一眼看懂
封面预览
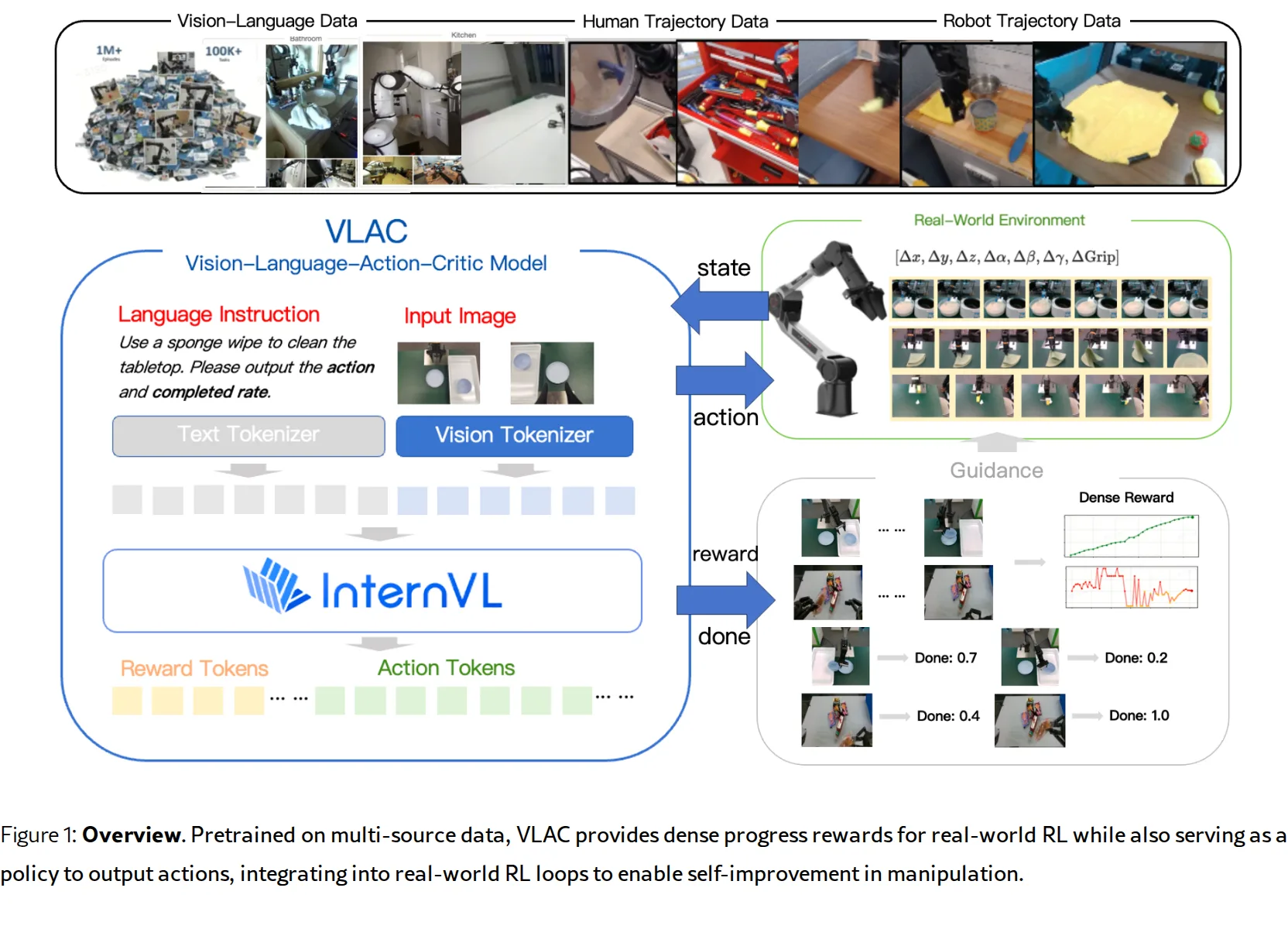
提出 VLAC(Vision-Language-Action-Critic) 模型,一个基于 InternVL 的统一架构,同时作为策略(ac…
- 提出 VLAC(Vision-Language-Action-Critic) 模型,一个基于 InternVL 的统一架构,同时作为策略(ac…
- 解决现有 VLA 模型在真实世界 RL 中的瓶颈问题:稀疏的手工设计奖励、低效探索以及任务特定的奖励工程需求
- 通过成对图像观察和语言目标输入,输出密集的进度变化(progress delta)和完成信号(done signal),实现跨任务、跨场景的零…
Card 01
研究单位
研究单位
- Shanghai AI Lab(上海人工智能实验室)
Card 02
论文概述
论文概述
- 提出 VLAC(Vision-Language-Action-Critic) 模型,一个基于 InternVL 的统一架构,同时作为策略(actor)和评判器(critic),用于机器人真实世界强化学习
- 解决现有 VLA 模型在真实世界 RL 中的瓶颈问题:稀疏的手工设计奖励、低效探索以及任务特定的奖励工程需求
- 通过成对图像观察和语言目标输入,输出密集的进度变化(progress delta)和完成信号(done signal),实现跨任务、跨场景的零样本和上下文迁移
Card 03
核心贡献
核心贡献
- 统一的 VLAC 架构:单个自回归模型通过提示控制交替生成奖励标记和动作标记,实现 critic 和 policy 的统一
- 成对进度理解机制:基于时间顺序的成对图像比较学习细粒度任务进度,支持正负样本平衡和语义不匹配检测
- 大规模异构数据训练:整合 4000+ 小时语言标注操作数据(包括人类视频、机器人轨迹、VQA 数据集),增强感知、推理和动作生成能力
- 真实世界 RL 框架:异步推理基础设施、基于 PPO 的策略优化,以及三级人机协同机制(离线演示回放、返回探索、人工引导探索)
- 强大的泛化能力:在未见过的任务、环境和机器人上实现单样本上下文迁移,零样本评估中 VOC-F1 达到 0.95(RT1 数据集)
Card 04
方法描述
方法描述
- 基础架构:基于 InternVL-8B/2B 的多模态大模型,采用自回归生成方式
- Critic 学习(VLAC):输入成对图像 $(o_i, o_{i+\Delta t})$ 和任务描述 $l_{\text{task}}$,输出进度变化 $c_{i,i+\Delta t} = \Delta t/(T-i)$,同时预测任务完成信号 $l_{\text{done}}$ 和任务描述
- Action 学习(VLAC):将动作表示为末端执行器位姿变化(delta EEF pose),以结构化数字字符串形式自回归生成,支持多视角观察和动作历史
