中的多模态理解和预测
- 针对现有 VLA(视觉-语言-动作)模型主要依赖 2D 图像的局限性,引入 3D 点云 和 触觉信号 作为额外的感知模态
- 核心目标是实现对物理世界的全面感知,通过预测未来多感官状态来增强动作生成的鲁棒性
Card 01
研究单位
研究单位
- 北京大学 - 多媒体信息处理国家重点实验室,计算机学院
- 北京人形机器人创新中心 (X-Humanoid)
- 香港中文大学 (CUHK)
Card 02
论文概述
论文概述
- 提出了 MLA(多感官语言-动作模型),用于机器人操作中的多模态理解和预测
- 针对现有 VLA(视觉-语言-动作)模型主要依赖 2D 图像的局限性,引入 3D 点云 和 触觉信号 作为额外的感知模态
- 核心目标是实现对物理世界的全面感知,通过预测未来多感官状态来增强动作生成的鲁棒性
- 解决的关键问题:如何在不使用额外编码器的情况下,将异构多模态信息整合到统一的 LLM 表示空间中
Card 03
核心贡献
核心贡献
- 无编码器多模态对齐机制:将 LLM 本身重新用作感知模块,通过位置对应的 token 级对比学习直接对齐图像、点云和触觉token
- 未来多感官生成后训练策略:使模型能够推理语义、几何和交互信息,为动作生成提供更鲁棒的条件
- 三阶段训练范式:大规模预训练 → 监督微调(SFT)+ 跨模态对齐 → 未来状态预测后训练
- 在复杂接触丰富的真实世界任务中达到 SOTA:比 2D VLA 方法 π₀ 提升 12%,比 3D VLA 方法 SpatialVLA 提升 24%
- 跨单臂和双臂操作的强泛化能力
Card 04
方法描述
方法描述
- 模型架构:基于 LLaMA-2 7B 作为骨干网络
- 图像分词器:将图像划分为 14×14 的 patch,生成 256 个 token
- 3D 点云分词器:使用 FPS 采样和 KNN 局部聚合,生成 256 个 token
- 触觉分词器:基于 MLP 的轻量级编码器,生成 1 个 token
- 无编码器多模态对齐:通过相机参数将 3D 点云和触觉位置投影到 2D 图像平面,构建跨模态位置映射作为正样本对
- 未来预测解码器:使用 Transformer 解码器预测未来关键帧的图像、点云和触觉状态
- 动作生成:采用 DDPM 扩散模型生成动作序列
Card 05
数据集与资源
数据集与资源
- 预训练数据:570K 条轨迹,来自 Open-X-Embodiment、DROID 和 RoboMIND 数据集
- 真实世界数据:6 个任务,每个任务 200 条演示(4 个单臂任务 + 2 个双臂任务)
- 硬件配置:Franka Research 3 机械臂,Intel RealSense D455 相机,Tashan TS-E-A 触觉传感器
- 模拟环境:RLBench benchmark
Card 06
评估与结果
评估与结果
- 真实世界实验:在 6 个复杂接触丰富任务上评估,每个任务 15 次 rollout
- 在擦拭白板任务中,MLA 利用触觉感知调节末端执行器的下压力和侧向移动
- 平均成功率比 π₀ 高 12%,比 SpatialVLA 高 24%
- RLBench 模拟基准:10 个任务,每个任务 20 次 rollout
- MLA 达到 81% 平均成功率,显著优于 π₀ (65%)、SpatialVLA (46%) 等基线
- 消融实验:
- 验证了各模态和对齐策略的贡献
- 第 8 层transformer块应用对比学习效果最佳
- 预测关键帧比预测相邻帧效果更好(70% vs 64%)
- 泛化实验:
- 在未见过的物体上:MLA 成功率从 53% 降至 45%(仅下降 15%)
- 在未见过的背景上:MLA 保持 40% 成功率,而 π₀ 降至 25%