一眼看懂
封面预览
提出 Bi-VLA(Bilateral Control-Based Imitation Learning via Vision-Languag…
- 提出 Bi-VLA(Bilateral Control-Based Imitation Learning via Vision-Languag…
- 解决先前双侧控制模仿学习方法(如 Bi-ACT)仅限于单任务执行的问题,通过视觉-语言融合实现灵活的任务切换
- 在两种真实机器人任务上进行验证:语言消歧任务(Two-Target Task)和视觉消歧任务(Two-Source Task),证明 Bi-V…
Card 01
研究单位
研究单位
- D3 Center, The University of Osaka
- Graduate School of Information Science and Technology, The University of Osaka
- Graduate School of Maritime Sciences, Kobe University
Card 02
论文概述
论文概述
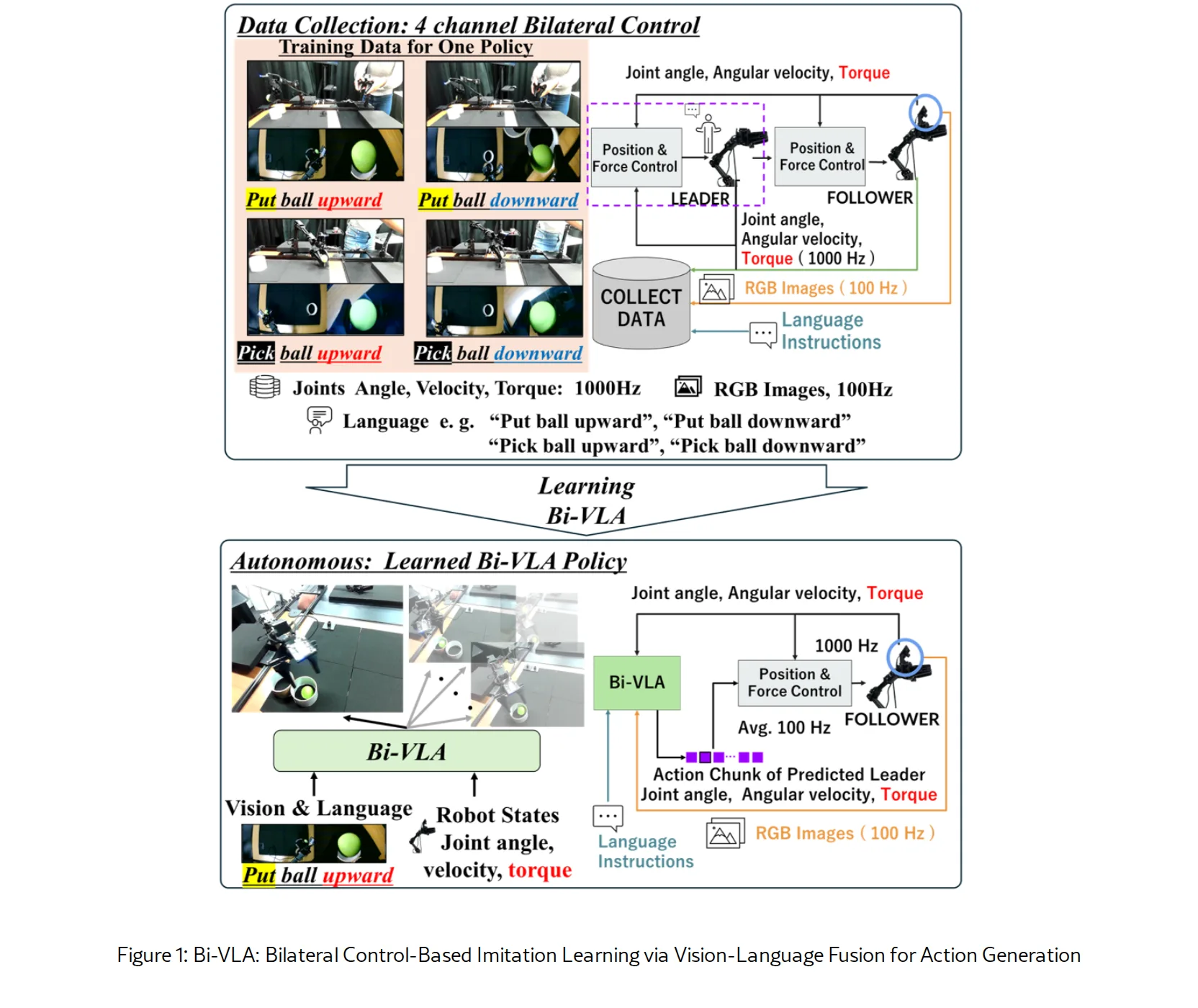
- 提出 Bi-VLA(Bilateral Control-Based Imitation Learning via Vision-Language Fusion),将双侧控制(bilateral control)的位置和力信息与视觉和语言模态融合,实现单一模型执行多任务
- 解决先前双侧控制模仿学习方法(如 Bi-ACT)仅限于单任务执行的问题,通过视觉-语言融合实现灵活的任务切换
- 在两种真实机器人任务上进行验证:语言消歧任务(Two-Target Task)和视觉消歧任务(Two-Source Task),证明 Bi-VLA 能有效结合视觉和语言信息提升任务成功率
Card 03
核心贡献
核心贡献
- 提出 Bi-VLA 框架,首次将视觉和语言特征融合到双侧控制模仿学习中,实现多任务统一建模
- 证明单一模型可通过视觉-语言融合克服先前双侧控制方法的单任务限制,无需针对每个任务单独训练模型
- 验证 SigLIP 语言编码器相比 DistilBERT 能实现更准确的指令对齐和任务执行