- 数据构建策略:成对图像差异过滤、联合采样(前向/后向/单步/全局)、任务完成判断联合采样、跨任务描述采样(5% 语义不匹配负样本)
- 上下文学习:通过参考轨迹 $O_{\text{ref}}$ 和起始点 $o_0$ 实现单样本迁移
- RL 基础设施:动态 GPU 推理服务器分配(延迟 < 0.1s)、异步执行、Ray 分布式框架、ZeroMQ 通信
- PPO 优化:结构化动作模板生成、价值头(value head)估计状态价值、GAE 计算优势函数、熵正则化鼓励探索
- 人机协同:三级干预策略——(1) 离线专家演示回放(NLL 损失),(2) 针对性重置探索,(3) 人工引导探索
Card 05
数据集与资源
数据集与资源
- 训练数据总量:4000 万样本(部分多轮对话),包括:
- 3000+ 小时人类操作数据(Ego4D HOD)
- 1200 小时公开机器人操作数据(Bridge, Droid, AGIBOT, FMB, RoboSet 等)
- 15+ 小时自采集数据
- VQA 数据集(LLaVA, SpatialQA, RobotVQA, Spot the diff, InstructPix2Pix)
- 模型规模:VLAC-8B(评判器/奖励模型)、VLAC-2B(策略模型)
- 训练资源:GPU 服务器,预训练 batch size 3200,最大学习率 8e-4
- 真实世界部署:AGILE PiPER 机械臂,7-DOF 末端执行器控制,前视相机 + 机器人状态观察
Card 06
评估与结果
评估与结果
- 评估数据集:Bridge, Droid(分布内);RT1, RoboNet, Dobb-E, RH20T, EgoDex, RoboFAC(分布外)
- 评估指标:
- VOC(Value-Order Correlation):预测值与时间顺序的秩相关
- VROC(Value-Reversed-Order Correlation):逆序评估稳定性
- VOC-F1:综合 VOC 和 VROC 的调和平均
- NR(Negative Rate):反向过程对比例,反映失败检测能力
- 成功率、任务进度(人工评估)
- 关键实验结果:
- Critic 性能:RT1 数据集零样本 VOC-F1 = 0.87,单样本提升至 0.96;RoboFAC 成功视频 VOC-F1 = 0.89,失败视频仅 0.44,显示强失败区分能力
- Actor 性能:5 项真实世界操作任务平均成功率 82.5%,任务进度 75%,显著优于 π0(49.2% / 27%);光照迁移和场景迁移后仍保持 69.5% 和 73.6% 成功率
- 真实世界 RL:4 项任务中,VLAC 在 200 个真实交互回合内将成功率从约 30% 提升至约 90%;引入人机协同后样本效率提升约 50%,最终成功率可达 100%