一眼看懂
封面预览
提出 LightVLA,一种面向视觉-语言-动作(VLA)模型的可微分 token 剪枝框架,旨在解决 VLA 模型在资源受限平台上部署时的高…
- 提出 LightVLA,一种面向视觉-语言-动作(VLA)模型的可微分 token 剪枝框架,旨在解决 VLA 模型在资源受限平台上部署时的高…
- 通过自适应、性能驱动的视觉 token 剪枝,在提升效率的同时改善任务执行性能,打破效率与性能之间的传统权衡关系
- 首次将自适应视觉 token 剪枝应用于 VLA 任务,实现效率与性能的协同优化
Card 01
研究单位
研究单位
- LiAuto Inc.(理想汽车)
- School of Vehicle and Mobility, Tsinghua University(清华大学车辆与运载学院)
- Institute of Computing Technology, Chinese Academy of Sciences(中国科学院计算技术研究所)
Card 02
论文概述
论文概述
- 提出 LightVLA,一种面向视觉-语言-动作(VLA)模型的可微分 token 剪枝框架,旨在解决 VLA 模型在资源受限平台上部署时的高计算复杂度和延迟问题
- 通过自适应、性能驱动的视觉 token 剪枝,在提升效率的同时改善任务执行性能,打破效率与性能之间的传统权衡关系
- 首次将自适应视觉 token 剪枝应用于 VLA 任务,实现效率与性能的协同优化
Card 03
核心贡献
核心贡献
- 实证表明 VLA 模型的性能和效率可以协同优化,而非传统认知中的权衡关系
- 提出 LightVLA,一种无额外可训练参数的性能驱动可微分视觉 token 剪枝框架
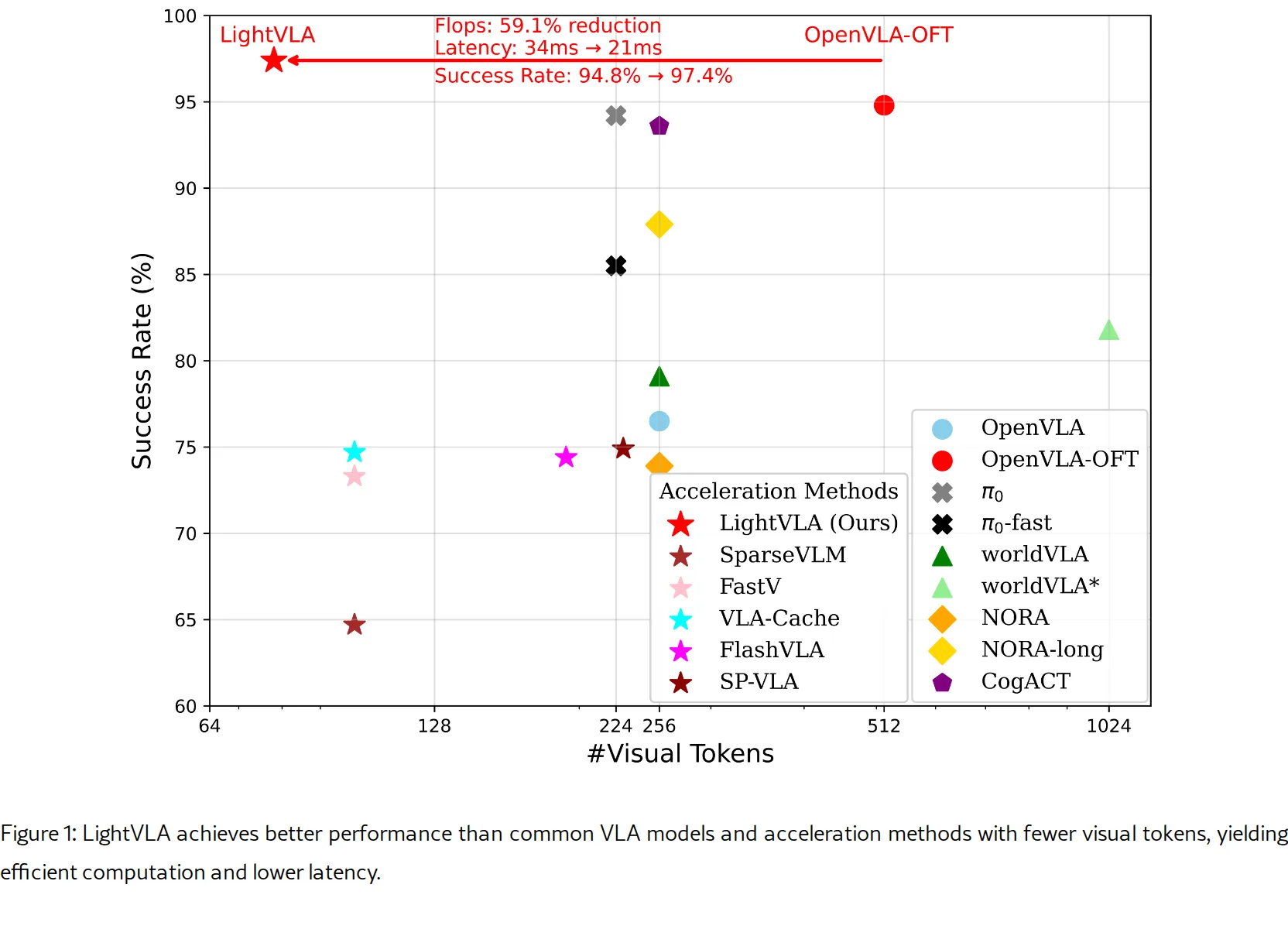
- 在 LIBERO 基准上取得最优性能,相比基线模型 OpenVLA-OFT 减少 59.1% FLOPs 和 38.2% 延迟,同时提升 2.6% 任务成功率