- 开发多任务训练策略(Bi-VLA SigLIP-Mix),仅用 4 个原始演示即可实现跨任务泛化
Card 04
方法描述
方法描述
- 数据收集:采用四通道双侧控制系统,leader 和 follower 机器人交换位置和扭矩信息,使用 DOB 和 RFOB 估计外部扭矩
- 模型架构:基于 Transformer 的条件变分自编码器(CVAE),接收多模态输入(关节角度/速度/扭矩、RGB 图像、自然语言指令)
- 视觉-语言融合:使用 EfficientNet 提取视觉特征,使用 SigLIP 编码语言指令,通过 FiLM(Feature-wise Linear Modulation)进行特征融合
- 推理过程:模型根据当前 follower 状态、相机图像和语言指令预测 leader 机器人动作块(角度、速度、扭矩),实现闭环执行
Card 05
数据集与资源
数据集与资源
- 数据集:Two-Target 任务(6 个演示:3 Up, 3 Down)和 Two-Source 任务(6 个演示),使用 DABI 数据增强方法将演示从 6 个扩展到 60 个
- 机器人硬件:OpenManipulator-X(ROBOTIS),4 个旋转关节 + 1 个夹爪关节,双机器人配置(leader + follower)
- 视觉输入:两个 RGB 相机(ELP USBFHD08S-L36,640×360 分辨率),分别安装在天花板和夹爪上
- 训练配置:四通道双侧控制频率 1000 Hz,图像采集频率 100 Hz,模型配置 4 层 encoder、7 层 decoder
Card 06
评估与结果
评估与结果
- Two-Target 任务(语言消歧):Bi-VLA (SigLIP) 达到 90% 总体成功率,Bi-VLA (DistilBERT) 为 60%,Bi-ACT 仅为 50%
- Two-Source 任务(视觉消歧):Bi-VLA (SigLIP) 达到 90% 总体成功率,与 Bi-ACT 的 95% 相当,证明语言融合在纯视觉任务中不会产生负面干扰
- 未学习 3-球环境:Bi-VLA (SigLIP-Mix) 达到 75% 总体成功率,展现多任务泛化能力
- 关键发现:SigLIP 相比 DistilBERT 提供更准确的语言对齐;Bi-VLA (SigLIP-Mix) 仅用 4 个原始演示即可实现多任务学习