一眼看懂
封面预览
PhysiAgent 是一个无需训练的具身智能体框架,旨在实现视觉语言模型 (VLMs) 与视觉语言动作模型 (VLAs) 在物理世界中的无缝…
- PhysiAgent 是一个无需训练的具身智能体框架,旨在实现视觉语言模型 (VLMs) 与视觉语言动作模型 (VLAs) 在物理世界中的无缝…
- 论文指出当前方法通常以刚性、顺序的方式组合 VLMs 和 VLAs,导致协作无效和 grounding 挑战,PhysiAgent 通过引入监…
- 研究目标是在真实世界的机器人平台(桌面操作任务)上验证框架的有效性,展示智能体的自反思能力和显著的任务性能提升
Card 01
研究单位
研究单位
- 清华大学 (Tsinghua University)
- 无锡应用技术研究院 (Wuxi Research Institute of Applied Technologies)
Card 02
论文概述
论文概述
- PhysiAgent 是一个无需训练的具身智能体框架,旨在实现视觉语言模型 (VLMs) 与视觉语言动作模型 (VLAs) 在物理世界中的无缝集成与部署,解决 VLA 模型泛化能力不足的问题
- 论文指出当前方法通常以刚性、顺序的方式组合 VLMs 和 VLAs,导致协作无效和 grounding 挑战,PhysiAgent 通过引入监控、记忆、自反思机制和轻量级工具箱来解决这些问题
- 研究目标是在真实世界的机器人平台(桌面操作任务)上验证框架的有效性,展示智能体的自反思能力和显著的任务性能提升
Card 03
核心贡献
核心贡献
- 提出 PhysiAgent,首个物理世界具身智能体框架,通过统一、自我调节的架构实现 VLMs 与 VLAs 的动态自适应协作
- 将传统仅在语言或模拟领域探索的智能体范式引入物理世界,赋予 VLMs 真实世界感知和工具使用能力
- 在真实世界的机器人操作任务中验证框架,展示了emergent自反思能力和显著的任务性能提升
- 框架具有模块化和即插即用的特性,可广泛应用于各种 VLMs 和 VLAs
Card 04
方法描述
方法描述
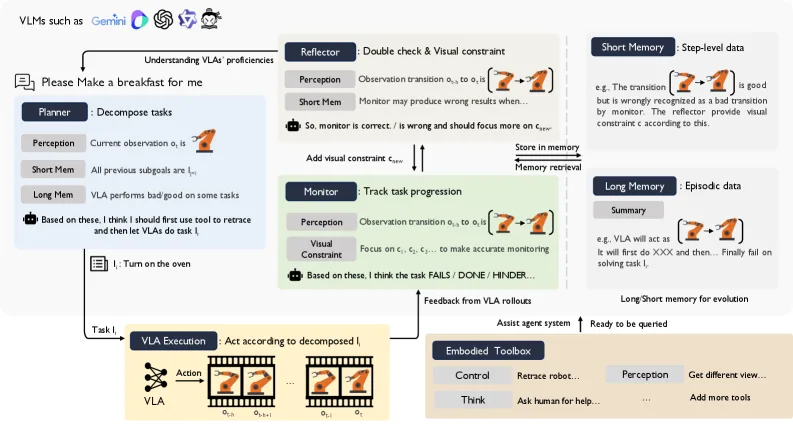
- Planner (规划器): 将高级语言指令分解为可执行的中间指令,传递给低层 VLA 执行
- Monitor (监控器): 使用滑动窗口技术比较连续两帧图像,评估 VLA 执行进度,输出离散进展标志 (Hinder/Ongoing/Failure/Done)
- Reflector (反思器): 作为验证层,交叉检查视觉过渡与预测标志的一致性,生成视觉约束存储到约束缓冲区以指导 Monitor 改进
- Memory (记忆机制): 维护短期记忆(步骤级数据)和长期记忆(每回合的初始/最终帧和文本摘要),支持 Reflector 和 Planner 的能力演进
- Toolbox (工具箱): 提供感知、推理和控制工具,包括多摄像头查询、重规划和回溯等功能
- 信息流是双向的:从 VLMs 到 VLAs,以及从 VLAs 的行为反馈到 VLMs,实现实时适应
Card 05
数据集与资源
数据集与资源
- 数据集: 真实世界桌面操作任务数据集,包含 5 个任务(put broccoli/mushroom/sausage/shrimp/chips on plate),每个任务 150 个人类远程操作演示
- 模型:
- VLM: Gemini 2.0 Flash Lite (Monitor), Gemini 2.0 Flash (Planner & Reflector)
- VLA: RDT-1B (1B 参数) 和 Diffusion Policy
- 硬件平台: AIRBOT 6-DOF 机械臂(带夹爪),3 个 RGB 摄像头(顶视、正面、腕部)
- 训练资源:
- Diffusion Policy: 4 张 NVIDIA A800 GPU,训练 27 小时,120 万步,batch size 64
- RDT-1B: 8 张 A800 GPU,训练 20 小时,5 万步,batch size 64
Card 06
评估与结果
评估与结果
- 评估环境: 真实世界桌面操作平台,三级复杂度的任务(grab foods with dietary fiber/protein and fat, cook a meal)
- 评估指标: 累积任务进度(Y轴)vs VLA 执行步骤(X轴),任务分解为 2-5 个离散子任务
- 主要结果:
- PhysiAgent 在三个任务上成功完成几乎所有阶段,表现出高效率
- 显著优于 vanilla VLA 模型(直接预测动作无高级推理)和层次化方法(静态规划器无法自主跟踪进度)
- 即使在低层策略性能不佳时仍显示鲁棒性,能执行复杂未见过的任务
- 人类在环的层次化方法虽能完成任务,但因高层规划器与低层 VLA 交互不足,性能仍落后于 PhysiAgent