- 提出 LightVLA* 变体,探索基于可学习查询的 token 剪枝方法,同样取得优异性能
Card 04
方法描述
方法描述
- 查询生成:通过视觉 token 与语言指令 token 的交叉注意力动态生成查询,无需额外参数
- Token 评分:每个查询对所有视觉 token 进行重要性评分
- Token 选择:采用 Gumbel-softmax 技术实现可微分的 token 选择,支持端到端训练
- 噪声调度策略:训练过程中逐渐降低采样噪声强度,早期鼓励多样化探索,后期促进稳定收敛
- 保留 [CLS] token 以维持全局视觉信息,仅对 patch 级视觉 token 进行剪枝
Card 05
数据集与资源
数据集与资源
- 数据集:LIBERO 基准(包含 LIBERO-Spatial、LIBERO-Object、LIBERO-Goal、LIBERO-Long 四个任务套件,共 40 个任务,500 条专家演示)
- 基础模型:OpenVLA-OFT(7B 参数,基于 PrismaticVLM 视觉编码器、LLaMA-2-7B 语言模型骨干)
- 训练资源:8 张 NVIDIA H20 GPU
- 优化设置:LoRA 微调(rank=32),40,000 梯度步,学习率 5e-4 降至 5e-5,全局 batch size 64
Card 06
评估与结果
评估与结果
- 评估基准:LIBERO 基准的四个任务套件,每个套件 500 次试验
- 主要指标:任务成功率(Success Rate, %)、保留视觉 token 数量、TFLOPs、端到端延迟(ms)
- 关键结果:
- 平均仅保留 78 个 token(相比原始 512 个 token,减少约 85%)
- 平均成功率达 97.4%,超越所有对比基线
- 计算成本降至 3.6 TFLOPs(基线 8.8 TFLOPs),延迟降至 21 ms(基线 34 ms)
- 定性可视化显示保留 token 集中于任务相关物体(如摩卡壶、炉灶),背景 token 被有效剪除